
我的Keras使用總結(2)——構建影象分類模型(針對小資料集)
Keras基本的使用都已經清楚了,那麼這篇主要學習如何使用Keras進行訓練模型,訓練訓練,主要就是“練”,所以多做幾個案例就知道怎麼做了。
在本文中,我們將提供一些面向小資料集(幾百張到幾千張圖片)構造高效,實用的影象分類器的方法。
1,熱身練習——CIFAR10 小圖片分類示例(Sequential式)
示例中CIFAR10採用的是Sequential式來編譯網路結構。程式碼如下:
# 要訓練模型,首先得知道資料長啥樣
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
batch_size = 32
num_classes = 10
epochs = 100
data_augmentation = True
# 資料載入
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 多分類標籤生成,我們將其由單個標籤,生成一個熱編碼的形式
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# 網路結構配置
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:])) # (32, 32, 3)
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(num_classes))
model.add(Activation('softmax'))
# 訓練引數設定
# initiate RMSprop optimizer
opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
# Let's train the model using RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# 生成訓練資料
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
if not data_augmentation:
print("Not using data augmentation")
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
else:
print("Using real-time data augmentation")
# this will do preprocessing and realtime data augmentation
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=0, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=False) # randomly flip images
# Compute quantities required for feature-wise normalization
# (std, mean, and principal components if ZCA whitening is applied).
datagen.fit(x_train)
# fit訓練
# fit the model on batches generated by datagen.flow()
model.fit_generator(datagen.flow(x_train, y_train,
batch_size=batch_size),
epochs=epochs,
validation_data=(x_test, y_test))
擷取部分epoch的執行結果:
49056/50000 [============================>.] - ETA: 4s - loss: 0.6400 - acc: 0.7855 49088/50000 [============================>.] - ETA: 4s - loss: 0.6399 - acc: 0.7855 49120/50000 [============================>.] - ETA: 3s - loss: 0.6401 - acc: 0.7855 49152/50000 [============================>.] - ETA: 3s - loss: 0.6399 - acc: 0.7855 49184/50000 [============================>.] - ETA: 3s - loss: 0.6398 - acc: 0.7856 49216/50000 [============================>.] - ETA: 3s - loss: 0.6397 - acc: 0.7856 49248/50000 [============================>.] - ETA: 3s - loss: 0.6395 - acc: 0.7856 49280/50000 [============================>.] - ETA: 3s - loss: 0.6396 - acc: 0.7857 49312/50000 [============================>.] - ETA: 3s - loss: 0.6398 - acc: 0.7856 49344/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49376/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49408/50000 [============================>.] - ETA: 2s - loss: 0.6403 - acc: 0.7856 49440/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49472/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49504/50000 [============================>.] - ETA: 2s - loss: 0.6405 - acc: 0.7855 49536/50000 [============================>.] - ETA: 2s - loss: 0.6406 - acc: 0.7855 49568/50000 [============================>.] - ETA: 1s - loss: 0.6407 - acc: 0.7855 49600/50000 [============================>.] - ETA: 1s - loss: 0.6407 - acc: 0.7854 49632/50000 [============================>.] - ETA: 1s - loss: 0.6410 - acc: 0.7854 49664/50000 [============================>.] - ETA: 1s - loss: 0.6409 - acc: 0.7853 49696/50000 [============================>.] - ETA: 1s - loss: 0.6410 - acc: 0.7853 49728/50000 [============================>.] - ETA: 1s - loss: 0.6412 - acc: 0.7852 49760/50000 [============================>.] - ETA: 1s - loss: 0.6413 - acc: 0.7852 49792/50000 [============================>.] - ETA: 0s - loss: 0.6413 - acc: 0.7852 49824/50000 [============================>.] - ETA: 0s - loss: 0.6413 - acc: 0.7852 49856/50000 [============================>.] - ETA: 0s - loss: 0.6414 - acc: 0.7851 49888/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7851 49920/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7851 49952/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7850 49984/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7850 50000/50000 [==============================] - 228s 5ms/step - loss: 0.6414 - acc: 0.7851 - val_loss: 0.6509 - val_acc: 0.7836 Epoch 55/200
其實跑到第55個epoch,準確率已經達到了 0.785了,後面肯定能達到八九十,我這裡就暫停了,讓我電腦歇一歇,跑一天了。其實跑這個就是證明模型沒有問題,而且我的程式碼可以執行,僅此而已。
2,針對小資料集的深度學習
本節實驗基於如下配置:
- 2000張訓練圖片構成的資料集,一共有兩個類別,每類1000張
- 安裝有Keras,Scipy,PIL的機器,如果有GPU就更好的了,但是因為我們面對的是小資料集,沒有也可以
- 資料集存放格式如下:

這份資料集來自於Kaggle,元資料集有12500只貓和12500只狗,我們只取了各個類的前500張圖片,另外還從各個類中取了1000張額外圖片用於測試。
下面是資料集的一些示例圖片,圖片的數量非常少,這對於影象分類來說是個大麻煩。但現實是,很多真實世界圖片獲取是很困難的,我們能得到的樣本數目確實很有限(比如醫學影象,每張正樣本都意味著一個承受痛苦的病人)對資料科學家而言,我們應該有能夠榨取少量資料的全部價值的能力,而不是簡單的伸手要更多的資料。

在Kaggle的貓狗大戰競賽中,參賽者通過使用現代的深度學習技術達到了98%的正確率,我們只使用了全部資料的8%,因此這個問題對我們來說更難。
經常聽說的一種做法是,深度學習只有在你擁有海量資料的時候才有意義。雖然這種說法並不是完全不對,但卻具有較強的誤導性。當然,深度學習強調從資料中自動學習特徵的能力,沒有足夠的訓練樣本,這幾乎是不可能的。尤其是當輸入的資料維度很高(如圖片)時。然而,卷積神經網路作為深度學習的支柱,被設計為針對“感知”問題最好的模型之一(如影象分類問題),即使只有很少的資料,網路也能把特徵學的不錯。針對小資料集的神經網路依然能夠得到合理的結果,並不需要任何手工的特徵工程。一言以蔽之,卷積神經網路大法好!另一方面,深度學習模型天然就具有可重用的特性:比方說,你可以把一個在大規模資料上訓練好的影象分類或語音識別的模型重用在另一個很不一樣的問題上,而只需要做有限的一點改動。尤其是在計算機視覺領域,許多預訓練的模型現在都被公開下載,並重用在其他問題上以提升在小資料集上的效能。
2.1 資料預處理與資料提升
為了儘量利用我們有限的訓練資料,我們將通過一系列變換堆資料進行提升,這樣我們的模型將看不到任何兩張完全相同的圖片,這有利於我們抑制過擬合,使得模型的泛化能力更好。
在Keras中,這個步驟可以通過keras.preprocessing.image.ImageDataGenerator來實現,也就是圖片預處理生成器,這個類使你可以:
- 在訓練過程中,設定要施行的隨機變換。
- 通過 .flow 或者 .flow_from_directory(directory) 方法例項化一個針對影象 batch 的生成器,這些生成器可以被用作 Keras模型相關方法的輸入,如 fit_generator,evaluate_generator 和 predict_generator。
datagen = ImageDataGenerator() datagen.fit(x_train)
生成器初始化 datagen,生成 datagen.fit,計算依賴於資料的變化所需要的統計資訊。
最終把資料需要按照每個batch進行劃分,這樣就可以送到模型進行訓練了
datagen.flow(x_train, y_train, batch_size=batch_size)
接收numpy陣列和標籤為引數,生成經過資料提升或標準化後的batch資料,並在一個無限迴圈中不斷的返回batch資料。
具體的圖片生成器函式ImageDataGenerator:(他可以用以生成一個 batch的影象資料,支援實時資料提升,訓練時該函式會無限生成資料,直到達到規定的 epoch次數為止。)
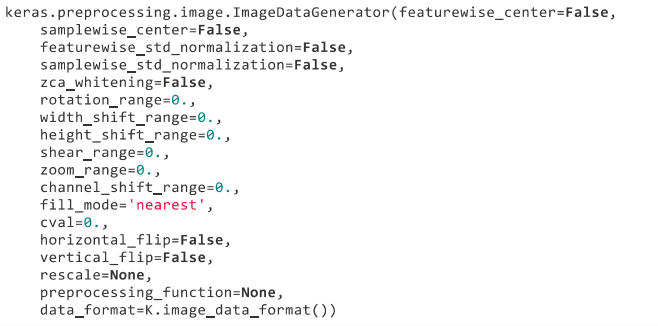
引數意思:


方法有三個,分別是 fit() flow() flow_from_directory() 下面繼續截圖Keras官網的內容:




現在我們看一個例子:
#_*_coding:utf-8_*_
'''
使用ImageDataGenerator 來生成圖片,並將其儲存在一個臨時資料夾中
下面感受一下資料提升究竟做了什麼事情。
'''
import os
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40, # 是一個0~180的度數,用來指定隨機選擇圖片的角度
width_shift_range=0.2, # 水平方向的隨機移動程度
height_shift_range=0.2, # 豎直方向的隨機移動程度
rescale=1./255, #將在執行其他處理前乘到整個影象上
shear_range=0.2, # 用來進行剪下變換的程度,參考剪下變換
zoom_range=0.2, # 用來進行隨機的放大
horizontal_flip=True, # 隨機的對圖片進行水平翻轉,此引數用於水平翻轉不影響圖片語義的時候
fill_mode='nearest' # 用來指定當需要進行畫素填充,如旋轉,水平和豎直位移的時候
)
pho_path = 'timg.jpg'
img = load_img(pho_path) # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1, ) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
if not os.path.exists('preview'):
os.mkdir('preview')
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='durant', save_format='jpg'):
i += 1
if i > 20:
break # otherwise the generator would loop indefitely
這是原圖:

下面是一張圖片被提升以後得到的多個結果:


下面貼上三個官網的例子:
1,使用.flow() 的例子

2,使用.flow_from_directory(directory)
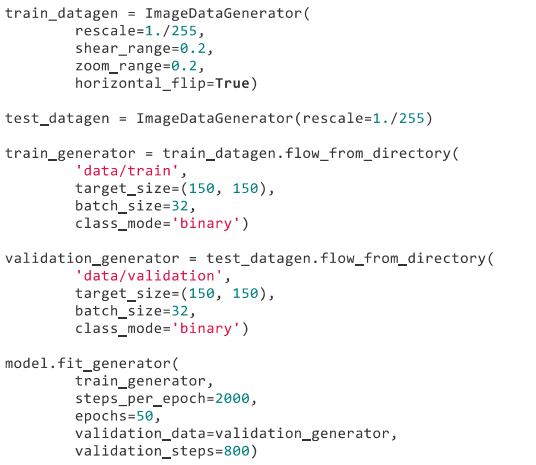
3,同時變換影象和 mask

2.2 在小資料集上訓練神經網路:40行程式碼達到80%的準確率
進行影象分類的正確工具是卷積網路,所以我們來試試用卷積神經網路搭建一個初級的模型。因為我們的樣本數很少,所以我們應該對過擬合的問題多加註意。當一個模型從很少的樣本中學習到不能推廣到新資料的模式時,我們稱為出現了過擬合的問題。過擬合發生時,模型試圖使用不相關的特徵來進行預測。例如,你有三張伐木工人的照片,有三張水手的照片。六張照片中只有一個伐木工人戴了帽子,如果你認為戴帽子是能將伐木工人與水手區別開的特徵,那麼此時你就是一個差勁的分類器。
資料提升是對抗過擬合問題的一個武器,但還不夠,因為提升過的資料讓然是高度相關的。對抗過擬合的你應該主要關注的時模型的“熵容量”——模型允許儲存的資訊量。能夠儲存更多資訊的模型能夠利用更多的特徵取得更好的效能,但也有儲存不相關特徵的風險。另一方面,只能儲存少量資訊的模型會將儲存的特徵主要集中在真正相關的特徵上,並有更好的泛華效能。
有很多不同的方法來調整模型的“熵容量”,常見的一種選擇是調整模型的引數數目,即模型的層數和每層的規模。另一種方法時對權重進行正則化約束,如L1或L2這種約束會使模型的權重偏向較小的值。
在我們的模型裡,我們使用了很小的卷積網路,只有很少的幾層,每層的濾波器數目也不多。再加上資料提升和Dropout,就差不多了。Dropout通過防止一層看到兩次完全一樣的模式來防止過擬合,相當於也是資料提升的方法。(你可以說Dropout和資料提升都在隨機擾亂資料的相關性)
下面展示的程式碼是我們的第一個模型,一個很簡單的3層卷積加上ReLU啟用函式,再接max-pooling層,這個結構和Yann LeCun 在1990 年釋出的影象分類器很相似(除了ReLU)
這個實驗的程式碼如下:
#_*_coding:utf-8_*_
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras import backend as K
K.set_image_dim_ordering('th')
# 簡單的三層卷積加上ReLU啟用函式,再接一個max-pooling層
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(3, 150, 150)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#the model so far outputs 3D feature maps (height, width, features)
# 然後我們接了兩個全連線網路,並以單個神經元和Sigmoid啟用結束模型
# 這種選擇會產生一個二分類的結果,與這種配置項適應,損失函式選擇binary_crossentropy
# this converts our 3D feature maps to 1D feature vectors
model.add(Flatten())
# 新增隱藏層神經元的數量和啟用函式
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# next read data
# 使用 .flow_from_directory() 來從我們的jpgs圖片中直接產生資料和標籤
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
# this is the augmentation configuration we will use for testing only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# this is a generator that will read pictures found in subfliders
# of 'data/train'. and indefinitely generate batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'DogsVSCats/train', # this is the target directory
target_size=(150, 150), # all image will be resize to 150*150
batch_size=32,
class_mode='binary'
) # since we use binary_crossentropy loss,we need binary labels
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'DogsVSCats/valid', # this is the target directory
target_size=(150, 150), # all image will be resize to 150*150
batch_size=32,
class_mode='binary'
)
# 然後我們可以用這個生成器來訓練網路了。
model.fit_generator(
train_generator,
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800
)
model.save_weights('first_try.h5') #always save your weights after training or duraing trianing
部分結果如下:
Epoch 1/50 62/62 [==============================] - 66s 1s/step - loss: 0.7043 - acc: 0.5238 - val_loss: 0.6798 - val_acc: 0.5015 Epoch 2/50 62/62 [==============================] - 63s 1s/step - loss: 0.6837 - acc: 0.5762 - val_loss: 0.6481 - val_acc: 0.6837 Epoch 3/50 62/62 [==============================] - 63s 1s/step - loss: 0.6465 - acc: 0.6503 - val_loss: 0.5826 - val_acc: 0.6827 Epoch 4/50 62/62 [==============================] - 63s 1s/step - loss: 0.6077 - acc: 0.6884 - val_loss: 0.5512 - val_acc: 0.7447 Epoch 5/50 62/62 [==============================] - 63s 1s/step - loss: 0.5568 - acc: 0.7088 - val_loss: 0.5127 - val_acc: 0.7357 Epoch 6/50 62/62 [==============================] - 63s 1s/step - loss: 0.5469 - acc: 0.7241 - val_loss: 0.4962 - val_acc: 0.7578 Epoch 7/50 62/62 [==============================] - 63s 1s/step - loss: 0.5236 - acc: 0.7446 - val_loss: 0.4325 - val_acc: 0.8028 Epoch 8/50 62/62 [==============================] - 63s 1s/step - loss: 0.4842 - acc: 0.7751 - val_loss: 0.4710 - val_acc: 0.7758 Epoch 9/50 62/62 [==============================] - 63s 1s/step - loss: 0.4693 - acc: 0.7726 - val_loss: 0.4383 - val_acc: 0.7808 Epoch 10/50 62/62 [==============================] - 63s 1s/step - loss: 0.4545 - acc: 0.7952 - val_loss: 0.3806 - val_acc: 0.8298 Epoch 11/50 62/62 [==============================] - 63s 1s/step - loss: 0.4331 - acc: 0.8031 - val_loss: 0.3781 - val_acc: 0.8248 Epoch 12/50 62/62 [==============================] - 63s 1s/step - loss: 0.4178 - acc: 0.8162 - val_loss: 0.3146 - val_acc: 0.8799 Epoch 13/50 62/62 [==============================] - 63s 1s/step - loss: 0.3926 - acc: 0.8275 - val_loss: 0.3030 - val_acc: 0.8739 Epoch 14/50 62/62 [==============================] - 63s 1s/step - loss: 0.3854 - acc: 0.8295 - val_loss: 0.2835 - val_acc: 0.8929 Epoch 15/50 62/62 [==============================] - 63s 1s/step - loss: 0.3714 - acc: 0.8303 - val_loss: 0.2882 - val_acc: 0.8879 Epoch 16/50 62/62 [==============================] - 63s 1s/step - loss: 0.3596 - acc: 0.8517 - val_loss: 0.3727 - val_acc: 0.8228 Epoch 17/50 62/62 [==============================] - 63s 1s/step - loss: 0.3369 - acc: 0.8568 - val_loss: 0.3638 - val_acc: 0.8328 Epoch 18/50 62/62 [==============================] - 63s 1s/step - loss: 0.3249 - acc: 0.8608 - val_loss: 0.2589 - val_acc: 0.8819 Epoch 19/50 62/62 [==============================] - 63s 1s/step - loss: 0.3348 - acc: 0.8548 - val_loss: 0.2273 - val_acc: 0.9079 Epoch 20/50 62/62 [==============================] - 63s 1s/step - loss: 0.2979 - acc: 0.8754 - val_loss: 0.1737 - val_acc: 0.9389 Epoch 21/50 62/62 [==============================] - 63s 1s/step - loss: 0.2980 - acc: 0.8686 - val_loss: 0.2198 - val_acc: 0.9189 Epoch 22/50 62/62 [==============================] - 63s 1s/step - loss: 0.2789 - acc: 0.8815 - val_loss: 0.2040 - val_acc: 0.9109 Epoch 23/50 62/62 [==============================] - 63s 1s/step - loss: 0.2793 - acc: 0.8891 - val_loss: 0.1388 - val_acc: 0.9479 Epoch 24/50 62/62 [==============================] - 63s 1s/step - loss: 0.2799 - acc: 0.8865 - val_loss: 0.1565 - val_acc: 0.9419 Epoch 25/50 62/62 [==============================] - 63s 1s/step - loss: 0.2513 - acc: 0.8949 - val_loss: 0.1467 - val_acc: 0.9510 Epoch 26/50 62/62 [==============================] - 63s 1s/step - loss: 0.2551 - acc: 0.9029 - val_loss: 0.1281 - val_acc: 0.9520 Epoch 27/50 62/62 [==============================] - 63s 1s/step - loss: 0.2387 - acc: 0.8961 - val_loss: 0.1590 - val_acc: 0.9409 Epoch 28/50 62/62 [==============================] - 63s 1s/step - loss: 0.2449 - acc: 0.9054 - val_loss: 0.1250 - val_acc: 0.9580 Epoch 29/50 62/62 [==============================] - 63s 1s/step - loss: 0.2158 - acc: 0.9218 - val_loss: 0.0881 - val_acc: 0.9780 Epoch 30/50 62/62 [==============================] - 63s 1s/step - loss: 0.2286 - acc: 0.9158 - val_loss: 0.1012 - val_acc: 0.9660 Epoch 31/50 62/62 [==============================] - 63s 1s/step - loss: 0.2017 - acc: 0.9181 - val_loss: 0.1109 - val_acc: 0.9570 Epoch 32/50 62/62 [==============================] - 63s 1s/step - loss: 0.1957 - acc: 0.9213 - val_loss: 0.1160 - val_acc: 0.9560 Epoch 33/50 62/62 [==============================] - 63s 1s/step - loss: 0.2046 - acc: 0.9249 - val_loss: 0.0600 - val_acc: 0.9840 Epoch 34/50 62/62 [==============================] - 63s 1s/step - loss: 0.1967 - acc: 0.9206 - val_loss: 0.0713 - val_acc: 0.9790 Epoch 35/50 62/62 [==============================] - 63s 1s/step - loss: 0.2238 - acc: 0.9153 - val_loss: 0.3123 - val_acc: 0.8929 Epoch 36/50 62/62 [==============================] - 63s 1s/step - loss: 0.1841 - acc: 0.9317 - val_loss: 0.0751 - val_acc: 0.9740 Epoch 37/50 62/62 [==============================] - 63s 1s/step - loss: 0.1890 - acc: 0.9279 - val_loss: 0.1030 - val_acc: 0.9700
這個模型在50個epoch後的準確率為 79%~81%。(但是我的準確率在38個epoch卻達到了驚人的92%,也是恐怖)沒有做模型和超引數的優化。
注意這個準確率的變化可能會比較大,因為準確率本來就是一個變化較高的評估引數,而且我們的訓練樣本比較少,所以比較好的驗證方法就是使用K折交叉驗證,但每輪驗證中我們都要訓練一個模型。
2.3 Keras報錯:ValueError: Negative dimension size caused by subtracting 2 ...
(解決方法參考:https://blog.csdn.net/akadiao/article/details/80531070)
使用Keras時遇到如下錯誤:
ValueError: Negative dimension size caused by subtracting 2 from 1 for 'block2_pool/MaxPool' (op: 'MaxPool') with input shapes: [?,1,75,128].
解決方法:這個是圖片的通道順序問題。
以128*128的RGB影象為例 channels_last應該將資料組織為(128, 128, 3),而channels_first將資料組織為(3, 128, 128)。
通過檢視函式 set_image_dim_ording():
def set_image_dim_ordering(dim_ordering):
"""Legacy setter for `image_data_format`.
# Arguments
dim_ordering: string. `tf` or `th`.
# Raises
ValueError: if `dim_ordering` is invalid.
"""
global _IMAGE_DATA_FORMAT
if dim_ordering not in {'tf', 'th'}:
raise ValueError('Unknown dim_ordering:', dim_ordering)
if dim_ordering == 'th':
data_format = 'channels_first'
else:
data_format = 'channels_last'
_IMAGE_DATA_FORMAT = data_format
可知,tf對應原本的 channels_last,th對應 channels_first,因此新增下面程式碼即可解決問題:
from keras import backend as K
K.set_image_dim_ordering('th')
這樣保證要使用的通道順序和配置的通道順序一致即可。
3,多分類簡易網路結構(Sequential)
官方文件是貓狗二分類,我們上面已經做過了,此時我們將其變為一個五分類,由於追求效率,從網上找來一個很小的資料集,資料來源:Caffe學習系列(12):訓練和測試自己的圖片
資料描述:
共有500張圖片,分為大巴車、恐龍、大象、鮮花和馬五個類,每個類100張。下載地址:http://pan.baidu.com/s/1nuqlTnN
編號分別以3,4,5,6,7開頭,各為一類。我從其中每類選出20張作為測試,其餘80張作為訓練。因此最終訓練圖片400張,測試圖片100張,共5類。如下圖:
(注意,這裡需要自己將圖片分為五類,包括訓練集和測試集)
3.1 載入與模型網路構建
程式碼如下:
# 載入與模型網路構建
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
def built_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
# filter大小為3*3 數量為32個,原始影象大小3,150 150
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# this converts ours 3D feature maps to 1D feature vector
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(5)) # 幾個分類就幾個dense
model.add(Activation('softmax')) # 多分類
3.2 影象預處理
下面我們開始準備資料,使用 .flow_from_directory() 來從我們的jpgs圖片中直接產生資料和標籤。
其中值得留意的是:
- ImageDataGenerate:用以生成一個 batch 的影象資料,支援實時資料提升。訓練時該函式會無限生成資料,直到達到規定的epoch次數為止。
- flow_from_directory(directory):以資料夾路徑為引數,生成經過資料提升/歸一化後的資料,在一個無限迴圈中無限產生batch資料。
def generate_data():
'''
flow_from_directory是計算資料的一些屬性值,之後再訓練階段直接丟進去這些生成器。
通過這個函式來準確資料,可以讓我們的jpgs圖片中直接產生資料和標籤
:return:
'''
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150), # all images will be resized to 150*150
batch_size=32,
class_mode='categorical' # 多分類
)
validation_generator = test_datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=32,
class_mode='categorical' # 多分類
)
return train_generator, validation_generator
3.3 載入與模型網路構建
程式碼如下:(和上面兩分類的沒多少差別)
def built_model():
# 載入與模型網路構建
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
# filter大小為3*3 數量為32個,原始影象大小3,150 150
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# this converts ours 3D feature maps to 1D feature vector
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(5)) # 幾個分類就幾個dense
model.add(Activation('softmax')) # 多分類
# model.compile(loss='binary_corssentropy',
# optimizer='rmsprop',
# metrics=['accuracy'])
# 優化器rmsprop:除學習率可調整外,建議保持優化器的其他預設引數不變
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.summary()
return model
3.4 訓練
程式碼如下:
def train_model(model=None):
if model is None:
model = built_model()
model.fit_generator(
train_generator,
# sampels_per_epoch 相當於每個epoch資料量峰值,
# 每個epoch以經過模型的樣本數達到samples_per_epoch時,記一個epoch結束
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800
)
model.save_weights('first_try_animal.h5')
3.5 部分結果展示和所有原始碼
部分結果如下(這裡僅展示一個完整的epoch訓練資料):
Epoch 50/50 1/62 [..............................] - ETA: 1:10 - loss: 0.4921 - acc: 0.9062 2/62 [..............................] - ETA: 1:13 - loss: 0.2460 - acc: 0.9531 3/62 [>.............................] - ETA: 1:12 - loss: 0.1640 - acc: 0.9688 4/62 [>.............................] - ETA: 1:02 - loss: 0.1230 - acc: 0.9766 5/62 [=>............................] - ETA: 1:02 - loss: 0.0985 - acc: 0.9812 6/62 [=>............................] - ETA: 1:02 - loss: 0.0821 - acc: 0.9844 7/62 [==>...........................] - ETA: 1:02 - loss: 0.0704 - acc: 0.9866 8/62 [==>...........................] - ETA: 1:00 - loss: 0.0616 - acc: 0.9883 9/62 [===>..........................] - ETA: 59s - loss: 0.0547 - acc: 0.9896 10/62 [===>..........................] - ETA: 59s - loss: 0.0493 - acc: 0.9906 11/62 [====>.........................] - ETA: 59s - loss: 0.0448 - acc: 0.9915 12/62 [====>.........................] - ETA: 58s - loss: 0.0412 - acc: 0.9922 13/62 [=====>........................] - ETA: 57s - loss: 0.0380 - acc: 0.9928 14/62 [=====>........................] - ETA: 55s - loss: 0.0363 - acc: 0.9933 15/62 [======>.......................] - ETA: 54s - loss: 0.0339 - acc: 0.9938 16/62 [======>.......................] - ETA: 53s - loss: 0.0318 - acc: 0.9941 17/62 [=======>......................] - ETA: 51s - loss: 0.0316 - acc: 0.9945 18/62 [=======>......................] - ETA: 50s - loss: 0.0298 - acc: 0.9948 19/62 [========>.....................] - ETA: 49s - loss: 0.0283 - acc: 0.9951 20/62 [========>.....................] - ETA: 48s - loss: 0.0268 - acc: 0.9953 21/62 [=========>....................] - ETA: 47s - loss: 0.0259 - acc: 0.9955 22/62 [=========>....................] - ETA: 46s - loss: 0.0247 - acc: 0.9957 23/62 [==========>...................] - ETA: 45s - loss: 0.0236 - acc: 0.9959 24/62 [==========>...................] - ETA: 44s - loss: 0.0227 - acc: 0.9961 25/62 [===========>..................] - ETA: 42s - loss: 0.0218 - acc: 0.9962 26/62 [===========>..................] - ETA: 42s - loss: 0.0209 - acc: 0.9964 27/62 [============>.................] - ETA: 41s - loss: 0.0202 - acc: 0.9965 28/62 [============>.................] - ETA: 40s - loss: 0.0194 - acc: 0.9967 29/62 [=============>................] - ETA: 39s - loss: 0.0188 - acc: 0.9968 30/62 [=============>................] - ETA: 37s - loss: 0.0181 - acc: 0.9969 31/62 [==============>...............] - ETA: 36s - loss: 0.0176 - acc: 0.9970 32/62 [==============>...............] - ETA: 34s - loss: 0.0170 - acc: 0.9971 33/62 [==============>...............] - ETA: 33s - loss: 0.0165 - acc: 0.9972 34/62 [===============>..............] - ETA: 32s - loss: 0.0160 - acc: 0.9972 35/62 [===============>..............] - ETA: 31s - loss: 0.0156 - acc: 0.9973 36/62 [================>.............] - ETA: 30s - loss: 0.0151 - acc: 0.9974 37/62 [================>.............] - ETA: 29s - loss: 0.0147 - acc: 0.9975 38/62 [=================>............] - ETA: 28s - loss: 0.0146 - acc: 0.9975 39/62 [=================>............] - ETA: 27s - loss: 0.0142 - acc: 0.9976 40/62 [==================>...........] - ETA: 26s - loss: 0.0139 - acc: 0.9977 41/62 [==================>...........] - ETA: 24s - loss: 0.0135 - acc: 0.9977 42/62 [===================>..........] - ETA: 23s - loss: 0.0132 - acc: 0.9978 43/62 [===================>..........] - ETA: 22s - loss: 0.0129 - acc: 0.9978 44/62 [====================>.........] - ETA: 21s - loss: 0.0126 - acc: 0.9979 45/62 [====================>.........] - ETA: 20s - loss: 0.0123 - acc: 0.9979 46/62 [=====================>........] - ETA: 19s - loss: 0.0135 - acc: 0.9973 47/62 [=====================>........] - ETA: 17s - loss: 0.0153 - acc: 0.9967 48/62 [======================>.......] - ETA: 16s - loss: 0.0254 - acc: 0.9961 49/62 [======================>.......] - ETA: 15s - loss: 0.0249 - acc: 0.9962 50/62 [=======================>......] - ETA: 14s - loss: 0.0244 - acc: 0.9962 51/62 [=======================>......] - ETA: 13s - loss: 0.0338 - acc: 0.9957 52/62 [========================>.....] - ETA: 11s - loss: 0.0332 - acc: 0.9958 53/62 [========================>.....] - ETA: 10s - loss: 0.0329 - acc: 0.9959 54/62 [=========================>....] - ETA: 9s - loss: 0.0323 - acc: 0.9959 55/62 [=========================>....] - ETA: 8s - loss: 0.0317 - acc: 0.9960 56/62 [==========================>...] - ETA: 7s - loss: 0.0393 - acc: 0.9950 57/62 [==========================>...] - ETA: 5s - loss: 0.0511 - acc: 0.9940 58/62 [===========================>..] - ETA: 4s - loss: 0.0502 - acc: 0.9941 59/62 [===========================>..] - ETA: 3s - loss: 0.0494 - acc: 0.9942 60/62 [============================>.] - ETA: 2s - loss: 0.0518 - acc: 0.9938 61/62 [============================>.] - ETA: 1s - loss: 0.0535 - acc: 0.9933 62/62 [==============================] - 271s 4s/step - loss: 0.0607 - acc: 0.9929 - val_loss: 0.7166 - val_acc: 0.9300
原始碼如下:
# 載入與模型網路構建
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import os
def built_model():
# 載入與模型網路構建
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
# filter大小為3*3 數量為32個,原始影象大小3,150 150
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# this converts ours 3D feature maps to 1D feature vector
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(5)) # 幾個分類就幾個dense
model.add(Activation('softmax')) # 多分類
# model.compile(loss='binary_corssentropy',
# optimizer='rmsprop',
# metrics=['accuracy'])
# 優化器rmsprop:除學習率可調整外,建議保持優化器的其他預設引數不變
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.summary()
return model
def generate_data():
'''
flow_from_directory是計算資料的一些屬性值,之後再訓練階段直接丟進去這些生成器。
通過這個函式來準確資料,可以讓我們的jpgs圖片中直接產生資料和標籤
:return:
'''
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150), # all images will be resized to 150*150
batch_size=32,
class_mode='categorical' # 多分類
)
validation_generator = test_datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=32,
class_mode='categorical' # 多分類
)
return train_generator, validation_generator
def train_model(model=None):
if model is None:
model = built_model()
model.fit_generator(
train_generator,
# sampels_per_epoch 相當於每個epoch資料量峰值,
# 每個epoch以經過模型的樣本數達到samples_per_epoch時,記一個epoch結束
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800
)
model.save_weights('first_try_animal.h5')
if __name__ == '__main__':
train_generator, validation_generator = generate_data()
train_model()
# 當loss出現負數,肯定是之前多分類的標籤哪些設定的不對,
注意上面的 steps_per_epoch和validation_steps的值(應該是這樣計算出來的):
model=build_model(input_shape=(IMG_W,IMG_H,IMG_CH)) # 輸入的圖片維度
# 模型的訓練
model.fit_generator(train_generator, # 資料流
steps_per_epoch=train_samples_num // batch_size,
epochs=epochs,
validation_data=val_generator,
validation_steps=val_samples_num // batch_size)
3.6 畫圖展示和使用模型預測
最後我們可以通過圖直觀的檢視訓練過程中的 loss 和 acc ,看看其變化趨勢。下面是程式碼:
# 畫圖,將訓練時的acc和loss都繪製到圖上
import matplotlib.pyplot as plt
def plot_training(history):
plt.figure(12)
plt.subplot(121)
train_acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(len(train_acc))
plt.plot(epochs, train_acc, 'b',label='train_acc')
plt.plot(epochs, val_acc, 'r',label='test_acc')
plt.title('Train and Test accuracy')
plt.legend()
plt.subplot(122)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(train_loss))
plt.plot(epochs, train_loss, 'b',label='train_loss')
plt.plot(epochs, val_loss, 'r',label='test_loss')
plt.title('Train and Test loss')
plt.legend()
plt.show()
我們也可以通過訓練好的模型去預測新的樣本。
單張樣本的預測程式碼如下:
# 用訓練好的模型來預測新樣本
from PIL import Image
from keras.preprocessing import image
def predict(model, img_path, target_size):
img=Image.open(img_path) # 載入圖片
if img.size != target_size:
img = img.resize(target_size)
x = image.img_to_array(img)
x *=1./255 # 相當於ImageDataGenerator(rescale=1. / 255)
x = np.expand_dims(x, axis=0) # 調整圖片維度
preds = model.predict(x) # 預測
return preds[0]
批量預測(一個資料夾中的所有檔案):
# 預測一個資料夾中的所有圖片
new_sample_gen=ImageDataGenerator(rescale=1. / 255)
newsample_generator=new_sample_gen.flow_from_directory(
'E:\PyProjects\DataSet\FireAI\DeepLearning',
target_size=(IMG_W, IMG_H),
batch_size=16,
class_mode=None,
shuffle=False)
predicted=model.predict_generator(newsample_generator)
print(predicted)
注意我們上面儲存模型是儲存的權重,而不是模型,儲存模型的程式碼如下:
# 模型的載入,預測
from keras.models import load_model
saved_model=load_model('animal.h5')
predicted=saved_model.predict_generator(newsample_generator)
print(predicted) # saved_model的結果和前面的model結果一致,表面模型正確儲存和載入
如果儲存的是權重,直接載入,會報錯:

最後,我自己的預測程式碼:
# 用訓練好的模型來預測新的樣本
from keras.preprocessing import image
import cv2
import numpy as np
from keras.models import load_model
def predict(model, img_path, target_size):
img = cv2.imread(img_path)
if img.shape != target_size:
img = cv2.resize(img, target_size)
# print(img.shape)
x = image.img_to_array(img)
x *= 1. / 255 # 相當於ImageDataGenerator(rescale=1. / 255)
x = np.expand_dims(x, axis=0) # 調整圖片維度
preds = model.predict(x)
return preds[0]
if __name__ == '__main__':
model_path = 'animal.h5'
model = load_model(model_path)
target_size = (150, 150)
img_path = 'data/test/300.jpg'
res = predict(model, img_path, target_size)
print(res)
參考文獻:https://www.jianshu.com/p/09b5a5d82eec
https://blog.csdn.net/sinat_26917383/article/details/72861152#commentBox
https://github.com/RayDean/DeepLearning/blob/master/FireAI_005_KerasBinaryClass.ipynb
還有Keras官網,我的目的只是復現,掌握Kera