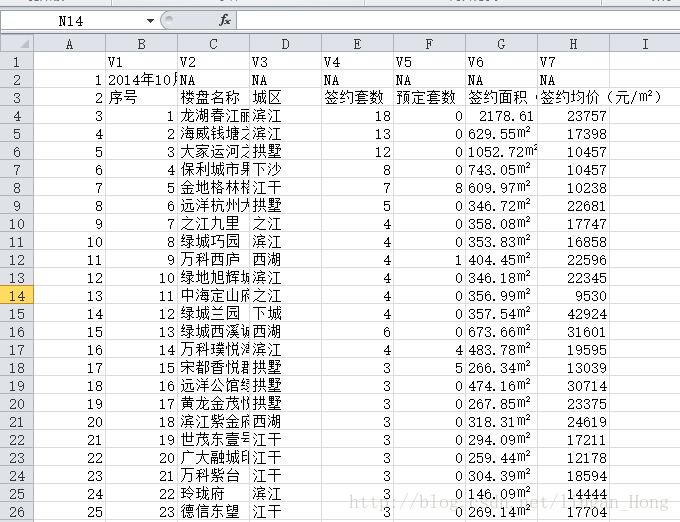
R語言實現簡單的網頁資料抓取
阿新 • • 發佈:2019-01-05
在知乎遇到這樣一個問題。
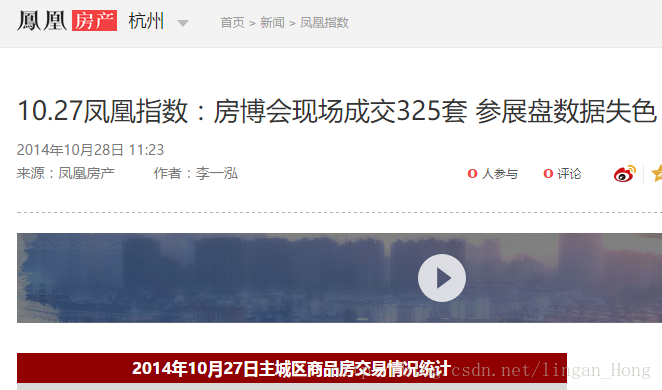
這是要爬取的內容的網頁:
R語言的程式碼的實現方式如下:
#安裝XML包
>install.packages("XML")
#載入XML包
> library(XML)
#確定網頁地址,通過網頁地址分析網頁表格
> url<-"http://hz.house.ifeng.com/detail/2014_10_28/50087618_1.shtml"
> tbls<-readHTMLTable(url)
> sapply(tbls,nrow)
NULL NULL
93 8
#讀取網頁url的第一張表
> pop<-readHTMLTable(url,which = 1 我們還可以儲存為其他格式:
#儲存為簡單文字:
>write.table(x, file = "*.txt")
#儲存為R格式檔案:
>save(x, file = "*.Rdata")