
大資料推薦系統實時架構和離線架構
生活中無論有什麼閃失,統統是自己的錯,與人無尤,從錯處學習改過,精益求精,直至不犯同一錯誤,從不把過失推諉到他人肩膀上去,免得失去學乖的機會。——《阿修羅》
1、概述
推薦系統是大資料中最常見和最容易理解的應用之一,比如說淘寶的猜你喜歡和京東等網站的使用者提供個性化的內容。但是不僅僅只有電商會用推薦引擎為使用者提供額外的商品,推薦系統也可以被用在其他行業,以及具有不同的應用中使用,如網易雲音樂的每日歌曲推薦、活動、產品到約會物件。
2、大資料推薦系統架構
一般中型的網站(10W的PV以上),每天會產生1G以上Web日誌檔案。大型或超大型的網站,可能每小時就會產生10G的資料量。
具體來說,比如某電子商務網站,在線團購業務。每日PV數100w,獨立IP數5w。使用者通常在工作日上午10:00-12:00和下午15:00-18:00訪問量最大。日間主要是通過PC端瀏覽器訪問,休息日及夜間通過移動裝置訪問較多。網站搜尋瀏量佔整個網站的80%,PC使用者不足1%的使用者會消費,移動使用者有5%會消費。
對於日誌的這種規模的資料,用HADOOP進行日誌分析,是最適合不過的了。通過日誌分析,增加銷售量,出售更多不同的商品,提升使用者滿意度,更好的理解使用者想要什麼。下面是推薦系統離線模式和實時模式的推薦架構。兩種架構經常是相互輔助使用。
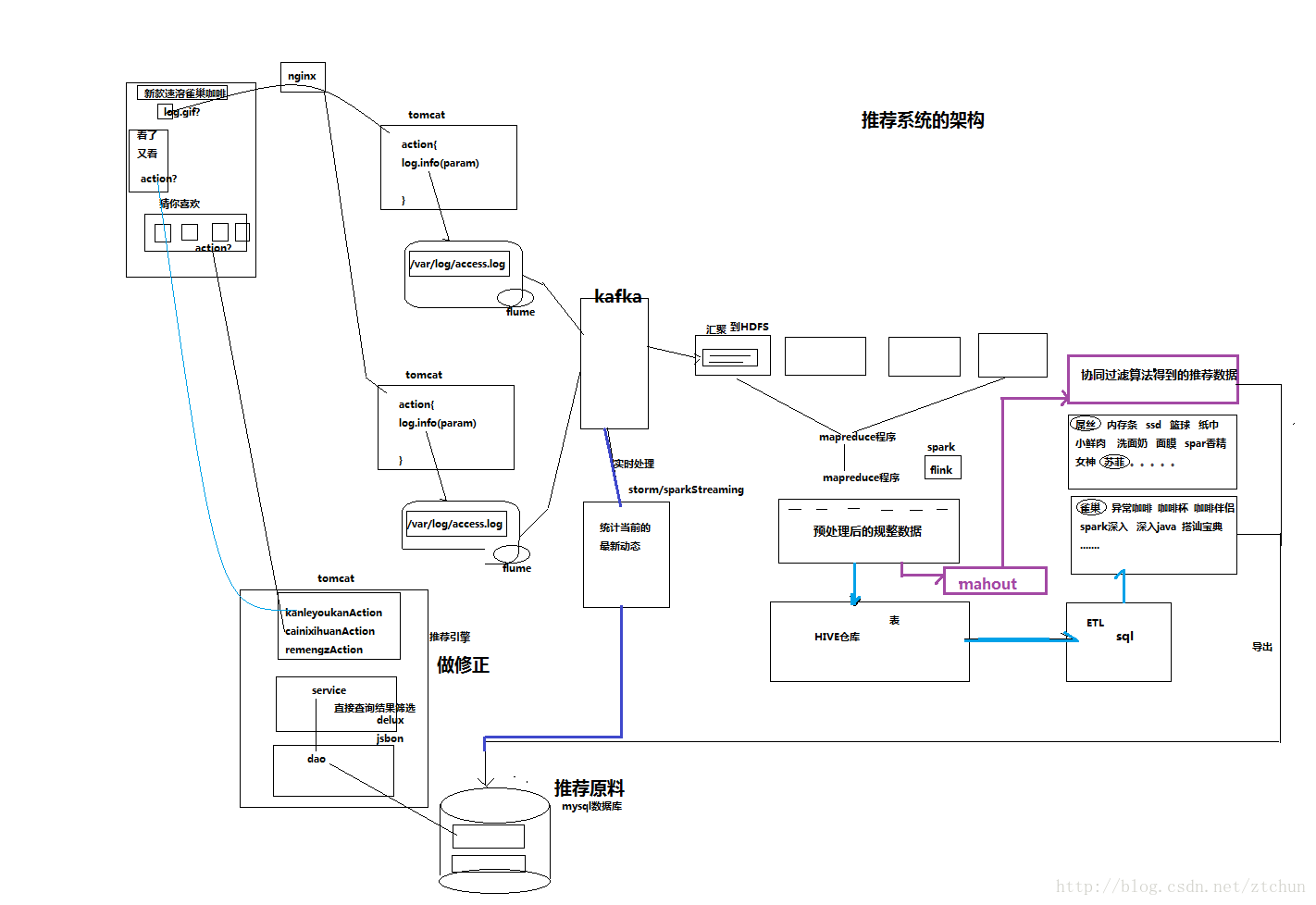
2.1 離線模式過程
(1)資料來源
在頁面預埋一段js程式,為頁面上想要監聽的標籤繫結事件,只要使用者點選或移動到標籤,即可觸發ajax請求到後臺servlet程式,用log4j記錄下事件資訊,從而在web伺服器(nginx、tomcat等)上形成不斷增長的日誌檔案。在移動裝置上,通過訪問介面,後端記錄訪問日誌。
(2)資料採集
定製開發採集程式,或使用開源框架FLUME,flume是分散式的日誌收集系統,它將各個伺服器中的資料收集起來並送到指定的地方去,比如說送到圖中的HDFS,簡單來說flume就是收集日誌的。
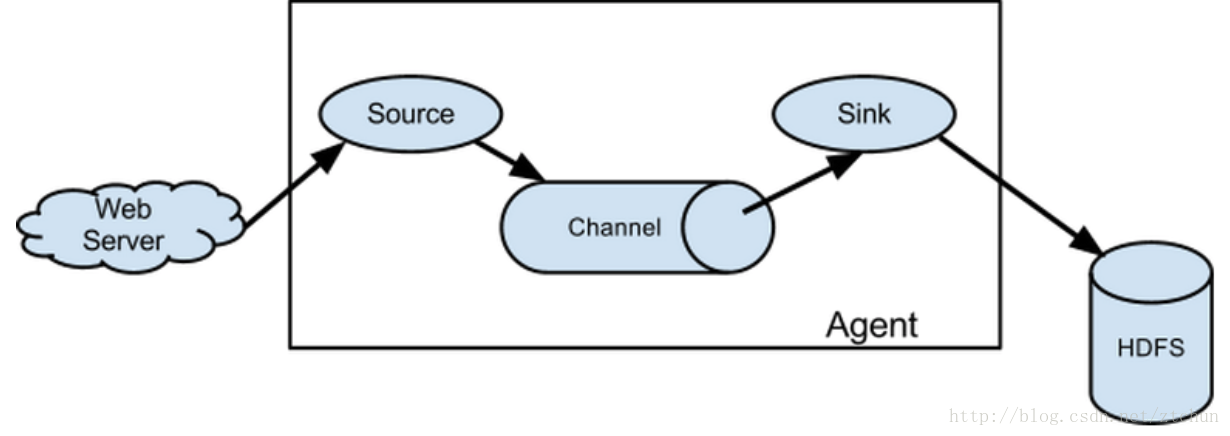
flume之所以這麼神奇,是源於它自身的一個設計,這個設計就是agent,agent本身是一個java程序,執行在日誌收集節點—所謂日誌收集節點就是伺服器節點。
agent裡面包含3個核心的元件:source—->channel—–>sink,類似生產者、倉庫、消費者的架構。
source:source元件是專門用來收集資料的,可以處理各種型別、各種格式的日誌資料,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定義。
channel:source元件把資料收集來以後,臨時存放在channel中,即channel元件在agent中是專門用來存放臨時資料的——對採集到的資料進行簡單的快取,可以存放在memory、jdbc、file等等。
sink:sink元件是用於把資料傳送到目的地的元件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定義
(3)資料匯聚
原始日誌通過flume匯聚到HDFS分散式儲存系統。
(4)資料預處理
定製開發mapreduce程式運行於hadoop叢集,得到規整資料放入hdfs。
(5)資料倉庫技術
基於hadoop之上的Hive,將規整資料對映成表。
(6)ETL
在hive進行資料查詢,寫sql匯出結果。或者通過mahout機器學習演算法分析出推薦資料寫入到推薦原料。例如,協同過濾演算法。
(7)推薦引擎
將推薦結果匯入到業務資料庫,web推薦引擎根據資料庫進行推薦。
(8)視覺化顯示
根據業務資料庫的推薦資訊,前端顯示推薦結果。
2.2 實時模式過程
熱門事件,爆款。需要實時推薦。
(1)資料來源
在頁面預埋一段js程式,為頁面上想要監聽的標籤繫結事件,只要使用者點選或移動到標籤,即可觸發ajax請求到後臺servlet程式,用log4j記錄下事件資訊,從而在web伺服器(nginx、tomcat等)上形成不斷增長的日誌檔案。在移動裝置上,通過訪問介面,後端記錄訪問日誌。
(2)資料採集
定製開發採集程式,或使用開源框架FLUME,flume是分散式的日誌收集系統,它將各個伺服器中的資料收集起來並送到指定的地方去,比如說HDFS,簡單來說flume就是收集日誌的。
(3)資料匯聚
原始日誌通過flume匯聚到kafka叢集。一部分資料傳送給storm實時處理,另一部分發送給hdfs做離線處理。
(4)實時處理
通過storm和sparkStreaming讀取kafka的訊息進行資料實時處理,統計當前的最新動態到推薦原料。
(5)推薦引擎
將推薦結果匯入到業務資料庫,web推薦引擎根據資料庫進行推薦。
(6)視覺化顯示
根據業務資料庫的推薦資訊,前端顯示推薦結果。
3、總結
個性化產品推薦
推薦系統幫助理解每一位訪問者的喜好和意圖,並及時地展示相關的推薦型別和商品。隨著引擎對每位訪問者瞭解到更多,推薦系統也就得到了提升。
網站個性化
允許以實時區分和定位使用者的個性化訊息與提醒來增加銷量和轉化。
及時通知
這樣的引擎幫助品牌建立與使用者之間的信任,並在顧客訪問網站時通過及時展示通知構造一種存在感和緊迫感。
個性化的客戶忠誠度專案和服務
研究表明,與千篇一律的內容相比,人們對提供個性化服務的專案更感興趣,與客戶忠誠度有關的專案更是如此。這樣的引擎基於與使用者的實時互動能夠定製推薦內容。資料分析演算法運用不同的購買行為並整合上下文資訊來關注不同的產品策略,這也提升了推薦的質量。