
網際網路服務端技術——如何學(下B)
今天想跟大夥兒聊聊分散式元件。說到元件,老王當年就覺得是高大上的玩意兒。一聽說誰誰誰在哪個公司,寫某某元件,仰慕之情猶如滔滔江水延綿不絕~後來自己也寫了一些所謂的元件以後,覺得這個並沒有什麼神祕的。所謂元件,老王是這麼理解的:為了一個整體的環境能夠完整的工作,而提供的一些功能相對獨立、目標明確、有可能通用性強一些的函式、類、庫、模組、系統或者服務等等。比如,你寫一個列印的函式,提供給文字編輯的軟體使用,你的函式就可以叫做列印元件;也可以提供一個列印服務給文書處理系統,你的服務也可以叫做列印元件。這是老王的一個理解,不一定全面。
那具體到網際網路分散式體系中,有一些元件是比較通用的,可能會對我們的架構設計起到關鍵作用的。老王今天把他們提出來,專門聊聊。好吧,開始正題
命名服務(Naming Service):
在上一篇,我們講分散式架構的時候(如果沒看過上一篇的盆友,請關注老王的微信:simplemain進行查閱),多次提到他。那他到底是什麼玩意兒呢?大家都知道DNS吧(就是你ping www.baidu.com的時候,把域名變成ip的那玩意兒),命名服務的作用類似,就是把我們內部系統的名字變成ip的服務。那為什麼要有他呢?並且他的作用還那麼重要?嫑急,慢慢往下看~
第一個階段:
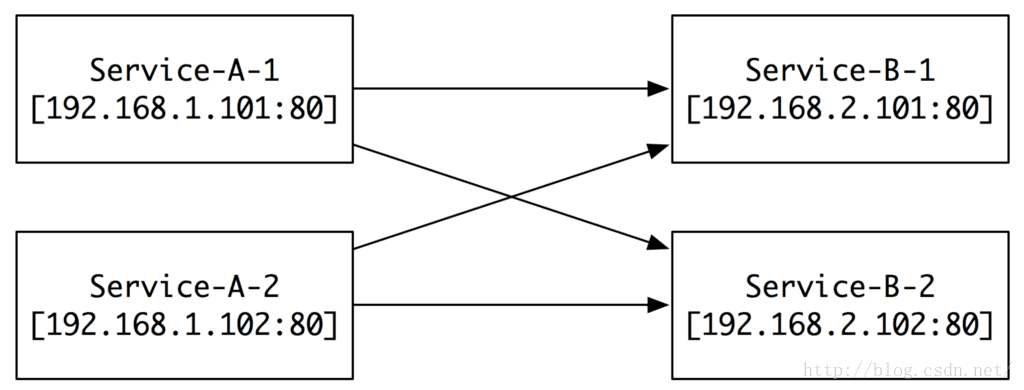
當我們服務還不多,機器也不多的時候,我們有兩個服務,分別叫Service-A(以下簡稱A)和Service-B(以下簡稱B),他們各自有兩臺伺服器,對應不同的ip和埠。當
可是,當我們規模擴大的時候,問題就來了。
第二個階段:
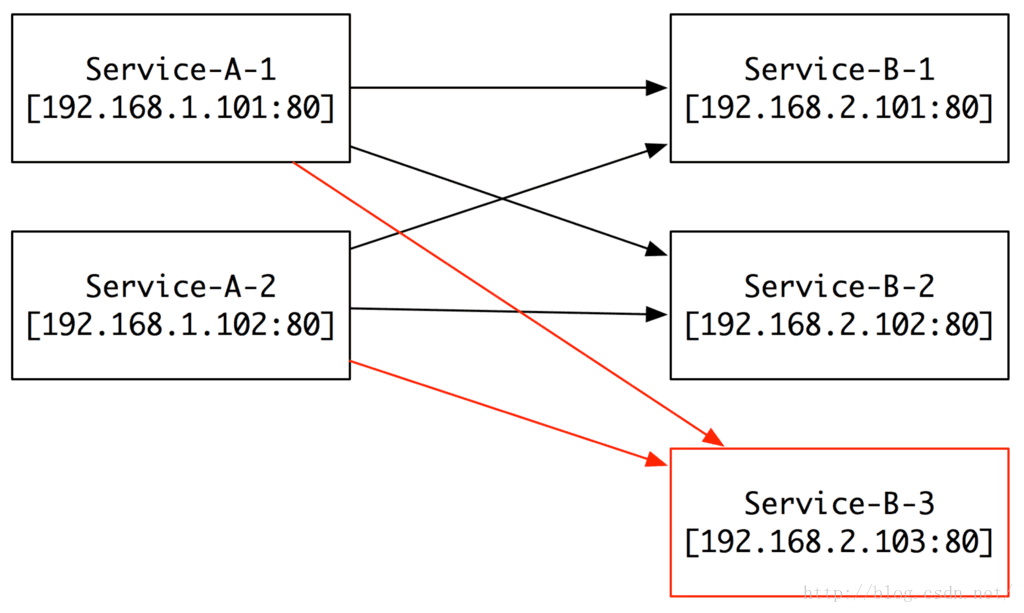
當我規模擴大或者服務壓力增大的時候,我們就需要加機器,比如現在我們加了一臺B的3號伺服器,那我們需要怎麼做呢?先搭建B的3號伺服器,然後把A的所有機器配置B的部分增加一臺3號伺服器的IP和Port。看起來似乎也不是什麼問題,對吧?
如果,我們要增加10臺、100臺B呢?
另外,如果我們新增加了服務C、D、E……,然後每個平均有10臺、100臺伺服器,那我們是不是就要瘋了!
同理,如果我們的伺服器出現問題,要替換、要下線,是不是又要全部去配置一遍?
當年我在百度的時候,公司模組之間的關係圖就是這樣的。要增加或者修改一個模組,與之相關聯的模組全部都需要修改。有時候為了上一個小小的功能,需要驚動N個系統。著實讓人崩潰~後來,回百詞斬以後,算是做的第一件系統性的工作,就是開發上線Naming Service。現在回頭來看,這個決策真是太正確不過了。
那他是怎麼工作的呢?
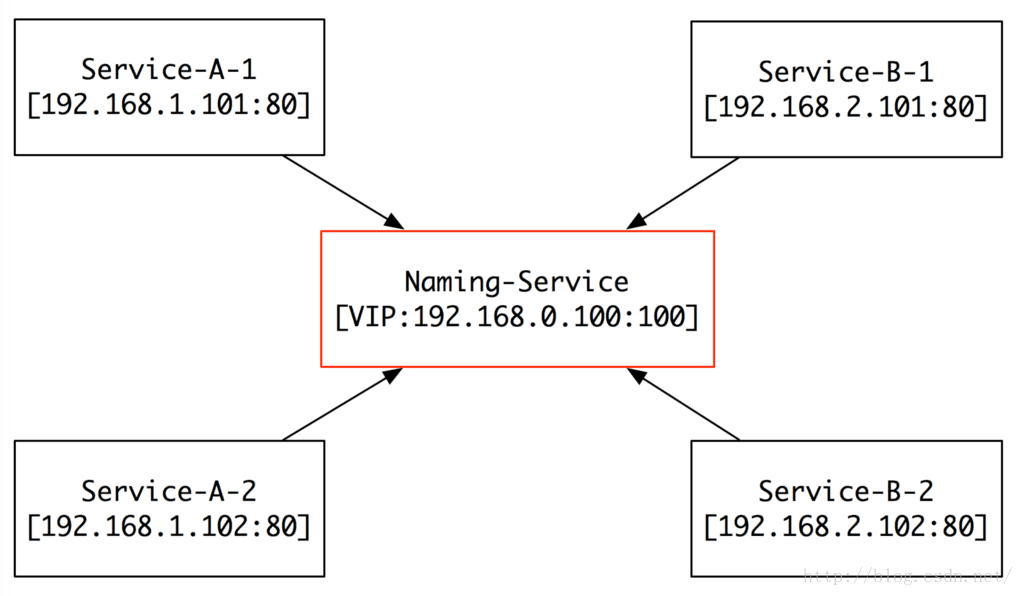
註冊(Register):
所有的服務,都將自己的名字、IP、Port註冊到Naming-Service(以下簡稱NS),然後NS就維護N個佇列:
佇列1:Queue A:
(192.168.1.101:80) -> (192.168.1.102:80)
佇列2:Queue B:
(192.168.2.101:80) -> (192.168.2.102:80)
當有新的機器加入的時候,他們自己將自己註冊到NS,完全不用別人去關心。
查詢(Query):
當A需要請求B的時候,就去問NS:“哥們兒,我想請求B的服務,給我一個他的IP和Port吧”。然後NS就根據負載均衡策略(比如:隨機、一致雜湊等),返回一個可用的IP和Port給A。即使B有新機器加入,A也不用關心,因為有NS這個保姆在。
健康檢查(Healthy Check):
如果有機器壞掉,或者服務crash了,NS會在很短的時間內通過心跳包檢測到服務出現問題了。這時,NS就會把出問題的IP和Port從可用佇列中把他們摘除,以保證佇列中給出去的都是可靠穩定的服務。
好了,有了上面三個功能,命名服務就基本能提供服務了。但是有一個問題,我們的其他服務怎麼找到命名服務呢?我們一般將命名服務放在一個虛擬伺服器(比如LVS)後面,對外提供一個虛擬IP。這樣,各個伺服器只需要配置一個固定IP就可以知道了。如果想穩妥一些,可以配置這樣的一組(比如3個)IP,這樣就可以做到IP的熱備。
NS在我們分散式架構中佔據中心位置,提供的是中心化服務。在一般的體系架構中工作的非常完美。不過對於有些非中心化要求的系統來說(比如:NS內部),這個就是不能接受的,那其實也是有方案的,比如我們會用到Gossip協議,幫我們去掉中心化的設計。在這裡就暫時不詳細講解了,後面找時間專門來講述~
訊息佇列(Message Queue):
當老王第一次接觸訊息佇列的時候,第一反應是,這個是不是給手機推訊息的一個系統?現在回想起來覺得好好笑。這個系統確實可以用來給手機推送訊息,不過他有著更廣泛的應用和意義。
當年在百度的時候,內部有一個系統叫CM-Transfer,就是用來給各個系統傳送資訊的,其實也就是一個訊息佇列。後來老王回了百詞斬,做了另外一個正確的決定,就是寫了一個訊息佇列(以下簡稱MQ),解決了很多大流量或者集中提交的問題,一直享他的福至今。那MQ究竟是一個什麼玩意兒呢?解決什麼樣的問題呢?
第一階段:
當我們服務還不大的時候,使用者的提交可能很小,比如一分鐘就發幾個貼子,那我們直接就可以把資料insert into xxx,毫無壓力。這時候,架構也很簡單,就是邏輯層直接連線資料庫。
如果,這個時候流量突然增加(比如:我們使用者暴增或者有一個秒殺的業務),怎麼辦?那方法有很多,大致如下:
1、做業務和資料切分:把業務切成正交的多個,或者是DB按垂直或者水平做切分;
2、邏輯層做資料快取,定時合併和寫回到資料庫;
3、寫自己專有的儲存系統,替代資料庫;
4、如果不是有強一致性要求,可以引入MQ,將同步提交變成非同步提交。
前三種方式就暫時不在這裡討論了,我們重點看看第四種方式是如何來工作的。
第二階段:
如果寫過c語言的同學都知道,fwrite函式是一個帶緩衝的寫函式,你呼叫他把資料寫進磁碟檔案,這個函式並沒有真正將資料寫入磁碟,他建立了一個buffer,先把資料寫在記憶體,到一定的時候,再寫進磁碟。
(話外音:你以為他給你寫了磁碟,其實沒有,他 -- 欺!騙!了!你!)
他這樣做有他的道理,就是如果你有頻繁大量的寫入操作,他會降低你寫磁碟的頻率,從而提升寫操作的效率。但是也帶來了問題,就是你的資料有可能會丟掉。
那在實際的網際網路server開發工作中,我們其實可以借鑑這樣的思想,當有大量寫入操作的時候,我們就將資料寫入到一個緩衝空間中,然後再由這個緩衝空間,將資料慢慢轉發給真正的writer,讓他來將資料寫入到檔案或者資料庫中。這個緩衝空間就是我們的訊息佇列(MessageQueue)。要寫的資料,可以看出一個個的訊息,放入到這個佇列中。
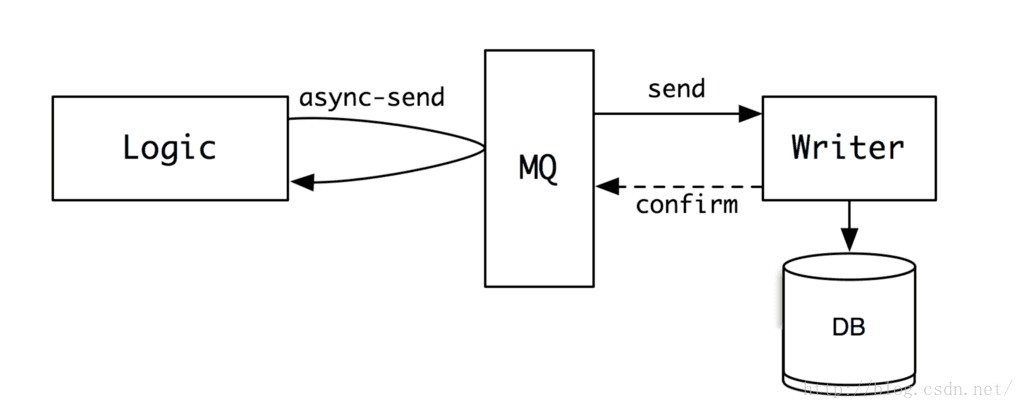
那剛剛說fwrite有一個問題,就是如果程式掛掉了,記憶體中的資料就丟失了。為了避免在MQ中出現類似的問題,MQ一般會做內容的序列化,將收到的訊息,一條條連續的寫入到磁碟,以保證資料的完整性。
那有同學就會問了,既然MQ也是要寫磁碟,原來的儲存也是寫磁碟,那為什麼MQ就能提升效率,解決高併發寫的問題呢?這裡原因大體有兩點:
1、MQ是將訊息順序寫入磁碟,而邏輯寫入操作大部分是隨機寫入磁碟。而對於傳統機械硬碟來講,順序寫的效率遠遠高於隨機寫;即使是現在的ssd,隨機寫的效能也不如傳統機械硬碟的順序寫效能;
2、MQ寫入是完全無邏輯的,基本不消耗cpu和記憶體;而邏輯寫入一般會含有邏輯,要做運算,所以不管是cpu、記憶體還是磁碟讀寫的消耗都是遠大於MQ的順序寫入的。
MQ除了能用來平滑寫高峰,還能做資料轉發,同一份資料可以傳送給多個接收者。
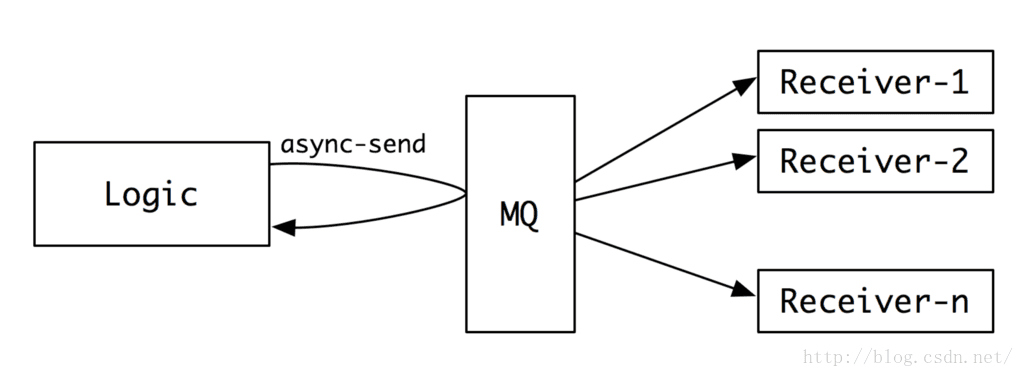
這個功能也可以被用作資料的備份、資料的回放等等。
現在比較流行的開源MQ有RabbitMQ、ActiveMQ、kafka等。這幾個MQ老王當年大致調研過,後來出於多種原因(比如:需要整合thrift、naming service改動較多;需要支援多種模式的分發、回放等不太滿足需求),最後老王花了兩週寫了一個Java版的MQ(以後有可能,準備拿出來開源),現在已經在線上穩定運行了快兩年了,接收發送資料應該有數百億了(用百詞斬的盆友,你們背的單詞資料就在裡面哦~)。大體設計思想如下:

這裡就不詳細講解了,如果大家有興趣,以後有機會老王專門做一期MQ的分享。
剛剛老王在講MQ的時候,不小心說到了一個東東:thrift。他就是Facebook做的一個RPC框架,用來解決分散式系統之間邏輯呼叫和資料交換的。那RPC具體是什麼呢?
遠端呼叫(RPC - RemoteProcedure Call):
剛剛老王在講MQ的時候,不小心說到了一個東東:thrift。他就是Facebook做的一個RPC框架,用來解決分散式系統之間邏輯呼叫和資料交換的。那RPC具體是什麼呢?

當兩個系統(或者兩個模組)要交換資料的時候,他們怎麼弄呢?最簡單的,System-1建立一個socket連線到System-2,然後通過send和recv函式,進行資料交換。
不過這樣會有很多的問題:
1、程式碼寫起來是不是很煩呢?
2、每一個send和recv是不是要討論和規定資料格式呢?
3、如果socket建立失敗了,怎麼辦呢?要不要重試呢?
4、連線和讀取超時怎麼樣管理呢?
5、……
為了解決上述的問題,在做分散式系統時候,一般會做一套遠端資料通訊協議,讓資料交換就跟呼叫本地函式一樣,而這個通訊協議底層幫你將網路連線、協議格式、讀寫管理等等都幫你做好了,你只要關心你的邏輯。這是不是極大的降低了開發的成本,並且提升了系統的穩定性呢?
現在常見的RPC工具有google的protobuf,facebook的thrift等。據瞭解現在鵝廠內部就是用的protobuf。
protobuf和thrift相比,兩個都實現了跨平臺資料協議轉換,即將資料轉換成二進位制,再將二進位制轉換成不同語言的資料。不同的是,thrift自己帶了client-server,可以直接基於這一套cs框架開發服務。而protobuf需要自己寫cs框架(或者用第三方的框架)。另外,thrift支援的語言要比protobuf多。
經過長期慎重的比較,老王最後將thrift引入到我們的系統中。這麼長時間已經執行的比較穩定。老王大概讀了thrift的程式碼3遍,也改了其中一些東東以適應專案需要,以下是老王畫的thrift的一個大體的架構圖:
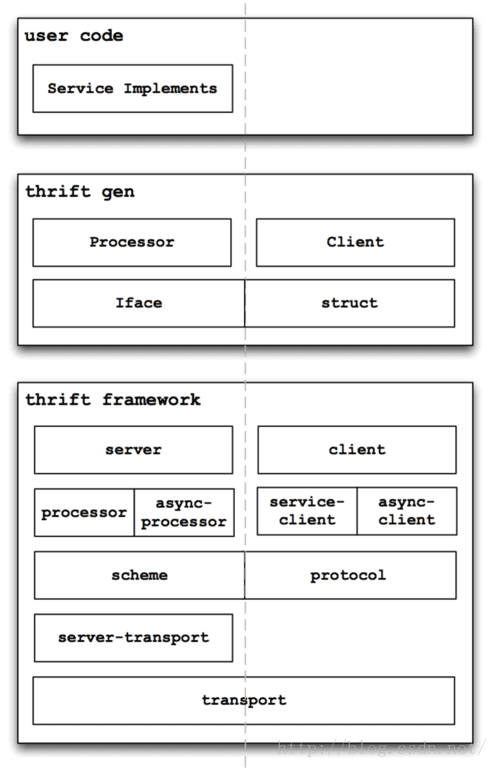
後面也準備專門做一期分享,介紹一下thrift(thrift的程式碼寫的真是很不錯,分層結構寫的相當好,極力推薦閱讀~)。
分散式Cache:
談網際網路,就一定要談談cache,因為沒有這個玩意兒,我們好多伺服器都是扛不住的。
cache的作用,就是用來快取一些不變的資料,用記憶體的高速訪問替代磁碟的低速讀取,儘量用最快的速度,將資訊返回給使用者。具體工作圖如下:
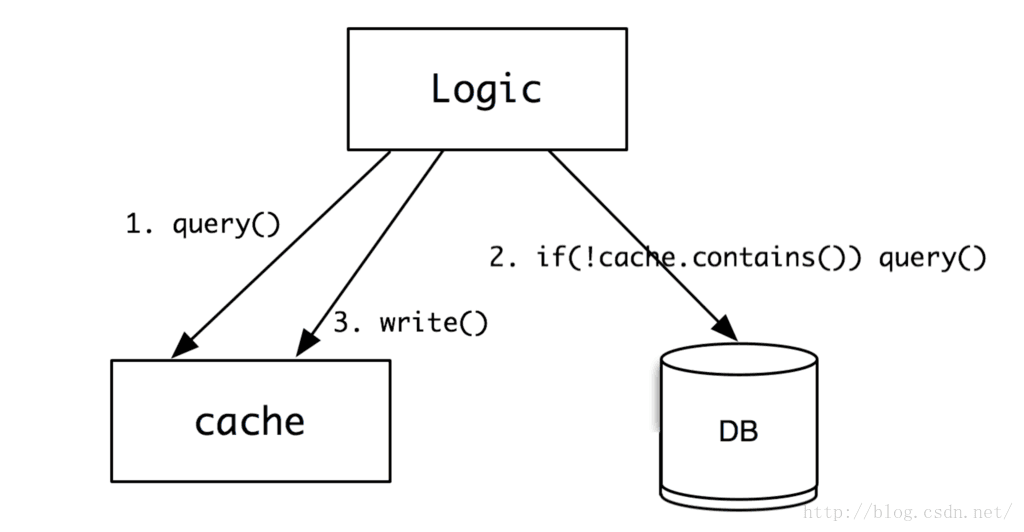
1、邏輯系統先查詢cache是否有資料,如果有,就直接返回。如果沒有,則進行第2步;
2、從資料庫查詢,如果沒有,則直接返回空;否則,進行第3步;
3、將資料寫入到cache中,這樣下次再來查詢的時候,就有資料了。
因為cache的資料一般是放在記憶體的,所以讀寫速度都比db高1-2個數量級,也就是10-100倍的速度於db。現在幾乎大部分的網站都是有使用cache的,很難有網站直接用db扛住所有壓力(如果壓力不大的除外)。不過,使用cache也帶來其他的問題,比如架構和程式碼邏輯變複雜、cache失效等的問題。不過總體來看,cache帶來的好處遠大於他的問題。
因為cache一般採用記憶體,所以單機的cache很容易收到記憶體大小的限制。我們一般會採用分散式cache叢集,將快取放到多個機器上。那就存在一個問題了,一個key的資料到底放在哪兒?後面要的時候怎麼去取呢?
這裡有兩種方式:
1、集中管理:增加一個類似於Naming Service的服務,告訴呼叫者資料究竟在哪兒?
2、分散管理:呼叫者通過一定的演算法(比如一致hash和Gossip),通過一定的計算,確定資料存放或者獲取的位置。
我們常見的分散式cache有memcache、redis等。這些都是非常著名的NoSQL資料庫,用作快取非常適合。他們對資料的管理,一般是採用分散管理的模式。客戶端通過一致Hash演算法確定資料存放位置。大家有興趣可以去讀讀原始碼(老王沒有讀過,後面準備讀讀~)。
====又是分割線 ====
好啦,這次給大家分享了一些常用的分散式元件,這些元件可以讓我們的架構具有非常大的彈性,提升我們系統的效能和容量。其他還有很多的元件,就不在這裡一一介紹了。接下來,老王會慢慢給大傢俱體介紹每個元件的詳細工作原理和設計開發中遇到的問題等。有興趣的同學趕緊關注老王的微信吧:simplemain。
ps:下週會跟大家扯一些通用的網際網路功能系統,比如:微博和微信朋友圈的內容聚合系統、內容檢索系統等等。應該很有意思~
那今天就到這裡啦~ 下週日老王繼續在這裡給大家扯技術的淡~
