
超乾貨|使用Keras和CNN構建分類器(內含程式碼和講解)
摘要: 為了讓文章不那麼枯燥,我構建了一個精靈圖鑑資料集(Pokedex)這都是一些受歡迎的精靈圖。我們在已經準備好的影象資料集上,使用Keras庫訓練一個卷積神經網路(CNN)。

為了讓文章不那麼枯燥,我構建了一個精靈圖鑑資料集(Pokedex)這都是一些受歡迎的精靈圖。我們在已經準備好的影象資料集上,使用Keras庫訓練一個卷積神經網路(CNN)。
深度學習資料集

上圖是來自我們的精靈圖鑑深度學習資料集中的合成圖樣本。我的目標是使用Keras庫和深度學習訓練一個CNN,對Pokedex資料集中的影象進行識別和分類。Pokedex資料集包括:Bulbasaur (234 images);Charmander
訓練影象包括以下組合:電視或電影的靜態幀;交易卡;行動人物;玩具和小玩意兒;圖紙和粉絲的藝術效果圖。
在這種多樣化的訓練影象的情況下,實驗結果證明,CNN模型的分類準確度高達97%!
CNN和Keras庫的專案結構
該專案分為幾個部分,目錄結構如下:
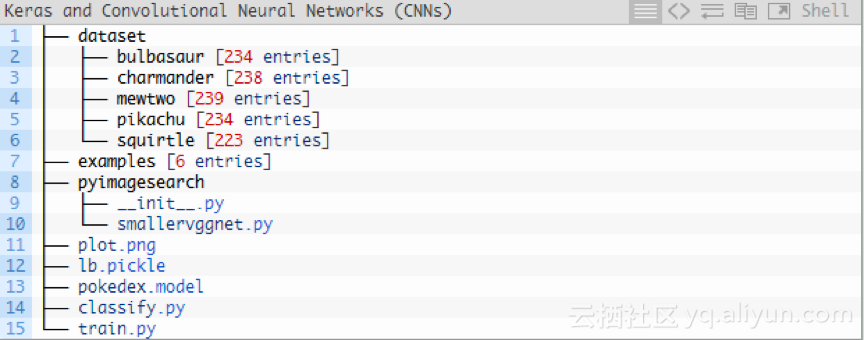
如上圖所示,共分為3個目錄:
1.資料集:包含五個類,每個類都是一個子目錄。
2.示例:包含用於測試卷積神經網路的影象。
3.pyimagesearch模組:包含我們的SmallerVGGNet模型類。
另外,根目錄下有
1.plot.png:訓練指令碼執行後,生成的訓練/測試準確性和損耗圖。
2.lb.pickle:LabelBinarizer序列化檔案,在類名稱查詢機制中包含類索引。
3.pokedex.model:序列化Keras CNN模型檔案(即“權重檔案”)。
4.train.py:訓練Keras CNN,繪製準確性/損耗函式,然後將卷積神經網路和類標籤二進位制檔案序列化到磁碟。
5.classify.py:測試指令碼。
Keras和CNN架構
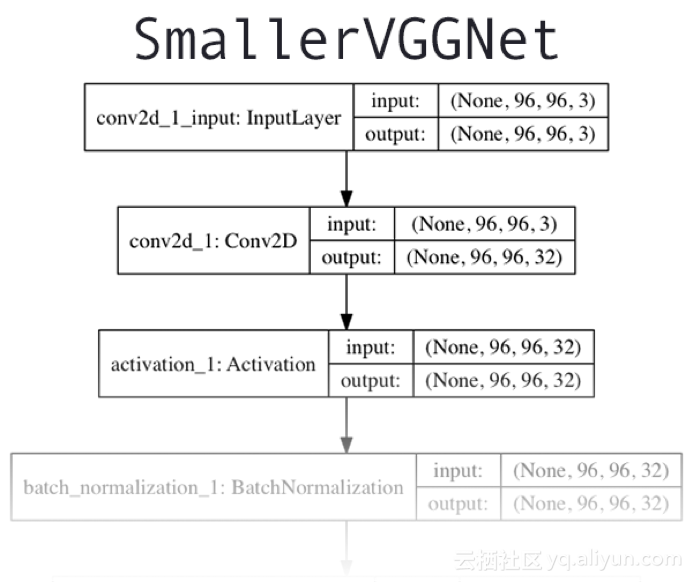
我們今天使用的CNN架構,是由Simonyan和Zisserman在2014年的論文“用於大規模影象識別的強深度卷積網路”中介紹的VGGNet網路的簡單版本,結構圖如上圖所示。該網路架構的特點是:
1.只使用3*3的卷積層堆疊在一起來增加深度。
2.使用最大池化來減小陣列大小。
3.網路末端全連線層在softmax分類器之前。
假設你已經在系統上安裝並配置了Keras。如果沒有,請參照以下連線瞭解開發環境的配置教程:
繼續使用SmallerVGGNet——VGGNet的更小版本。在pyimagesearch模組中建立一個名為smallervggnet.py的新檔案,並插入以下程式碼:
注意:在pyimagesearch中建立一個_init_.py檔案,以便Python知道該目錄是一個模組。如果你對_init_.py檔案不熟悉或者不知道如何使用它來建立模組,你只需在原文的“下載”部分下載目錄結構、原始碼、資料集和示例影象。
現在定義SmallerVGGNet類:
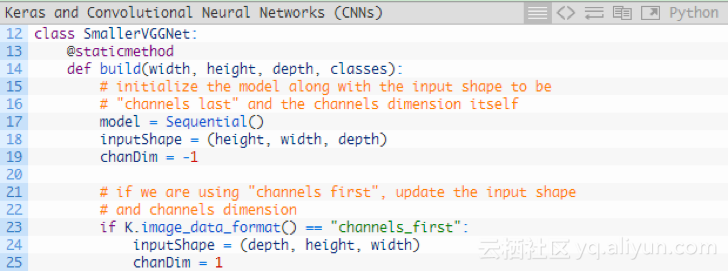
該構建方法需要四個引數:
1.width:影象寬度。
2.height :影象高度。
3.depth :影象深度。
4.classes :資料集中類的數量(這將影響模型的最後一層),我們使用了5個Pokemon 類。
注意:我們使用的是深度為3、大小為96 * 96的輸入影象。後邊解釋輸入陣列通過網路的空間維度時,請記住這一點。
由於我們使用的是TensorFlow後臺,因此用“channels last”對輸入資料進行排序;如果想用“channels last”,則可以用程式碼中的23-25行進行處理。
為模型新增層,下圖為第一個CONV => RELU => POOL程式碼塊:
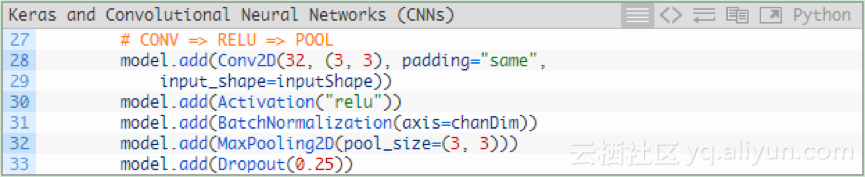
卷積層有32個核心大小為3*3的濾波器,使用RELU啟用函式,然後進行批量標準化。
池化層使用3 *3的池化,將空間維度從96 *96快速降低到32 * 32(輸入影象的大小為96 * 96 * 3的來訓練網路)。
如程式碼所示,在網路架構中使用Dropout。Dropout隨機將節點從當前層斷開,並連線到下一層。這個隨機斷開的過程有助於降低模型中的冗餘——網路層中沒有任何單個節點負責預測某個類、物件、邊或角。
在使用另外一個池化層前,新增(CONV => RELU)* 2層:
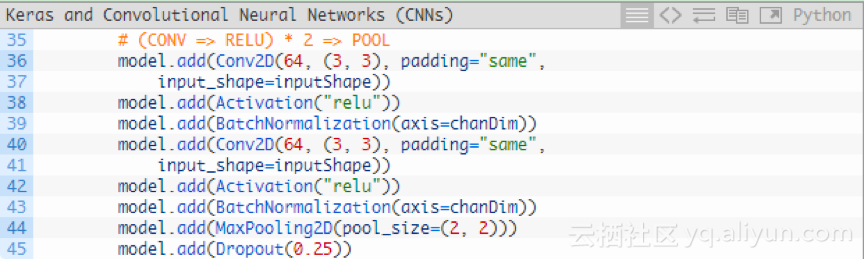
在降低輸入陣列的空間維度前,將多個卷積層RELU層堆疊在一起可以學習更豐富的特徵集。
請注意:將濾波器大小從32增加到64。隨著網路的深入,輸入陣列的空間維度越小,濾波器學習到的內容更多;將最大池化層從3*3降低到2*2,以確保不會過快地降低空間維度。在這個過程中再次執行Dropout。
再新增一個(CONV => RELU)* 2 => POOL程式碼塊:
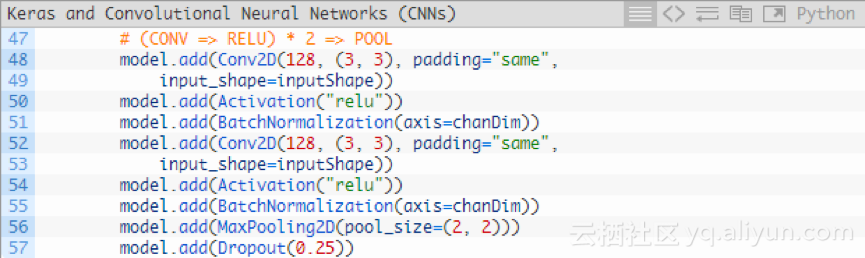
我們已經將濾波器的大小增加到128。對25%的節點執行Droupout以減少過擬合。
最後,還有一組FC => RELU層和一個softmax分類器:
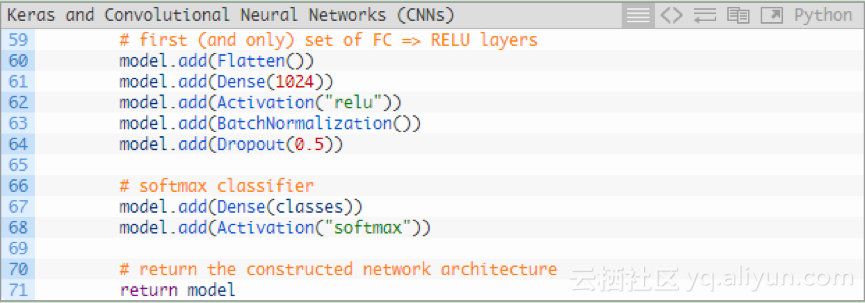
Dense(1024)使用具有校正的線性單位啟用和批量歸一化指定全連線層。
最後再執行一次Droupout——在訓練期間我們Droupout了50%的節點。通常情況下,你會在全連線層在較低速率下使用40-50%的Droupout,其他網路層為10-25%的Droupout。
用softmax分類器對模型進行四捨五入,該分類器將返回每個類別標籤的預測概率值。
CNN + Keras訓練指令碼的實現
既然VGGNet小版本已經實現,現在我們使用Keras來訓練卷積神經網路。
建立一個名為train.py的新檔案,並插入以下程式碼,匯入需要的軟體包和庫:
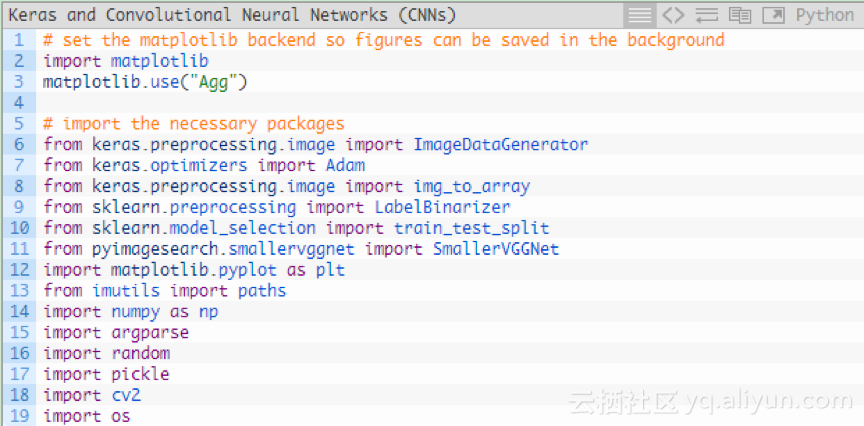
使用”Agg” matplotlib後臺,以便可以將數字儲存在背景中(第3行)。
ImageDataGenerator類用於資料增強,這是一種對資料集中的影象進行隨機變換(旋轉、剪下等)以生成其他訓練資料的技術。資料增強有助於防止過擬合。
第7行匯入了Adam優化器,用於訓練網路。
第9行的LabelBinarizer是一個重要的類,其作用如下:
1.輸入一組類標籤的集合(即表示資料集中人類可讀的類標籤字串)。
2.將類標籤轉換為獨熱編碼向量。
3.允許從Keras CNN中進行整型類別標籤預測,並轉換為人類可讀標籤。
經常會有讀者問:如何將類標籤字串轉換為整型?或者如何將整型轉換為類標籤字串。答案就是使用LabelBinarizer類。
第10行的train_test_split函式用來建立訓練和測試分叉。
讀者對我自己的imutils包較為了解。如果你沒有安裝或更新,可以通過以下方式進行安裝:

如果你使用的是Python虛擬環境,確保在安裝或升級imutils之前,用workon命令訪問特定的虛擬環境。
我們來解析一下命令列引數:
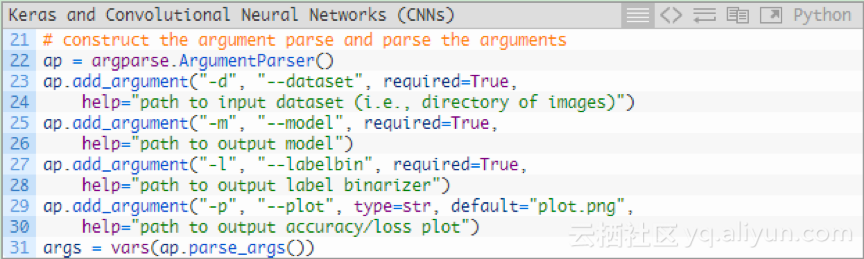
對於我們的訓練指令碼,有三個必須的引數:
1.--dataset:輸入資料集的路徑。資料集放在一個目錄中,其子目錄代表每個類,每個子目錄約有250個精靈圖片。
2.--model:輸出模型的路徑,將訓練模型輸出到磁碟。
3.--labelbin:輸出標籤二進位制器的路徑。
還有一個可選引數--plot。如果不指定路徑或檔名,那麼plot.png檔案則在當前工作目錄中。
不需要修改第22-31行來提供新的檔案路徑,程式碼在執行時會自行處理。
現在,初始化一些重要的變數:
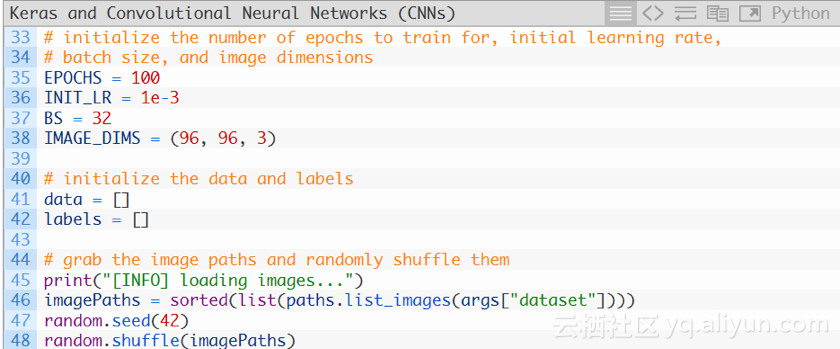
第35-38行對訓練Keras CNN時使用的重要變數進行初始化:
1.-EPOCHS:訓練網路的次數。
2.-INIT-LR:初始學習速率值,1e-3是Adam優化器的預設值,用來優化網路。
3.-BS:將成批的影象傳送到網路中進行訓練,同一時期會有多個批次,BS值控制批次的大小。
4.-IMAGE-DIMS:提供輸入影象的空間維度數。輸入的影象為96*96*3(即RGB)。
然後初始化兩個列表——data和labels,分別儲存預處理後的影象和標籤。第46-48行抓取所有的影象路徑並隨機擾亂。
現在,對所有的影象路徑ImagePaths進行迴圈:
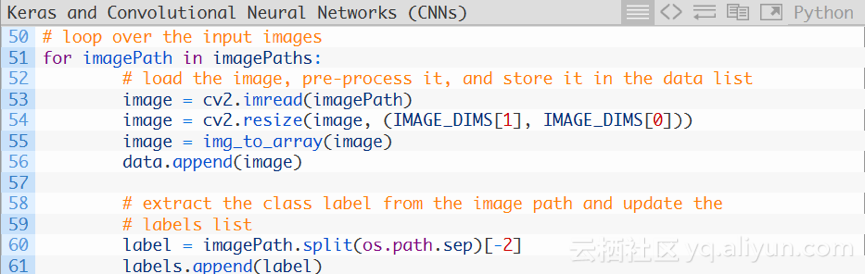
首先對imagePaths進行迴圈(第51行),再對影象進行載入(第53行),然後調整其大小以適應模型(第54行)。
現在,更新data和labels列表。
呼叫Keras庫的img_to_arry函式,將影象轉換為與Keras庫相容的陣列(第55行),然後將影象新增到名為data的列表中(第56行)。
對於labels列表,我們在第60行檔案路徑中提取出label,並將其新增在第61行。
那麼,為什麼需要類標籤分解過程呢?
考慮到這樣一個事實,我們有目的地建立dataset目錄結構,格式如下:

第60行的路徑分隔符可以將路徑分割成一個數組,然後獲取列表中的倒數第二項——類標籤。
然後進行額外的預處理、二值化標籤和資料分割槽,程式碼如下:
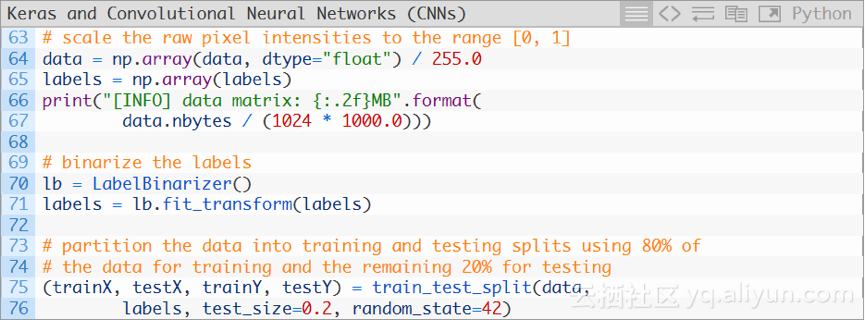
首先將data陣列轉換為NumPy陣列,然後將畫素強度縮放到[0,1]範圍內(第64行),也要將列表中的labels轉換為NumPy陣列(第65行)。列印data矩陣的大小(以MB為單位)。
然後使用scikit-learn庫的LabelBinarzer對標籤進行二進位制化(第70和71行)。
對於深度學習(或者任何機器學習),通常的做法是將訓練和測試分開。第75和76行將訓練集和測試集按照80/20的比例進行分割。
接下來建立影象資料增強物件:

因為訓練資料有限(每個類別的影象數量小於250),因此可以利用資料增強為模型提供更多的影象(基於現有影象),資料增強是一種很重要的工具。
摘要: 為了讓文章不那麼枯燥,我構建了一個精靈圖鑑資料集(Pokedex)這都是一些受歡迎的精靈圖。我們在已經準備好的影象資料集上,使用Keras庫訓練一個卷積神經網路(CNN)。為了讓文章不那麼枯燥,
整合學習 之 隨機森林分類器
整合學習的定義和分類。
隨機森林法的定義和分類。
隨機森林sklearn.ensemble.RandomForestClassifier()引數分類和含義。
附註:Bias和Variance的含義和關係。
一、整合學習 (Ensemble
資料還是得看啊,又讀了經典文獻《Robust Real-Time Face Detection》,不願意讀原文的朋友可以看看http://blog.csdn.net/hqw7286/article/details/5556767,作者把文中的要點基本也都總結出來了。Ope
最近學習了斯坦福的CS231n(winter 2016)系列課程,收穫很大,作為深度學習以及卷積神經網路學習的入門很是完美。學習過程中,主要參考了知乎上幾位同學的課程翻譯,做得很好,在這裡也對他們表示感謝,跟課程相關的很多資源都可以在該專欄中找到。推薦大家把每個
資料還是得看啊,又讀了經典文獻《Robust Real-Time Face Detection》,不願意讀原文的朋友可以看看http://blog.csdn.net/hqw7286/article/details/5556767,作者把文中的要點基本也都總結出來了。Ope
前言:
在最優化計算方法中,我已經講到了機器學習常用的一些引數優化的方法,如梯度法,共軛梯度法,牛頓法,擬牛頓法,在《最優化計算方法》板塊,我都用迴歸分析比較了這些引數優化的方法,從現在開始,我將把這些引數優化的方法用來訓練分類器。
在本節中,我講介紹sof
什麼是流程圖?流程圖是思維導圖的一種圖形模式,通過固定的流程和圖形組合而成,通常應用於IT業、建築業、數字統計行業中。因為思維導圖慢慢熱門起來,所以其他領域也都開始慢慢學習這款思維工具,並通過思維導圖工具整理大腦邏輯、加強記憶等。
一、流程圖的型別
1、基本流程圖
基本流程
原文連結:https://github.com/fastforwardlabs/keras-hello-world/blob/master/kerashelloworld.ipynb
原文標題:“Hello world” in Keras
本文全部程式碼基於python2,
本文以CAIL司法挑戰賽的資料為例,敘述利用Keras框架進行文字分類的一般流程及基本的深度學習模型。 步驟 1:文字的預處理,分詞->去除停用詞->統計選擇top n的詞做為特徵詞 步驟 2:為每個特徵詞生成I Keras基本的使用都已經清楚了,那麼這篇主要學習如何使用Keras進行訓練模型,訓練訓練,主要就是“練”,所以多做幾個案例就知道怎麼做了。
在本文中,我們將提供一些面向小資料集(幾百張到幾千張圖片)構造高效,實用的影象分類器的方法。
1,熱身練習——CIFAR10 小圖片分類示例(Sequentia def vector print sha python width 技術分享 port 計算 代碼部分
SVM損失函數 & SoftMax損失函數:
註意一下softmax損失的用法:
SVM損失函數:
import numpy as np
def L_i
視覺集
視覺資料庫是用來提供給圖片識別領域用素材,目前各個教材常用的主要有手寫數字識別庫、10中小圖片分類庫,詳細介紹如下:
Mnist
&
使用機器學習的方法進行人臉檢測的第一步需要訓練人臉分類器,這是一個耗時耗力的過程,需要收集大量的正負樣本,並且樣本質量的好壞對結果影響巨大,如果樣本沒有處理好,再優秀的機器學習分類演算法都是零。
今年3月23日,微軟公司在推特(Twitter)社交平臺上推出了一個基於機
貝葉斯決策論
貝葉斯決策論(Bayesian decision theory)是概率框架下實施決策的基本方法。在所有相關概率都已知的理想情況下,貝葉斯決策論考慮如何基於這些概率和誤判斷來選擇最優的類別標記。
假設有N種可能的類別標記,即Y={c1,c2,.
《情感分析方法之nltk情感分析器和SVM分類器(二)》主要使用nltk處理英文語料,使用SVM分類器處理中文語料。實際的新聞評論中既包含英文,又包含中文和阿拉伯文。本次主要使用snownlp處理中文語料。一、snownlp使用from snownlp import Snow
1.SVM建立線性分類器SVM用來構建分類器和迴歸器的監督學習模型,SVM通過對數學方程組的求解,可以找出兩組資料之間的最佳分割邊界。2.準備工作我們首先對資料進行視覺化,使用的檔案來自學習書籍配套管網。首先增加以下程式碼:import numpy as np
import
總的來講,一個完整的文字分類器主要由兩個階段,或者說兩個部分組成:一是將文字向量化,將一個字串轉化成向量形式;二是傳統的分類器,包括線性分類器,SVM, 神經網路分類器等等。
之前看的THUCTC的技術棧是使用 tf-idf 來進行文字向量化,使用卡方校驗(c
Node.js
前提
環境:windows7下載地址:http://nodejs.org/download/
安裝
官網下載一個安裝檔案點選下一步安裝完成即可.
驗證安裝是否成功:node -v
基本HTTP伺服器
c:/http.js
Js程式碼
公式:(P(x)為常數,可忽略不考慮)平滑:Nyk是類別為yk的樣本個數,n是特徵的維數,Nyk,xi是類別為yk的樣本中,第i維特徵的值是xi的樣本個數,α是平滑值。在對NBCorpus詞分類時,帶入上面的公式可得:某詞屬於某類別的概率 = (該類別該詞的個數 + 1/
1、對於複雜的含有多Wi引數的函式L求導問題,首先是分別對單個引數求偏導數,然後放置到此引數對應的矩陣的位置。在求偏導數的矩陣表示時,一般要經歷如下兩個步驟:數字計算:分解步驟,同時計算L和導數:一般情況下,L的計算分很多步,而且每一步也十分複雜,可能涉及到數值判定等。但是隻 相關推薦
超乾貨|使用Keras和CNN構建分類器(內含程式碼和講解)
scikit-learn /sklearn : 整合學習 之 隨機森林分類器(Forests of Randomized Tree)官方檔案翻譯
OpenCV學習筆記——用haar特徵訓練自己的分類器(再做手勢檢測)
斯坦福CS231n 課程學習筆記--線性分類器(Assignment1程式碼實現)
OpenCV學習筆記(三十三)——用haar特徵訓練自己的分類器(再做手勢檢測)
deep learning Softmax分類器(L-BFGS,CG,SD)
親測超好用的一款流程圖製作軟體(內含製圖技巧分享)
【Iris】【Keras】神經網路分類器和【scikit-learn】邏輯迴歸分類器的構建
Keras實現CNN文字分類
我的Keras使用總結(2)——構建影象分類模型(針對小資料集)
『cs231n』限制性分類器損失函數和最優化
深度學習 (四)Keras利用CNN實現圖片識別(Mnist、Cifar10)
OpenCV中基於Haar特徵和級聯分類器的人臉檢測(三)
機器學習----貝葉斯分類器(貝葉斯決策論和極大似然估計)
情感分析方法之snownlp和貝葉斯分類器(三)
Python構建SVM分類器(線性)
使用gensim和sklearn搭建一個文字分類器(一):流程概述
Node.js+Express構建Http服務(GET方式和POST方式)
樸素貝葉斯(二)實現NBCorpus分類(附程式碼和資料)
關於cs231n中作業1的SVM和Softmax線性分類器實現的感悟