
Deep learning系列(十五)有監督和無監督訓練
1. 前言
在學習深度學習的過程中,主要參考了四份資料:
對比過這幾份資料,突然間產生一個困惑:臺大和Andrew的教程中用了很大的篇幅介紹了無監督的自編碼神經網路,但在Li feifei的教程和caffe的實現中幾乎沒有涉及。當時一直搞不清這種現象的原因,直到翻閱了深度學習的發展史之後,才稍微有了些眉目。
深度學習的發展大致分為這麼幾個時期:
- 萌芽期。從BP演算法的發明(1970s-1980s)到2006年期間。
- 迅速發展期。從2006年棧式自編碼器+BP微調提出之後。
- 爆發期。2012年Hilton團隊的Alexnet模型在imagenet競賽取得驚人成績之後。
2. 萌芽期
在Yann LeCun、Yoshua Bengio和Geoffrey Hinton三巨頭nature深度學習綜述
這期間,學者們試圖用有監督學習的方式訓練深度神經網路,然而方法不是十分奏效,陷入了困境,在Andrew的教程中可以找到大概這幾點原因:
- 資料獲取問題。有監督訓練需要依賴於有標籤的資料才能進行訓練。然而有標籤的資料通常是稀缺的,因此對於許多問題,很難獲得足夠多的樣本來擬合一個複雜模型的引數。例如,考慮到深度網路具有強大的表達能力,在不充足的資料上進行訓練將會導致過擬合。
- 區域性極值問題。使用監督學習方法來對淺層網路(只有一個隱藏層)進行訓練通常能夠使引數收斂到合理的範圍內。但是當用這種方法來訓練深度網路的時候,並不能取得很好的效果。特別的,使用監督學習方法訓練神經網路時,通常會涉及到求解一個高度非凸的優化問題。對深度網路而言,這種非凸優化問題的搜尋區域中充斥著大量“壞”的區域性極值,因而使用梯度下降法(或者像共軛梯度下降法,L-BFGS等方法)效果並不好。
- 梯度彌散問題。梯度下降法在使用隨機初始化權重的深度網路上效果不好的技術原因是:梯度會變得非常小。具體而言,當使用反向傳播方法計算導數的時候,隨著網路的深度的增加,反向傳播的梯度(從輸出層到網路的最初幾層)的幅度值會急劇地減小。結果就造成了整體的損失函式相對於最初幾層的權重的導數非常小。這樣,當使用梯度下降法的時候,最初幾層的權重變化非常緩慢,以至於它們不能夠從樣本中進行有效的學習。這種問題通常被稱為“梯度的彌散”。
因為一直沒找到有效解決這些問題的方法,這期間,深度神經網路的發展一直不溫不火。或者說在2001年Hochreiter的Gradient flow in recurrent nets: the difficulty of learning long-term dependencies
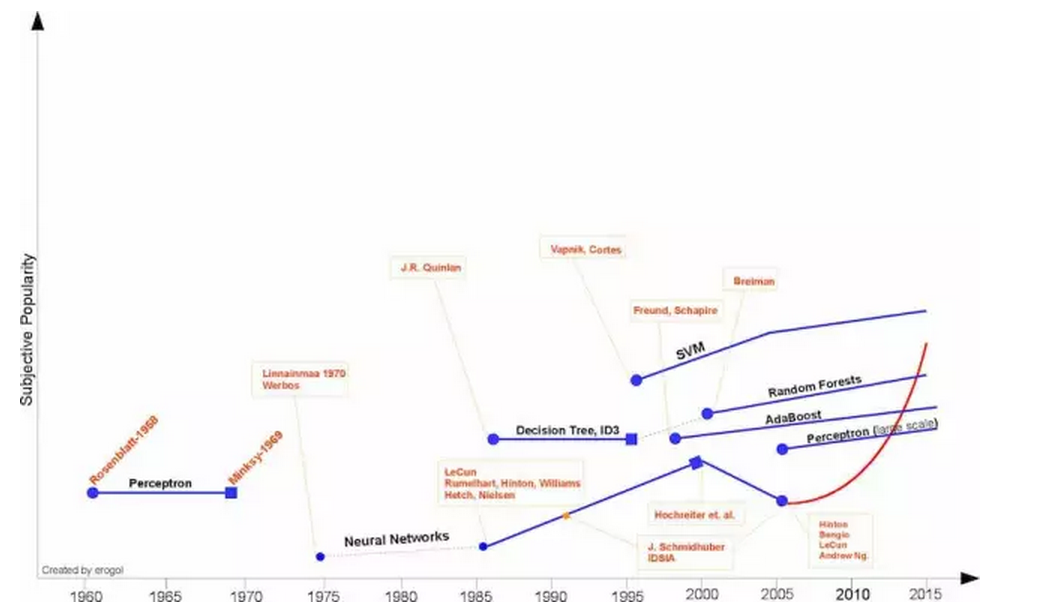
3. 迅速發展期
06年Hilton在nature上發表了一篇文章Reducing the dimensionality of data with neural networks,針對上面提到的三個深度學習問題,提出了棧式自編碼器+BP微調的解決方案。在一定程度上解決了上面的三個問題:
- 棧式自編碼神經網路是無監督學習演算法。因而不需要規模很大的有標籤樣本。
- 經過自編碼神經網路訓練後的引數已經落在一個較優的位置上,從這個位置開始BP微調,不用擔心區域性極值問題。
- 自編碼神經網路訓練已經使深度網路的前幾層引數具有表達能力了,比如可以提取出圖片的邊,區域性組建等,即使有梯度彌散問題,前幾層引數不再更新,也不會影響最終深度網路的表達能力。
因為上面的原因,在經歷01年神經網路的低谷後,深度學習開啟的嶄新的浪潮,走上了發展的快車道,從上圖的紅線可以明顯的看出。
4. 爆發期
在12年的ILSVRC競賽中,Hilton團隊的Alexnet模型Imagenet classification with deep convolutional neural networks將1000類分類的top-5誤差率降低到了15.3%,碾壓了第二名使用SVM演算法的26.2%,開啟了深度學習的革命,從此之後,深度學習走上了指數式的發展道路。在15年CVPR的文章中,我關注的兩個方向場景語義標註和顯著物體檢測,有相當大比例的文章中涉及CNN或者deep的字眼,估計明年CVPR文章中深度學習的比例會更高。工業界的火爆就不用多提了,從Yann LeCun、Yoshua Bengio和Geoffrey Hinton三巨頭到顏水成、li feifei這樣的視覺方向大牛都被挖到網際網路公司就可見一斑。
回到Hilton團隊的Alexnet模型上,僅僅使用了有監督的訓練,貌似沒涉及無監督的預訓練。不是在之前說有監督的深度學習訓練存在很多問題嗎,大概是因為這幾條原因,導致了有監督訓練的可行:
- 大規模標註資料的出現。在ILSVRC使用的資料集包括120萬的訓練圖片,5萬張驗證圖片和15萬張測試圖片。這些圖片都是有標註的(屬於1000類),而在imagenet出現之前,這樣規模的標註資料是不存在的。
- 對於區域性極值的問題,nature綜述中,三個大牛作者的說法是:對於深度網路來說,區域性極值從來都不是一個問題,從任意的初始引數值開始訓練網路,最後都能達到相似的分類效果。這也是被最近的理論和實踐所證明的。
- 對於梯度彌散導致的收斂速度慢問題。Alexnet模型的兩大利器:ReLU啟用函式和GPU並行加速。前者使SGD有6倍的加速,後者使用兩塊GTX580GPU也極大的加快了SGD的收斂速度,兩者效果相乘,使得無監督預訓練幾乎是多餘的了,梯度彌散問題也不再是一個很大的問題。
5. 總結
從上面介紹可以看出,Andrew NG的教程是06年到12年之間的產物,當時無監督訓練是主流,Li feifei的CNN教程和caffe官網的教程是產生於12年之後,這時資料庫足夠大(上千萬級別),模型足夠先進(ReLU啟用函式,dropout等等),同時計算速度足夠快(GPU加速),使得無監督預訓練(自編碼神經網路)在很多應用場景中失去了存在的價值,有監督訓練已足夠完成任務。
一句話總結,06年的無監督預訓練開啟了深度學習的紀元,在之後深度學習快速發展的過程中,大資料的獲得、計算機硬體的發展以及深度模型的升級使得有監督訓練重新走上舞臺,無監督預訓練也算是完成了歷史使命。
那預訓練還有用嗎?答案是肯定的,比如我們有一個分類任務,資料庫很小,這時還是需要通過預訓練來避免深度模型的過擬合問題的,只不過預訓練是通過在一個大的資料庫上(比如imagenet),通過有監督的訓練來完成的。這種有監督預訓練加小的資料庫上微調的模式稱為Transfer learning,在Li feifei的CNN教程和caffe官網的教程中都有詳細的介紹。
除此之外,Andrew NG的教程也有其它幾點常用於12年之前但現在很少用的細節,比如這個教程中介紹的啟用函式是sigmoid,現在很少見了,幾乎被ReLU啟用函式取代,優化演算法用的是L-BFGS,現在的優化演算法主流是SGD+momentum。這些教程之間的不同點在當時學習之初是很困惑的,直到明白了深度學習的發展歷程,才漸漸瞭解這些不同的來源。