
Deep learning系列(七)啟用函式
阿新 • • 發佈:2019-01-06
1. sigmoid啟用函式
sigmoid將一個實數輸入對映到[0,1]範圍內,如下圖(左)所示。使用sigmoid作為啟用函式存在以下幾個問題:
- 梯度飽和。當函式啟用值接近於0或者1時,函式的梯度接近於0。在反向傳播計算梯度過程中:δ(l)=(W(l))Tδ(l+1)∗f′(z(L)),每層殘差接近於0,計算出的梯度也不可避免地接近於0。這樣在引數微調過程中,會引起引數彌散問題,傳到前幾層的梯度已經非常靠近0了,引數幾乎不會再更新。
- 函式輸出不是以0為中心的。我們更偏向於當啟用函式的輸入是0時,輸出也是0的函式。
因為上面兩個問題的存在,導致引數收斂速度很慢,嚴重影響了訓練的效率。因此在設計神經網路時,很少採用sigmoid啟用函式。
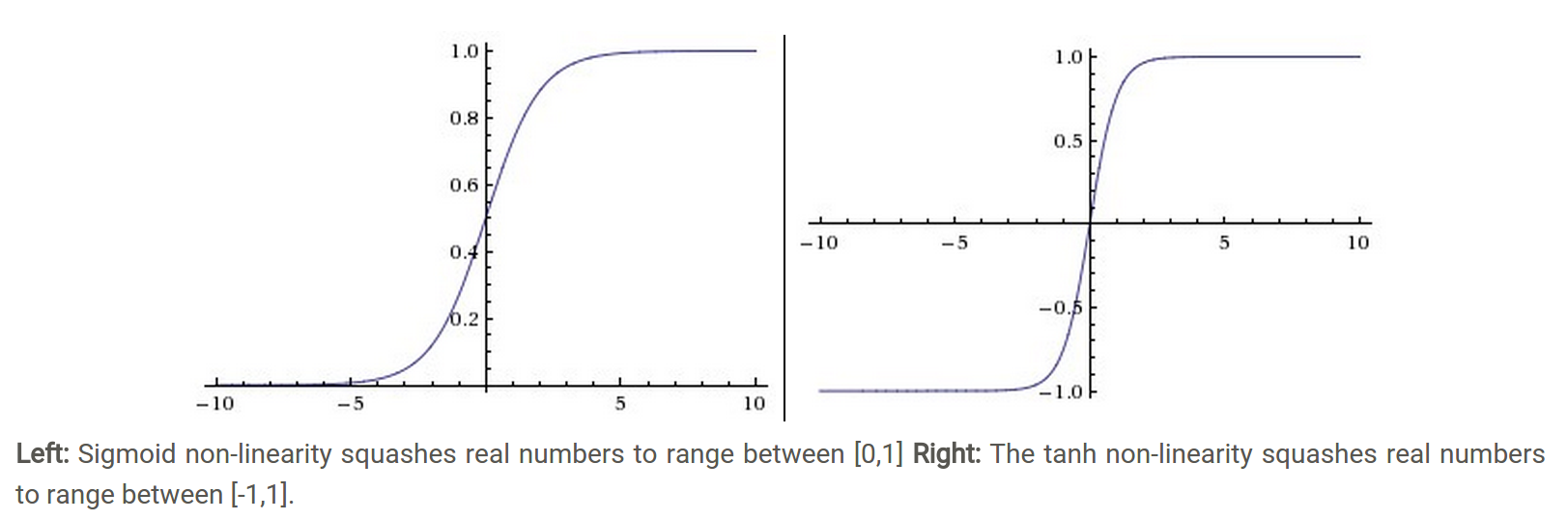
2. tanh啟用函式
tanh函式將一個實數輸入對映到[-1,1]範圍內,如上圖(右)所示。當輸入為0時,tanh函式輸出為0,符合我們對啟用函式的要求。然而,tanh函式也存在梯度飽和問題,導致訓練效率低下。
3.Relu啟用函式
Relu啟用函式(The Rectified Linear Unit)表示式為:f(x)=max(0,x)。如下圖(左)所示:
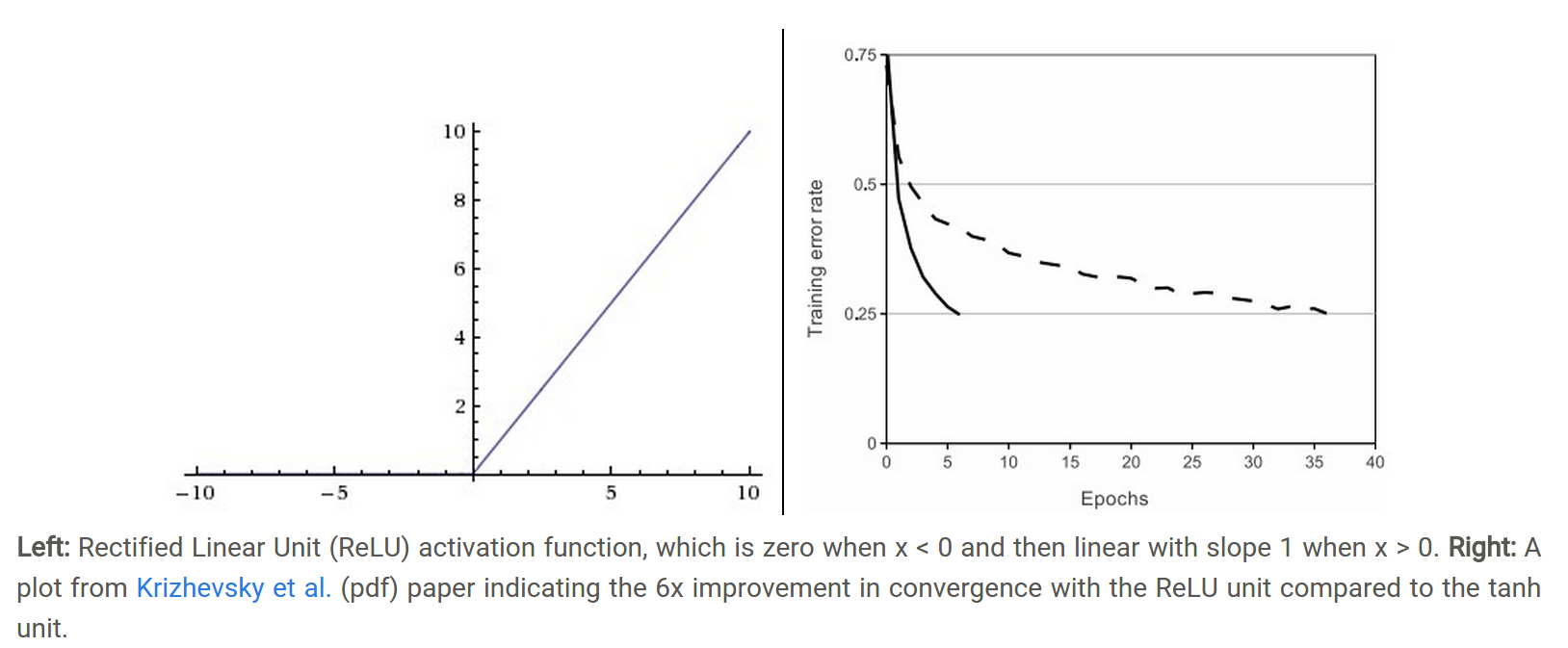
相比sigmoid和tanh函式,Relu啟用函式的優點在於:
- 梯度不飽和。梯度計算公式為:1{x>0}。因此在反向傳播過程中,減輕了梯度彌散的問題,神經網路前幾層的引數也可以很快的更新。
- 計算速度快。正向傳播過程中,sigmoid和tanh函式計算啟用值時需要計算指數,而Relu函式僅需要設定閾值。如果x<0,f(x)=0,如果x>0,f(x)=x。加快了正向傳播的計算速度。
因此,Relu啟用函式可以極大地加快收斂速度,相比tanh函式,收斂速度可以加快6倍(如上圖(右)所示)。
參考資料:
1. http://cs231n.stanford.edu/syllabus.html
2. Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. NIPS. 2012: 1097-1105.