
支援向量機(SVM)原理詳解
SVM簡介
支援向量機(support vector machines, SVM)是一種二分類模型,它的基本模型是定義在特徵空間上的間隔最大的線性分類器,間隔最大使它有別於感知機;SVM還包括核技巧,這使它成為實質上的非線性分類器。SVM的的學習策略就是間隔最大化,可形式化為一個求解凸二次規劃的問題,也等價於正則化的合頁損失函式的最小化問題。SVM的的學習演算法就是求解凸二次規劃的最優化演算法。
一、支援向量與超平面
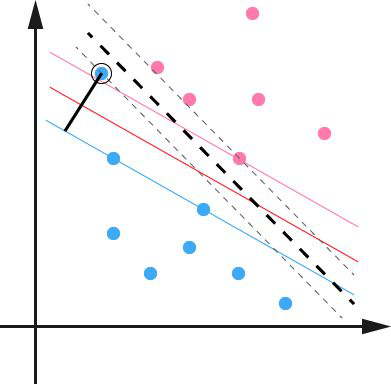
在瞭解svm演算法之前,我們首先需要了解一下線性分類器這個概念。比如給定一系列的資料樣本,每個樣本都有對應的一個標籤。為了使得描述更加直觀,我們採用二維平面進行解釋,高維空間原理也是一樣。舉個簡單子:如下圖所示是一個二維平面,平面上有兩類不同的資料,分別用圓圈和方塊表示。我們可以很簡單地找到一條直線使得兩類資料正好能夠完全分開。但是能將據點完全劃開直線不止一條,那麼在如此眾多的直線中我們應該選擇哪一條呢?從直觀感覺上看圖中的幾條直線,
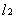
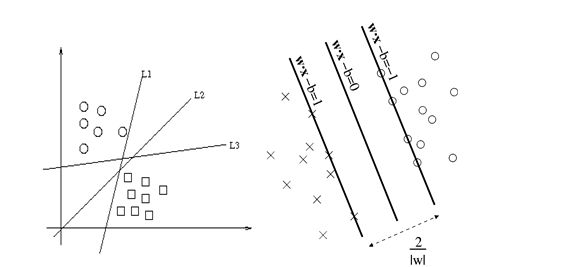
二、SVM演算法原理
2.1 點到超平面的距離公式
既然這樣的直線是存在的,那麼我們怎樣尋找出這樣的直線呢?與二維空間類似,超平面的方程也可以寫成一下形式:
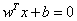
有了超平面的表示式之後之後,我們就可以計算樣本點到平面的距離了。假設

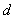
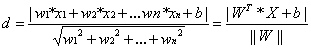
其中||W||為超平面的範數,常數b類似於直線方程中的截距。
上面的公式可以利用解析幾何或高中平面幾何知識進行推導,這裡不做進一步解釋。
2.2 最大間隔的優化模型
現在我們已經知道了如何去求資料點到超平面的距離,在超平面確定的情況下,我們就能夠找出所有支援向量,然後計算出間隔margin。每一個超平面都對應著一個margin,我們的目標就是找出所有margin中最大的那個值對應的超平面。因此用數學語言描述就是確定w、b使得margin最大。這是一個優化問題其目標函式可以寫成:
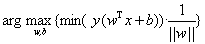
其中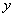
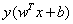
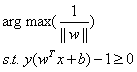
為了後面計算的方便,我們將目標函式等價替換為:
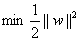
這是一個凸二次規劃問題。能直接用現成的優化計算包求解,但我們可以有更高效的辦法。
2.3 學習的對偶演算法
為了求解線性可分支援向量機的最優化問題,將它作為原始最優化問題,應用拉格朗日對偶性,通過求解對偶問題得到原始問題的最優解,這就是線性可分支援向量的對偶演算法。這樣的優點:
-
對偶問題往往更容易求解
-
自然引入核函式,進而推廣到非線性分類問題
-
改變了問題的複雜度。由求特徵向量w轉化為求比例係數a,在原始問題下,求解的複雜度與樣本的維度有關,即w的維度。在對偶問題下,只與樣本數量有關。
首先構建拉格朗日函式。為此,對每個不等式約束引進拉格朗日乘子$a_{i}\geq 0,i=1,2,...,N$,定義拉格朗日函式:
$L(w,b,a)=\frac{1}{2}\left \| w \right \|^{2}-\sum_{i=1}^{N}a\left [ (w^{T}+b)-1 \right ]$ (6)
其中$a_{i}> 0$。
根據拉格朗日函式對偶性,原始問題的對偶問題是極大極小問題:
$max_{a}min_{w,b}L(w,b,a)$ (7)
所以,為了求解問題的解,需要先求求$L(w,b,a)$對$w,b$的極小,再求對$a$的極大。
(1) 求$min_{w,b}L(w,b,a)$
將拉格朗日函式$L(w,b,a)$分別對$w,b$求偏導數令其等於0:
$\bigtriangledown _{w}L(w,b,a)=w-\sum_{i=1}^{N}a_{i}y_{i}x_{i}=0$ (8)
$\bigtriangledown _{b}L(w,b,a)=\sum_{i=1}^{N}a_{i}y_{i}=0$ (9)
得:
$w=\sum_{i=1}^{N}a_{i}y_{i}x_{i}$(10)
$\sum_{i=1}^{N}a_{i}y_{i}=0$(11)
將式(10)代入拉格朗日函式(6)並利用式(11),即得:
$L(w,b,a)=\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}x_{j})-\sum_{i=1}^{N}a_{i}\left [ y_{i} \right ((\sum_{j=1}^{N}a_{i}y_{j}x_{j})x_{i}+b)-1]+\sum_{i=1}^{N}a_{i}
=-\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}\cdot x_{j})+\sum_{i=1}^{N}a_{i}$ (12)
(2) 求$max_{w,b}L(w,b,a)$對$a$的極大
$max_{a} \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}\cdot x_{j})+\sum_{i=1}^{N}a_{i}$ (13)
subject to
$\sum_{i=1}^{N}a_{i}y_{i}=0$
$a_{i}\geq 0,i=1,2,...,N$
將上式的目標函式由極大轉換成極小,就得到下面與之等價的對偶最優化問題:
$min_{a} \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}a_{i}a_{j}y_{i}y_{j}(x_{i}\cdot x_{j})+\sum_{i=1}^{N}a_{i}$ (14)
subject to
$\sum_{i=1}^{N}a_{i}y_{i}=0$
$a_{i}\geq 0,i=1,2,...,N$
從對偶問題解出的是原式中的拉格朗日乘子。注意到原式中有不等式約束,因此上述過程需要滿足KKT條件,即要求:
$\left\{\begin{matrix}
a_{i}\geq 0\\
y_{i}f(x_{i})-1\geq 0\\
a_{i}(y_{i}f(x_{i})-1)=0
\end{matrix}\right.$ (15)
於是,對於訓練資料$(x_{i},y_{i})$,總有$a_{i}=0$或$y_{i}f(x_{i})=1$。若$a_{i}=0$,則該樣本不會出現在上述求和公式中,也就不會對$f(x)$產生任何影響;若$a_{i}>0$則必有$y_{i}f(x_{i})=1$,所對應樣本點位於最大間隔上,是一個支撐向量。這裡顯示出支援向量機的一個重要性質:訓練完成後,大部分的訓練樣本都不需保留,最終模型僅與支援向量相關。
那麼如何求解式(14)不難發現,這是一個二次規劃問題,可使用通用的二次規劃演算法求解;然而,該問題的規模正比於訓練樣本數,這會在實際任務中造成很大的開銷。為了避開這個障礙,人們通過利用問題本身的特性,提出了很多高校的演算法,SMO(Sequential Minimal Optimization)是其中一個著名的代表。
2.4 鬆弛變數
由上一節的分析我們知道實際中很多樣本資料都不能夠用一個超平面把資料完全分開。如果資料集中存在噪點的話,那麼在求超平的時候就會出現很大問題。從下圖中可以看出其中一個藍點偏差太大,如果把它作為支援向量的話所求出來的margin就會比不算入它時要小得多。更糟糕的情況是如果這個藍點落在了紅點之間那麼就找不出超平面了。
因此引入一個鬆弛變數ξ來允許一些資料可以處於分隔面錯誤的一側。這時新的約束條件變為:
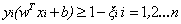
式中ξi的含義為允許第i個數據點允許偏離的間隔。如果讓ξ任意大的話,那麼任意的超平面都是符合條件的了。所以在原有目標的基礎之上,我們也儘可能的讓ξ的總量也儘可能地小。所以新的目標函式變為:
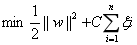
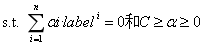
其中的C是用於控制“最大化間隔”和“保證大部分的點的函式間隔都小於1”這兩個目標的權重。將上述模型完整的寫下來就是:
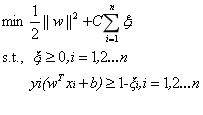
新的拉格朗日函式變為:
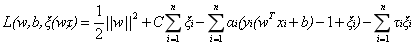
接下來將拉格朗日函式轉化為其對偶函式,首先對
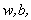
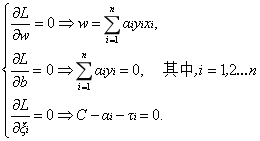
代入原式化簡之後得到和原來一樣的目標函式:
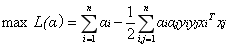
但是由於我們得到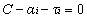
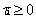
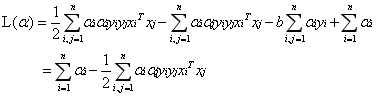
經過新增鬆弛變數的方法,我們現在能夠解決資料更加混亂的問題。通過修改引數C,我們可以得到不同的結果而C的大小到底取多少比較合適,需要根據實際問題進行調節。
2.5核函式
以上討論的都是線上性可分情況進行討論的,但是實際問題中給出的資料並不是都是線性可分的,比如有些資料可能是如下圖樣子。
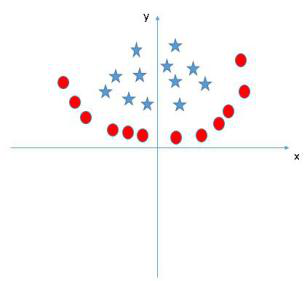
那麼這種非線性可分的資料是否就不能用svm演算法來求解呢?答案是否定的。事實上,對於低維平面內不可分的資料,放在一個高維空間中去就有可能變得可分。以二維平面的資料為例,我們可以通過找到一個對映將二維平面的點放到三維平面之中。理論上任意的資料樣本都能夠找到一個合適的對映使得這些在低維空間不能劃分的樣本到高維空間中之後能夠線性可分。我們再來看一下之前的目標函式:
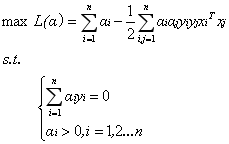
定義一個對映使得將所有對映到更高維空間之後等價於求解上述問題的對偶問題:
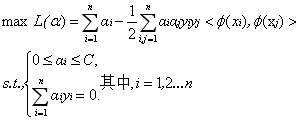
這樣對於線性不可分的問題就解決了,現在只需要找出一個合適的對映即可。當特徵變數非常多的時候在,高維空間中計算內積的運算量是非常龐大的。考慮到我們的目的並不是為找到這樣一個對映而是為了計算其在高維空間的內積,因此如果我們能夠找到計算高維空間下內積的公式,那麼就能夠避免這樣龐大的計算量,我們的問題也就解決了。實際上這就是我們要找的核函式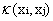
通過以上例子,我們可以很明顯地看到核函式是怎樣運作的。上述問題的對偶問題可以寫成如下形式:
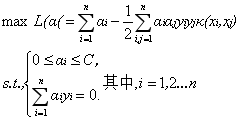
那麼怎樣的函式才可以作為核函式呢?下面的一個定理可以幫助我們判斷。
Mercer定理:任何半正定的函式都可以作為核函式。其中所謂半正定函式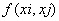
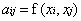
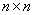
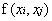
值得注意的是,上述定理中所給出的條件是充分條件而非充要條件。因為有些非正定函式也可以作為核函式。
下面是一些常用的核函式:
|
核函式名稱 |
核函式表示式 |
核函式名稱 |
核函式表示式 |
|
線性核 |
|
指數核 |
|
|
多項式核 |
|
拉普拉斯核 |
|
|
高斯核 |
|
Sigmoid核 |
|

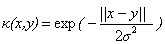
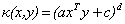
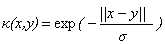
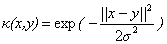
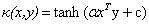
現在我們已經瞭解了一些支援向量機的理論基礎,我們通過對偶問題的的轉化將最開始求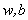
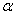
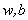
三、SMO 演算法
SMO演算法是支援向量機學習的一種快速演算法,其特點是不斷地將原二次規劃問題分解為只有兩個變數的二次規劃子問題,並對子問題進行解析求解,知道所有變數滿足KKT條件為止。這樣通過啟發式的方法得到原二次規劃問題的最優解。因為子問題有解析解,所以每次計運算元問題都很快,雖然計運算元問題次數很多,但在總體上還是高效的。
參考
《統計學習方法(第2版)》 李航 著
https://zhuanlan.zhihu.com/p/31886934
https://www.cnblogs.com/xfydjy/p/9065541.html
https://www.zybuluo.com/77qingliu/note/1137445
http://www.360doc.com/content/18/0424/21/47919125_748467297.s