
Jsoup網頁資料抓取案例
關於Jsoup的基礎知識點這裡就不說了,個人認為很多大牛寫的很詳細也比較全面,這裡就簡單舉一個使用例子玩玩,社長也比較喜歡拿例子來理解一些知識點。
給幾個有用的連結:
1、jsoup下載地址
2、待會兒會用到,主要用來測試一些選擇器之類的是否選擇到資料,還可以查詢當前瀏覽器user-Agent
廢話不多說,以泡在網上的日子Android分類內容為例子。
頁面地址:
點選F12或者右鍵檢視網頁元素去分析需要抓取的資料所在位置
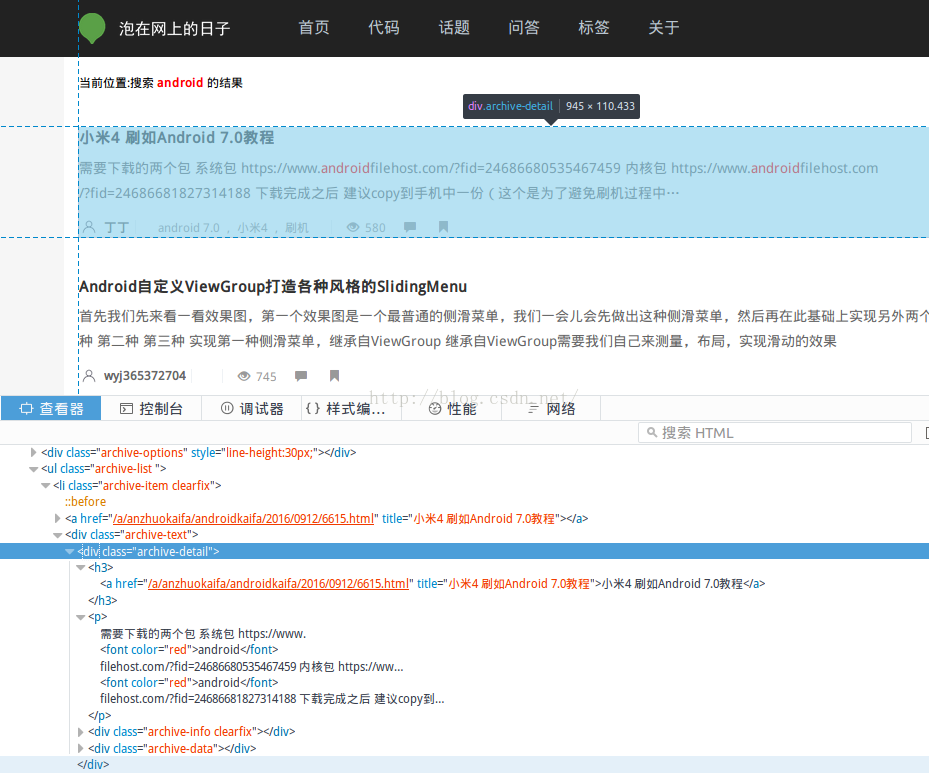
可以注意到幾個比較重要的標籤<div class="archive-detail">和子元素<h3>包含了抓取資料的連結和標題;<p>包含了抓取內容的簡介。現在可以去剛才推薦的第二個網址內測試一下。當然也可以不測。
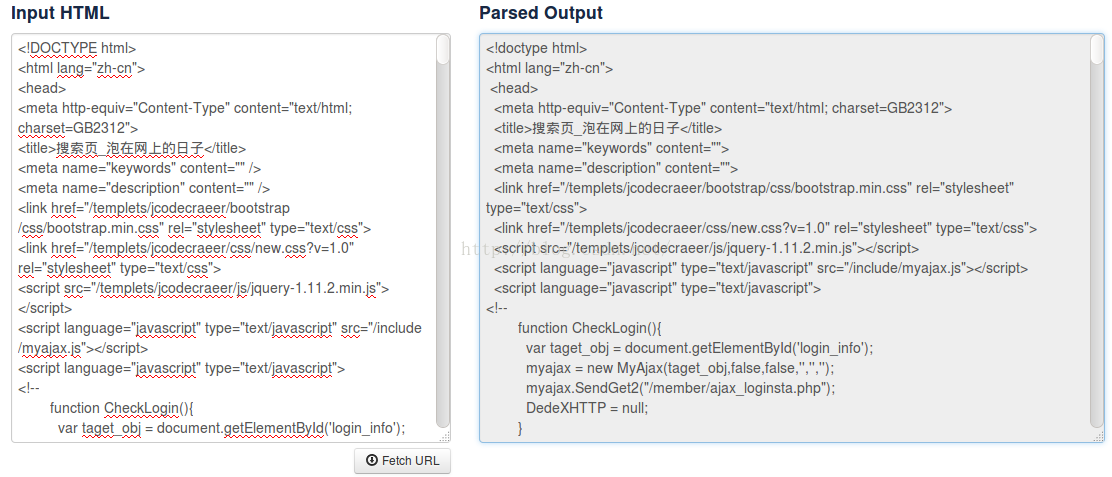
點選Fetch URL把抓取資料的網頁地址複製進來。
在搜尋框中輸入dic.archive-detail
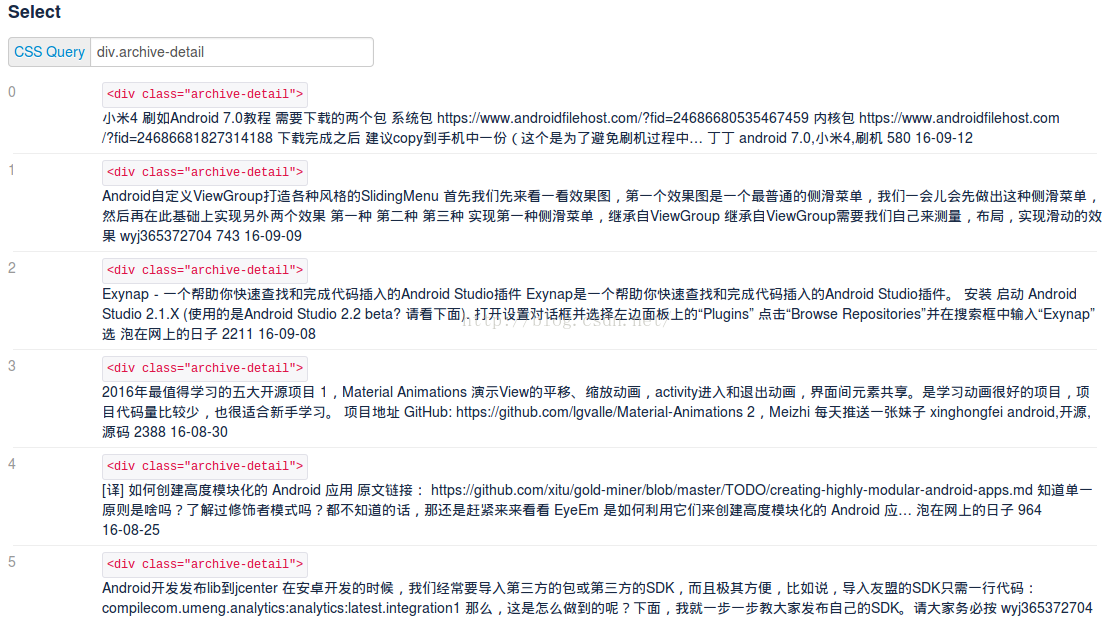
成功了,說明<div class="archive-detail">可以獲取選擇到我們需要的內容。
抓取網頁資料最重要的就是去分析資料所在位置。其次就是用Jsoup的api去獲取得到資料。那麼接下來著手程式碼。
//獲取抓取內容 public void getSelectData(String url) throws IOException { Document doc = Jsoup.connect(url).timeout(60 * 1000) .userAgent("Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:48.0) Gecko/20100101 Firefox/48.0") .get(); //例項div.archive-detail元素集合 Elements links = doc.select("div.archive-detail"); //遍歷集合下<a>標籤包含的href和title值 for(int i=0;i<links.size();i++){ Elements a = links.get(i).select("a"); Log.i("shezhang","標題 = "+a.attr("title")); Log.i("shezhang","連結 = "+a.attr("abs:href")); //獲取<p>標籤包含的內容 Elements p = links.get(i).select("p"); Log.i("shezhang","簡介 = "+p.text()); } } private void findViewById(){ btnTest = (Button) findViewById(R.id.btn_test); btnTest.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { new Thread(){ @Override public void run() { try { for(int i=1;i<=30;i++){ try { Log.i("jiawei","第"+i+"頁"); getData(url+i); sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } } catch (IOException e) { e.printStackTrace(); } } }.start(); } }); }
程式碼很簡單,過個過場。因為泡在網上的日子請求有時間限制,所有我的執行緒中睡3秒再繼續請求下一頁的內容 一共有30頁。從剛才給出的泡在上網的日子的第一頁網址可以看出只要改改最後那個頁碼就好哈哈。比較重要的就是getSelectData()中的獲取資料的程式碼。
首先例項Document物件,然後獲得主要元素,
Elements links = doc.select("div.archive-detail");這個div就是包含了各個文章連結啊標題啊簡介啊的部分,然後通過遍歷這個div元素去獲得我們想要的連結啊標題啊巴拉巴拉。先得到子元素
Elements h3 = links.get(i).select("a");
然後通過a元素去獲得a裡面的內容,包括連結啊標題啊。
Log.i("shezhang","標題 = "+h3.attr("title"));
Log.i("shezhang","連結 = "+h3.attr("abs:href"));簡介被包含在<p>標籤中
<span style="font-size:18px;">Elements p = links.get(i).select("p");
Log.i("shezhang","簡介 = "+p.text());</span>OK!執行得到: 搞定!步驟還是挺簡單的,社長寫的內容呢比較粗略。程式碼粗略。圖片粗略。。。。如果同學們專案需要用到的話,不妨把請求資料部分另外開個專門的類非同步封裝好點,把請求的資料封裝成bean物件勉強就可以用啦。這裡就做個簡單例子,學習了基本用法的時候看一些案例可以加深理解。
相關推薦
Jsoup網頁資料抓取案例
關於Jsoup的基礎知識點這裡就不說了,個人認為很多大牛寫的很詳細也比較全面,這裡就簡單舉一個使用例子玩玩,社長也比較喜歡拿例子來理解一些知識點。 給幾個有用的連結: 1、jsoup下載地址 2、待會兒會用到,主要用來測試一些選擇器之類的是否選擇到資料,還可以查詢當前瀏覽
HttpClient+jsoup實現網頁資料抓取和處理
這裡僅簡單介紹一種我曾用到的網頁資料的抓取和處理方案。 通過HttpClient可以很方便的抓取靜態網頁資料,過程很簡單,步驟如下: //構造client HttpClient client = new HttpClient(); //構建GetMethod物件 Get
Android 使用jsoup 進行資料抓取
一,身為安卓開發人員,在沒有介面的情況下是很操蛋的。索性就抓點資料測試用了。 準備工作:jsoup.jar 這裡 已經 是 已經實現好 邏輯的方法。 public class MianHuanJsoup { public static final String MH
網頁資料抓取--爬蟲
資料抓取其實從字面意思就知道它是抓取資料的,在網際網路世界中,資料量是一個非常大的。。有時候靠人為去獲取資料這是一個非常不明智的。尤其是你需要的資料來自很多不同的地方。
網頁資料抓取之讀取網頁資料
最近專案中需要用到各大網站的資料,這裡沒用爬蟲,用純java程式碼,無任何外掛,抓取一些自己需要的資料! 後續會記錄主要的幾個網站資料抓取,主要針對帶單個搜尋框的網站!下面是一個公用的讀取網頁資料操作
php 網頁資料抓取 簡單例項
最近想學習一下資料抓取方面的知識,花了一箇中午時間邊學便實驗,很快就把程式碼寫出來了,例項寫得比較簡單,學習思路為主。需要注意的是,在目標網頁上獲取的資料如果有中文的話,可能會導致亂碼的情況,這時可以用 iconv ( "UTF-8", "ISO-8859-1//TRANS
R語言實現簡單的網頁資料抓取
在知乎遇到這樣一個問題。 這是要爬取的內容的網頁: R語言的程式碼的實現方式如下: #安裝XML包 >install.packages("XML") #載入XML包 > l
網頁資料抓取之大眾點評資料
package com.atman.baiye.store.utils; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map;
Java網頁資料抓取例項
在很多行業中,要對行業資料進行分類彙總,及時分析行業資料,對於公司未來的發展,有很好的參照和橫向對比。所以,在實際工作,我們可能要遇到資料採集這個概念,資料採集的最終目的就是要獲得資料,提取有用的資料進行資料提取和資料分類彙總。 很多人在第一次瞭解資料採集的時候,可能無
一次網頁資料抓取採集儲存我的電子商務業務
最近我注意到許多電子商務指南都關注相同的技巧:增加你的社交活動投資chatbots構建一個AR應用程式雖然這些都是很棒的提示,但我在這裡只給你一個刮傷黑客的資訊,這可以幫助我的公司不再關機。(如果您沒有使用網路抓取您的線上業務,請檢視此部落格)。image: https://
網頁資訊抓取進階 支援Js生成資料 Jsoup的不足之處
轉載請標明出處:http://blog.csdn.net/lmj623565791/article/details/23866427今天又遇到一個網頁資料抓取的任務,給大家分享下。說道網頁資訊抓取,相信Jsoup基本是首選的工具,完全的類JQuery操作,讓人感覺很舒服。但是
QueryList免費線上網頁採集資料抓取工具-toolfk.com
本文要推薦的[ToolFk]是一款程式設計師經常使用的線上免費測試工具箱,ToolFk 特色是專注於程式設計師日常的開發工具,不用安裝任何軟體,只要把內容貼上按一個執行按鈕,就能獲取到想要的內容結果。ToolFk還支援 BarCode條形碼線上
爬蟲--python3.6+selenium+BeautifulSoup實現動態網頁的資料抓取,適用於對抓取頻率不高的情況
說在前面: 本文主要介紹如何抓取 頁面載入後需要通過JS載入的資料和圖片 本文是通過python中的selenium(pyhton包) + chrome(谷歌瀏覽器) + chromedrive(谷歌瀏覽器驅動) chrome 和chromdrive建議都下最新版本(參考地址:https://blog.c
實現從網頁上抓取資料(htmlparser)
package com.jscud.test; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.InputStreamReader; impo
java爬蟲--jsoup簡單的表單抓取案例
分析需求:某農產品網站的農產品價格抓取 頁面展示如上: 標籤展示如上: 分析發現每日價格行情包括了蔬菜,水果,肉等所有的資訊,所以直接抓每日行情的內容就可以實現抓取全部資料。 軟體環境:ec
java webmagic 抓取靜態網頁資源,抓取動態網頁資源
webmagicJava爬蟲框架 fastjson 阿里巴巴提供的 json 轉為物件的快捷包,裡面有下載jar包的地址 抓取靜態網頁資源 。例項:抓取李開復部落格:標題,內容,釋出日期。 public class LiKaiFuBlogReading implements Pag
spider資料抓取(第二章)
download最完善的指令碼 import urllib2 import urlparse def download(url, user_agent="wswp", proxy=None, num_retries=2): print "DownLoading", url head
C# NetCore使用AngleSharp爬取周公解夢資料 MySql資料庫的自動建立和頁面資料抓取
這一章詳細講解編碼過程 那麼接下來就是碼程式碼了,GO 新建NetCore WebApi專案 空的就可以 NuGet安裝 Install-Package AngleSharp 或者介面安裝 using。。 預設本地裝有
爬蟲[1]---頁面分析及資料抓取
頁面分析及資料抓取 anaconda + scrapy 安裝:https://blog.csdn.net/dream_dt/article/details/80187916 用 scrapy 初始化一個爬蟲:https://blog.csdn.net/dream_dt/article
爬蟲實戰-酷狗音樂資料抓取--XPath,Pyquery,Beautifulsoup資料提取對比實戰
網站: http://www.kugou.com/yy/html/rank.html 爬取目標: 酷酷狗飆升榜的歌手,歌曲名字,歌曲連結等內容,存到Mysql資料庫中 網頁解析: 此次爬取採用三種解析方式: 程式碼如下: import requests from l