
面板資料分析步驟及流程-R語言
面板資料
面板資料(Panel Data),也成平行資料,具有時間序列和截面兩個維度,整個表格排列起來像是一個面板。
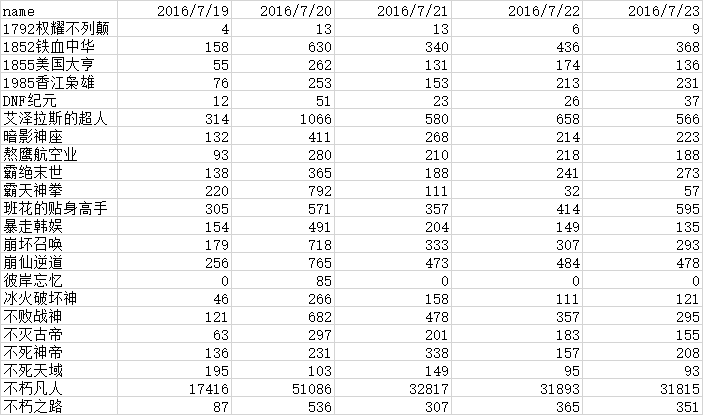
面板資料舉例:
模型說明及分析步驟
1、首先確定解釋變數和因變數;
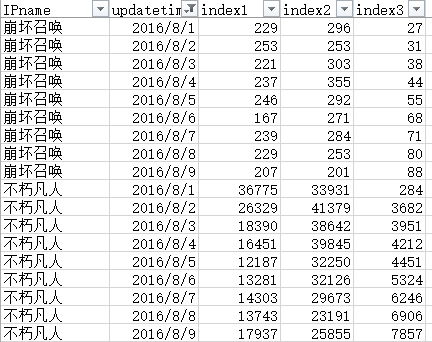
2、R語言操作資料格式,部分截圖如下,這裡以index3為因變數,index1與index2為解釋變數:
##載入相關包
install.packages("mice")##缺失值處理
install.packages("plm")
install.packages("MSBVAR")
library(plm)
library(MSBVAR)
library(tseries)
library 2、單位根檢驗:資料平穩性
為避免偽迴歸,確保結果的有效性,需對資料進行平穩性判斷。何為平穩,一般認為時間序列提出時間趨勢和不變均值(截距)後,剩餘序列為白噪聲序列即零均值、同方差。常用的單位根檢驗的辦法有LLC檢驗和不同單位根的Fisher-ADF檢驗,若兩種檢驗均拒絕存在單位根的原假設則認為序列為平穩的,反之不平穩(對於水平序列,若非平穩,則對序列進行一階差分,再進行後續檢驗,若仍存在單位根,則繼續進行高階差分,直至平穩,I(0)即為零階單整,I(N)為N階單整)。
##單位根檢驗
tlist1<-xts(data$index1,as.Date(data$updatetime))
adf.test(tlist1)
tlist2<-xts(data$index2,as.Date(data$updatetime))
adf.test(tlist2)3、協整檢驗/模型修正
單位根檢驗之後,變數間是同階單整,可進行協整檢驗,協整檢驗是用來考察變數間的長期均衡關係的方法。若通過協整檢驗,則說明變數間存在長期穩定的均衡關係,方程迴歸殘差是平穩的,可進行迴歸。
格蘭傑因果檢驗:前提是變數間同階協整,通過條件概率用以判斷變數間因果關係。
##格蘭傑因果檢驗 4、模型選擇
面板資料模型的基本形式
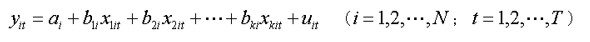
也可寫成:
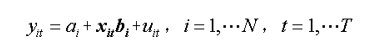
其中:



對於平衡的面板資料,即在每一個截面單元上具有相同個數的觀測值,模型樣本觀測資料的總數等於NT。
當N=1且T很大時,就是所熟悉的時間序列資料;當T=1而N很大時,就只有截面資料。
- 模型選擇一般有三種形式
(1)無個體影響的不變係數模型(混合估計模型):ai=aj=a,bi=bj=b
即模型在橫截面上無個體影響、無結構變化,可將模型簡單地視為是橫截面資料堆積的模型。這種模型與一般的迴歸模型無本質區別,只要隨機擾動項服從經典基本假設條件,就可以採用OLS法進行估計(共有k+1個引數需要估計),該模型也被稱為聯合迴歸模型(pooled regression model)。
(2)變截距模型(固定效用模型):ai≠aj,bi=bj=b
即模型在橫截面上存在個體影響,不存在結構性的變化,即解釋變數的結構引數在不同橫截面上是相同的,不同的只是截距項,個體影響可以用截距項ai (i=1,2,…,N)的差別來說明,故通常把它稱為變截距模型。
(3)變係數模型(隨機效應模型):ai≠aj,bi≠bj
即模型在橫截面上存在個體影響,又存在結構變化,即在允許個體影響由變化的截距項ai (i=1,2,…,N)來說明的同時還允許係數向量bi (i=1,2,…,N)依個體成員的不同而變化,用以說明個體成員之間的結構變化。我們稱該模型為變係數模型。 - 選擇合適的面板模型
需要檢驗被解釋變數yit的引數ai和bi是否對所有個體樣本點和時間都是常數,即檢驗樣本資料究竟屬於上述3種情況的哪一種面板資料模型形式,從而避免模型設定的偏差,改進引數估計的有效性。
如果接受假設H2,則可以認為樣本資料符合不變截距、不變係數模型。如果拒絕假設H2,則需檢驗假設H1。如果接受H1,則認為樣本資料符合變截距、不變係數模型;反之,則認為樣本資料符合變係數模型。 - F檢驗
具體計算過程略,見參考ppt。
其中下標1,s1指代隨機效應模型的殘差平方和,s2指代固定效用模型殘差平方和,s3指代混合估計模型的殘差平方和;
若F2統計量的值小於給定顯著水平下的相應臨界值,即F2小於Fa,則接受H2,認為樣本資料符合混合效應模型;反之,則繼續檢驗假設H1;
若F1統計量的值小於給定顯著水平下的相應臨界值,即F1小於Fa,則接受H1,認為樣本資料符合固定效應模型;反之,則認為樣本資料符合隨機效應模型; - 隨機效應模型
(1)1.LM檢驗。Breush和Pagan於1980年提出R 檢驗方法。
其檢驗原假設和備擇假設:
如果不否定原假設,就意味著沒有隨機效應,應當採用固定效應模型。
(2). 豪斯曼(Hausman)檢驗。William H Greene於1997年提出了一種檢驗方法,稱為豪斯曼(Hausman)檢驗。
若統計量大於給定顯著水平下臨界值,p值小於給定顯著水平,則存在個體固定效應,應建立個體固定效應模型。
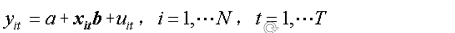
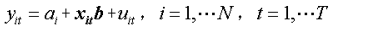
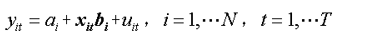


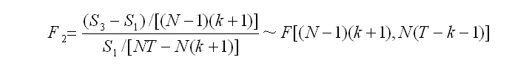
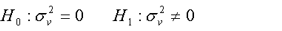

form<- index3~index1+ index2
rankData<-plm.data(data,index=c("IPname","updatetime"))#轉化為面板資料
pool <- plm(form,data=rankData,model="pooling")#混合模型
pooltest(form,data=rankData,effect="individual",model="within")#檢驗個體間是否有差異
pooltest(form,data=rankData,effect="time",model="within")#檢驗不同時間是否有差異
wi<-plm(form,data=rankData,effect="twoways",model="within")#存在兩種效應的固定效應模型
pooltest(pool,wi)#F檢驗判斷混合模型與固定效應模型比較
phtest(form,data=rankData)##Hausman檢驗判斷應該採用何種模型,隨機效應模型檢驗
pbgtest(form,data=rankData,model="within")#LM檢驗,隨機效應模型檢驗
#檢驗是否存在序列相關
pwartest(form,data=rankData)#Wooldridge檢驗(自相關)小於0.05存在序列相關
summary(wi)##檢視擬合模型資訊
fixef(wi,effect="time")#不同時間對因變數的影響程度的係數估計值
inter<-fixef(wi,effect="individual")#不同個體對因變數的影響程度的截距估計值
##根據模型引數,進行預測;注:有些地方,尤其R程式碼部分有些亂,需根據實際資料情況進行選擇,函式的引數設定並未完全吃透,還需要繼續學習,如有不對的地方,再改正,目前的理解是這樣了,在本次資料場景中,實際資料應用中預測效果不是很好,誤差稍大,這次未採用,以後遇到可以再嘗試。