
支援向量機SVM原理篇
阿新 • • 發佈:2019-01-05
1.關鍵概念及學習目標
- 線性&非線性分類問題&核技巧
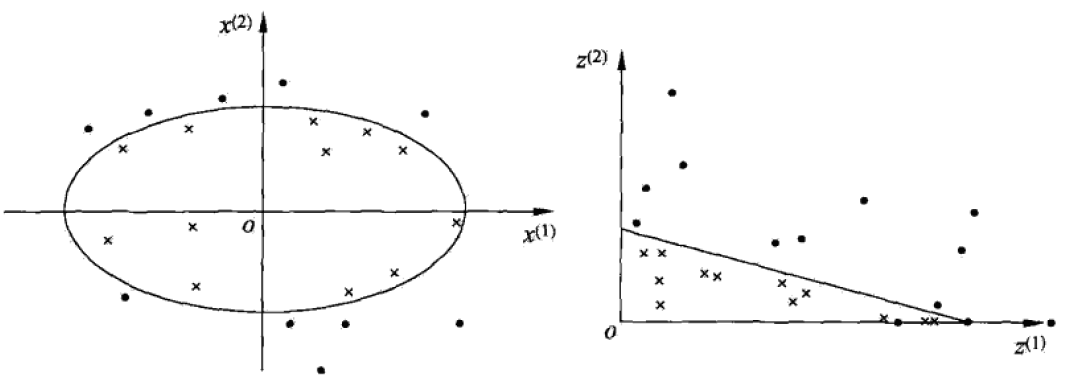
- 非線性分類問題是指通過利用非線性模型才能很好地進行分類的問題。如上圖左側,我們無法用直線(線性模型)將正負例正確分開,但可以用一條橢圓曲線(非線性模型)將他們正確分開。此時,我們可以進行一個非線性變換。
- 核技巧應用到支援向量機,其基本想法就是通過一個非線性變換將輸入空間(歐氏空間或離散集合)對應於一個特徵空間(希爾伯特空間),使得原有的超曲面模型對應於特徵空間的超平面模型
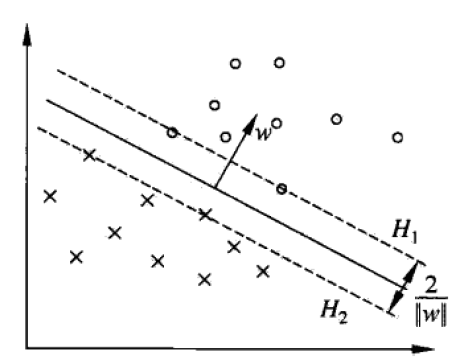
支援向量和間隔邊界
線上性可分的情況下,訓練資料集的樣本點中與分離超平面距離最近的樣本點的例項稱為支援向量。在決定分離超平面時只有支援向量起作用,而其他例項點並不起作用。(注
:這裡我們討論的是線性可分的SVM,對於軟間隔,非線性可分情況,則可以通過加正則、核技巧解決,其他類似)如上圖所示,
上的點就是支援向量。同時支援向量需要滿足下面這個約束條件。
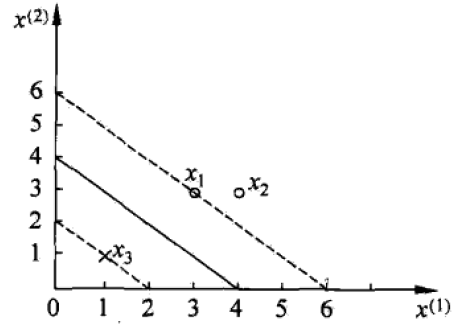
- 舉例來說
如上圖所示,其中X1,X2為正例,X3為反例,則SVM希望有如下約束
- 支援向量機模型中,我們的學習目標
- 接續看上圖,直覺上看,如果我們的分類器足夠好,那我們的正負支援向量之間的間隔應該越大,用數學公式描述如下:
- 綜上,我們得到了一個有約束的優化問題,也就是學習目標(這裡寫的是一個標準的形式,方便後面進行推導和理解)
- 接續看上圖,直覺上看,如果我們的分類器足夠好,那我們的正負支援向量之間的間隔應該越大,用數學公式描述如下:
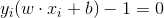

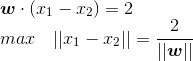
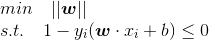
2.拉格朗日&對偶演算法推導
- 對於上面的約束問題(目標函式為凸函式),我們會想到拉格朗日對偶性(對凸優化不太瞭解的讀者,可以看下這本書 《Convex Optimization》 地址)。這樣做的優點,一是對偶問題往往更容易求解;二是自然引入核函式(跟推匯出來的結果有關),進而推廣到非線性分類問題。
推導過程
(1)定義拉格朗日函式根據拉格朗日對偶性,原始問題的對偶問題是極大極小問題:
所以,為了得到對偶問題的解,需要先對L(w,b,a)對w,b的極小,再求對a的極大。
(2)求
將拉格朗日函式L(w,b,a)分別對w,b求偏導數並令其為0.
得到
將上式代入到拉格朗日函式中,得到
(3)求
對a的極大,即對偶問題
(4)設
是上面對偶問題的解,則存在下標j,使得
.
根據KKT條件成立,我們可以得到
由於
所以
進而
分離超平面可以寫成
分類決策函式可以寫成
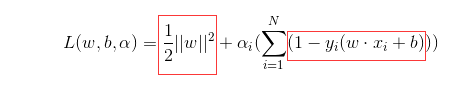
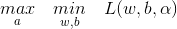
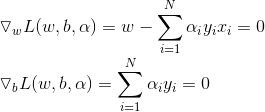
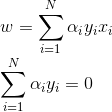
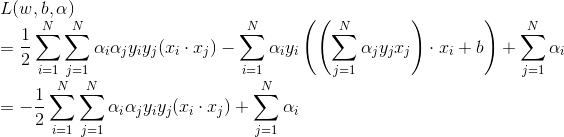
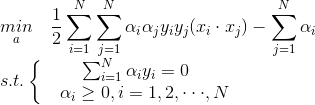
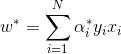

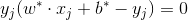
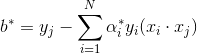
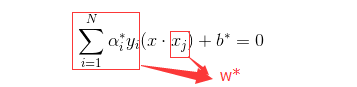
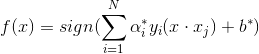
至此,我們已經推導完畢,得到最優的w,b。從上式上我們可以看出,分類決策函式只依賴於輸入x和訓練樣本輸入的內積(這一內積又與後面的核函式有著千絲萬縷的聯絡,到這裡讀者是否感受到SVM理論上的優美呢,哈哈哈)
3.知其所以然
如果你看明白上面的推導了,那麼問題來了,對偶形式的解與原始解相等需要什麼前提條件呢?
凸函式 && KKT

4.損失函式
- 支援向量機整個學習過程我們都介紹完了,但是整個過程都沒有涉及到損失函式。其實,線性支援向量機的學習還有另外一種解釋,就是如下的損失函式(簡稱合頁(hinge)損失函式)
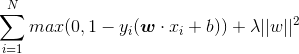
目標函式的第一項是經驗損失或經驗風險,第二項是正則項(再一次驚歎magic)
在李航老師的書中有證明,感興趣的讀者可以去看一看。
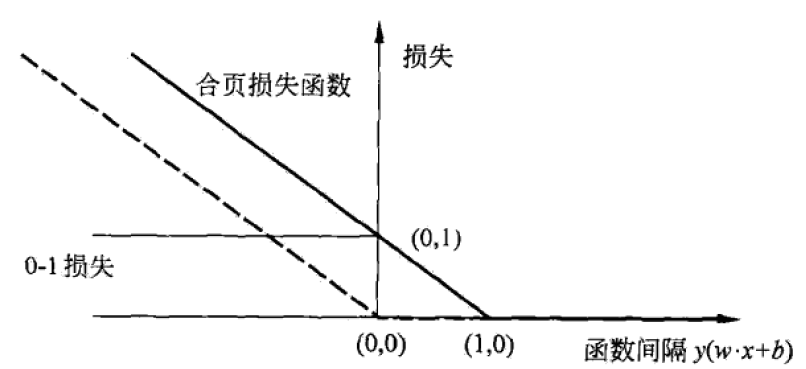
- 下面來觀察一下這個合頁損失函式
(1)0-1損失函式,可以認為它是二分類問題的真正的損失函式,且不是連續可導的
(2)合頁損失函式式0-1損失函式的上界
(3)當樣本點被正確分類時,損失為0,否則損失是1
。
(4)合頁損失函式不僅要分類正確,而且確信度足夠高損失才是0。也就是說,合頁損失函式對學習有更高的要求。
5.常見核函式
(1)多項式核函式
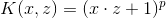
(2)高斯核函式
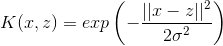
6.實戰Tip
支援向量機SVM,在處理線性問題時,速度和精度都還可以。但是在處理非線性問題時,在大量高緯度資料中會顯得異常的慢(及時使用序列最小最優化演算法SMO這種啟發式演算法)。
參考文獻
1.李航.統計學習方法