
使用WireShark分析HTTP協議時幾種常見的漢字編碼
在使用WireShark分析HTTP協議的過程中,我們自然是首先要完成解密(若是使用了SSL)、重組(若是使用了chunked分段編碼)、解壓(若是使用了壓縮編碼)【幸運的是,除了加解密,這一系列的工作都已經在Wireshark1.8以後的版本中得到了支援】 ,得到一個基本可直接識別的HTTP報文。但此時的報文中還是會有一些部分內容,他們有著固定地格式,表面看起來也是ASCII字元,但是實際表達的意思卻不能直接看得出來。這些不能直接識別的部分,很多是經過某種編碼變換的中文字串。本文要介紹的正是一些我曾經遇到並糾結過的漢字編碼。
一、URL編碼
編碼例項:%E5%9B%9B%E5%B7%9D%E5%A4%A7%E5%AD%A6
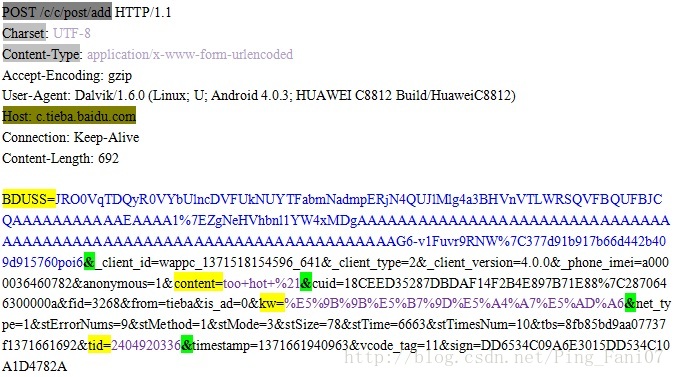
圖1 使用百度貼吧客戶端發表回覆時的HTTP請求示例
常見位置:HTTP請求行中的URI(可能是請求靜態網頁時的中文路徑、或是請求動態網頁時的中文查詢字串)
HTTP請求正文中(當請求報文頭部Content-Type頭域的值為application/x-www-form-urlencoded時,如圖1)
格式特點:以%開始,後面緊跟兩個16進位制數
編碼解碼:
這種編碼方式由於最初用於使URL符合RFC 1738規範【RFC 1738中規定: “只有字母和數字[0-9,a-z,A-Z]、一些特殊符號“$-_.+!*'(),”[不包括雙引號]、以及某些保留字,才可以不經過編碼直接用於URL。”】而被稱為URL編碼,應該算是HTTP請求報文中最常見的編碼了。
URL編碼的過程很簡單,如下:
- 將待編碼字元原先的儲存編碼看成一個16進位制流【將原2進位制流按 位元組拆分,每個位元組都用2位16進位制數表示】;
- 在每兩位16進位制數(即一個完整的位元組)前加一個%,得到最終編碼結果;
對於漢字來說,首先要看其本身儲存時所使用的編碼是UTF-8還是GB2312。同樣的漢字,儲存編碼不同,經URL編碼後的結果自然也不同。例如“川”,使用UTF-8編碼儲存時為e5b79d,經URL編碼後則為%e5%b7%9d;使用GB2312編碼儲存時為b4a8,經URL編碼後則為%b4%a8。
解碼的時候也很簡單,將編碼裡的%號去掉,得到一個16進位制流,這個16進位制流轉回2進位制流,得到的就是原字元的儲存編碼。剩下的一個重要問題是怎麼理解這個還原出來的儲存編碼(即原字元使用的儲存編碼方式)?分三種情況:
- 對於HTTP請求正文中的URL編碼,我們可以檢視請求頭部中Charset頭域的值,它指定了請求報文所使用的字符集(即儲存編碼方式)。如圖1,因為Charset的值為UTF-8,所以我們對解碼後的結果就應當按UTF-8編碼理解了;
- 因為使用UTF-8編碼時,一個漢字的本身儲存佔三個位元組;而使用GB2312編碼,一個漢字的本身儲存佔兩個位元組。因此如果我們能確定被編碼的是純漢字流的話,我們可以根據解碼後的結果佔用的位元組數是3或者2的倍數來大致推斷其儲存編碼方式;
- 上述方法都不行的話,就只能在譯碼的時候都試一下了,但建議先試UTF-8。
解碼工具:
百度上一搜一大堆,我經常用的是由九一網路開發的一個URL編碼解碼百度應用,地址是http://app.baidu.com/app/enter?appid=117335,用起來還比較方便。
二、Unicode編碼【網上工具多稱為UTF-8編碼】
編碼例項:\u6d6e\u751f\u82e5\u68a6【下圖中深灰底色標註,意為:浮生若夢】

圖2 使用百度貼吧客戶端檢視“我的關注”時伺服器給出的響應正文示例
常見位置:HTTP響應正文中
格式特點:以\u開始,後面緊跟四個16進位制數
編碼解碼:
這種編碼在網上多被稱為UTF-8編碼,其實是不太準確的。就其編碼過程來看,編碼時首先獲取漢字對應的Unicode碼,然後在Unicode碼的前面加上\u就得到編碼結果。每組由\u隔開的四個16進位制數就對應一個漢字。
相應的,解碼也很簡單,只要挨個提取\u隔開的四個16進位制數,以此作為Unicode編碼值在UNICODE編碼表裡查詢相應漢字即可。
解碼工具:
114啦工具箱有個線上的UTF-8編碼轉換工具【地址是:】可以直接將這種編碼轉為漢字。我以前一直用的這個,但最近這個網站好像抽風了,上面好多工具都用不起了,不曉得啥時候恢復。
當前我用來解此類編碼的是由站長工具提供的UTF-8編碼轉換工具【地址是:】,這個工具以及很多其他類似工具的不好之處在於,他們對格式的要求太死板,如果把前述編碼示例直接輸入是解不出來的,必須先自行將之轉換為形如浮生若梦 【將Unicode編碼值前的\u替換為&#x,並在Unicode編碼值後加上半形分號】的樣式才行。手工解碼過程略嫌麻煩。
三、八進位制顯示編碼
編碼例項:\345\233\233\345\267\235\347\234\201【下圖中淺灰色標註,意為四川省】

圖3 使用百度貼吧客戶端定位時伺服器給出的響應示例
常見位置:HTTP響應正文中
格式特點:以\開始,後面緊跟三個8進位制數
編碼解碼:
這種編碼其實並非是原始資料中實際存在的編碼,它只是WireShark用以顯示非ASCII字元的一種方式,所以我將之稱之為顯示編碼。
如果你有C語言基礎,那應該早就看到過,當然,在C語言的語法講解中,這並不作為一種編碼,而是歸為轉義字元的。
這種我所謂的顯示編碼,其編碼規則類似於URL編碼。他也是將待編碼字元的儲存編碼按位元組拆分,區別在於:
- 拆分後,每個位元組的值用一個三位8進位制數表示【URL編碼中用二位16進位制數表示】;
- 在每3位8進位制數前加上一個反斜杆\【URL編碼中在每2位16進位制數前加上一個百分號%】
解碼的時候,先將每3位8進位制數轉換成8為2進位制數,然後將反斜杆去掉,得到的2進位制流就是原字元的儲存編碼。
解碼工具:
我還沒有找到一個現成的,可以直接用的工具。一個可以偷懶的辦法是,先用一個進位制轉換工具將3位8進位制數轉換為2位16進位制數,再將所有反斜杆替換成百分號,這樣這種編碼就轉成了URL編碼,再利用前文說的URL編碼解碼百度應用,就可以完成手工解碼了。
From:http://blog.csdn.net/howeverpf/article/details/9259835