
Win10系統下spark的環境搭建
阿新 • • 發佈:2019-01-05
環境準備
·jdk配置;
·scala安裝與配置;
·spark安裝與配置;
·hadoop安裝與配置;
版本說明
·jdk:1.8
·scala:2.11.8
·spark:2.4.0
·hadoop:2.8.3
jdk配置
- 首先,進入我的電腦-〉系統屬性-〉高階系統設定->環境變數
配置JAVA_Home
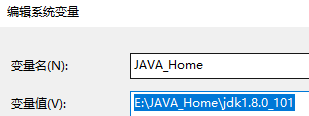
配置Path

- 驗證配置

scala安裝與配置
- scala下載
官方地址:https://www.scala-lang.org/download/2.11.8.html

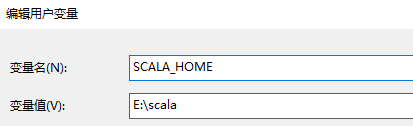
- 配置使用者變數下的Path
變數值一欄輸入:E:\scala 也就是scala的安裝目錄
注意:安裝路徑不能有空格和中文,否則報錯,出現報錯需要解除安裝重灌
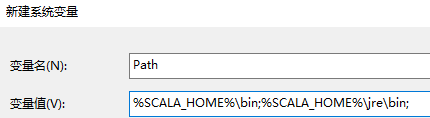
- 配置系統變數下的Path變數
在"變數值"一欄的最前面新增如下的路徑: %SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;
注意:後面的分號 ; 不要漏掉。
- 設定系統變數下的Classpath 變數:
· “變數名”:ClassPath
· “變數值”:
· .;%SCALA_HOME%\bin;%SCALA_HOME%\lib\dt.jar;%SCALA_HOME%\lib\tools.jar.;

- 驗證配置

spark安裝與配置
- spark下載:http://spark.apache.org/downloads.html
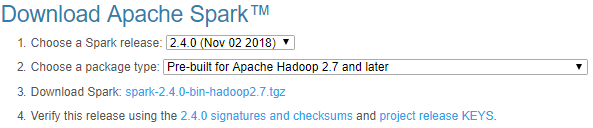
選擇3,進入下載頁面 ,選擇預設下載

- 下載完畢後解壓到D:
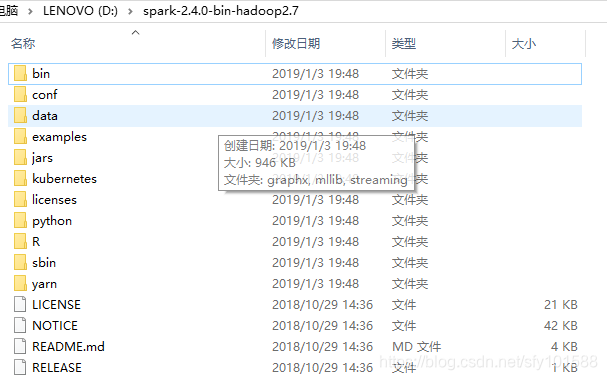
- 配置Path
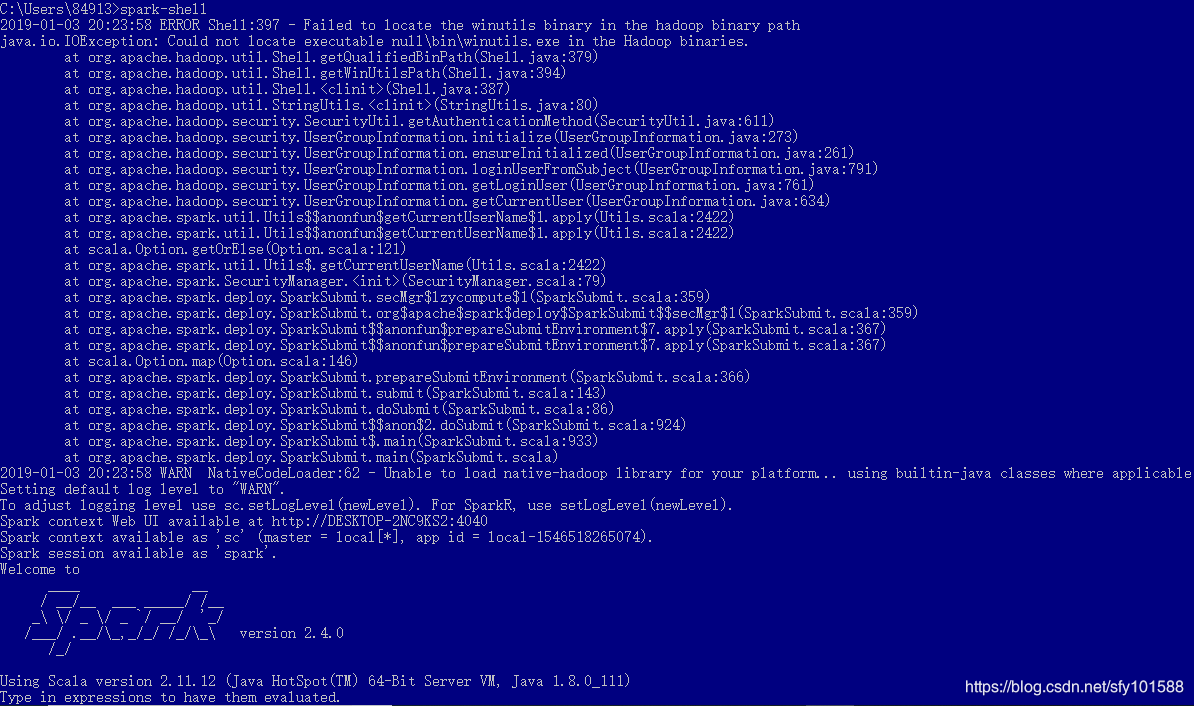
如上,可以看到對應的spark、scala、java版本,同時存在異常資訊,異常資訊是由於hadoop導致的,下面來配置hadoop即可解決該異常。
Hadoop安裝與配置
- Hadoop官網下載:http://hadoop.apache.org/releases.html
- 解壓Hadoop
- 配置Path
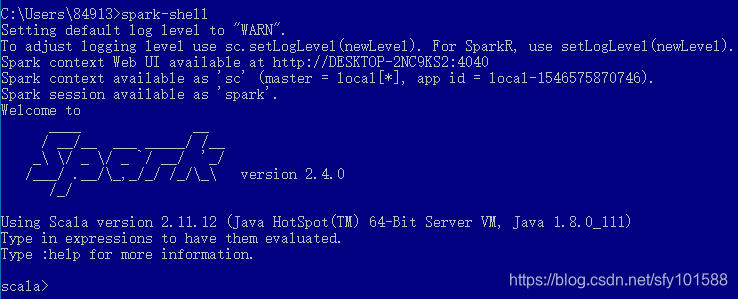
- 驗證配置
基於spark用線性迴歸進行資料預測
分類和聚類演算法很多,但是對資料進行精準預測的演算法不是很多,這裡參照了別人的線性迴歸的例子,使用spark ml進行線性迴歸。
資料格式
標籤,特徵值1 特徵值2 特徵值3...
1. 1,1.9
2. 2,3.1
3. 3,4
4. 3.5,4.45
5. 4,5.02
6. 9,9.97
7. -2,-0.98
實現程式碼如下
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
val data_path = "files/C:/Users/84913/Desktop/sfy/linear_regression_data1.txt"
val data = sc.textFile(data_path)
val training = data.map { line =>
val arr = line.split(',')
LabeledPoint(arr(0).toDouble, Vectors.dense(arr(1).split(' ').map(_.toDouble)))
}.cache()
training.foreach(println)
結果
(1.0,[1.9])
(2.0,[3.1])
(3.0,[4.0])
(3.5,[4.45])
(4.0,[5.02])
(9.0,[9.97])
(-2.0,[-0.98])