
spark叢集從HDFS中讀取資料並計算
一、 利用spark從hadoop的hdfs中讀取資料並計算
1.1準備階段
部署好hadoop分散式搭建(+zookeeper,6臺機器)可以參考這篇部落格:http://blog.csdn.net/vinsuan1993/article/details/70155112
|
主機名 |
IP |
安裝的程式 |
執行的程序 |
|
Heres01 |
192.168.2.108 |
jdk、hadoop、zookeeper、spark |
DataNode JournalNode Master QuorumPeerMain NodeManager |
|
Heres02 |
192.168.2.99 |
jdk、hadoop、zookeeper、spark |
DataNode JournalNode Worker QuorumPeerMain NodeManager |
|
Heres03 |
192.168.2.109 |
jdk、hadoop、zookeeper、spark |
DataNode JournalNode Worker QuorumPeerMain NodeManager |
|
Heres04 |
192.168.2.113 |
jdk、hadoop |
ResourceManager |
|
Heres05 |
192.168.2.112 |
jdk、hadoop |
DFSZKFailoverController NameNode |
|
Heres06 |
192.168.2.110 |
jdk、hadoop |
DFSZKFailoverController NameNode |
部署好spark叢集,可以參考這篇部落格:http://blog.csdn.net/vinsuan1993/article/details/75578441
1.2啟動hdfs
1.2.1啟動zookeeper叢集(分別在heres01、heres02、heres03上啟動zk)
cd/heres/zookeeper-3.4.5/bin/
./zkServer.shstart
#檢視狀態:一個leader,兩個follower
./zkServer.shstatus
1.2.2啟動journalnode(在heres01上啟動所有journalnode,注意:是呼叫的hadoop-daemons.sh這個指令碼,注意是複數s的那個指令碼)
cd/heres/hadoop-2.2.0
sbin/hadoop-daemons.shstart journalnode
#執行jps命令檢驗,heres01、heres02、heres03上多了JournalNode程序
1.2.3啟動HDFS(在heres01上執行)
sbin/start-dfs.sh
到此,hadoop2.2.0配置完畢,可以通過瀏覽器訪問:
http://192.168.2.110:50070
NameNode'heres06:9000' (active)
http://192.168.2.112:50070
NameNode 'heres05:9000' (standby)
1.3.啟動spark叢集
/bigdata/spark-1.6.1-bin-hadoop2.6/sbin/start-all.sh
1.4.啟動spark-shell
bin/spark-shell --masterspark://heres01:7077 --executor-memory 512m --total-executor-cores 2
注:“-”前面是沒有空格的,否則會報錯
1.5.上傳檔案到hdfs上
hdfs dfs-mkdir /wc
dfs dfs -ls /
hdfs dfs-put words.txt /wc/1.log
hdfs dfs-put words.txt /wc/2.log
hdfs dfs -put words.txt /wc/3.log
1.6.在spark-shell中編寫spark程式
sc.textFile("hdfs://heres06:9000/wc").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
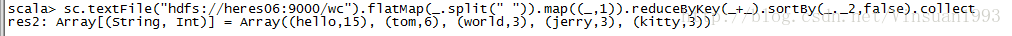
sc.textFile("hdfs://heres06:9000/wc").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile("hdfs://heres06:9000/vinout")
結果會生成三個檔案
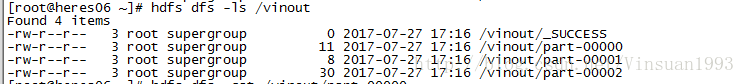
sc.textFile("hdfs://heres06:9000/wc").flatMap(_.split("")).map((_,1)).reduceByKey(_+_,1).sortBy(_._2,false).saveAsTextFile("hdfs://heres06:9000/vinout1")
結果會生成一個檔案
