
基於nodejs的網路圖片爬蟲
阿新 • • 發佈:2019-01-06
這是我研究nodejs爬蟲後寫的一個圖片爬蟲小例子。不過功能還是挺強大的可以將你喜歡的圖片下載下來。
主要的爬蟲程式碼:
//var http = require('https');
var http = require('http');
var fs = require('fs');
var cheerio = require('cheerio');
var request = require('request');
//設定迴圈
var i = 0;
//初始url
var url = "http://m.juyouqu.com/qu/3187982";
function startSpider(x) { 執行的截圖:
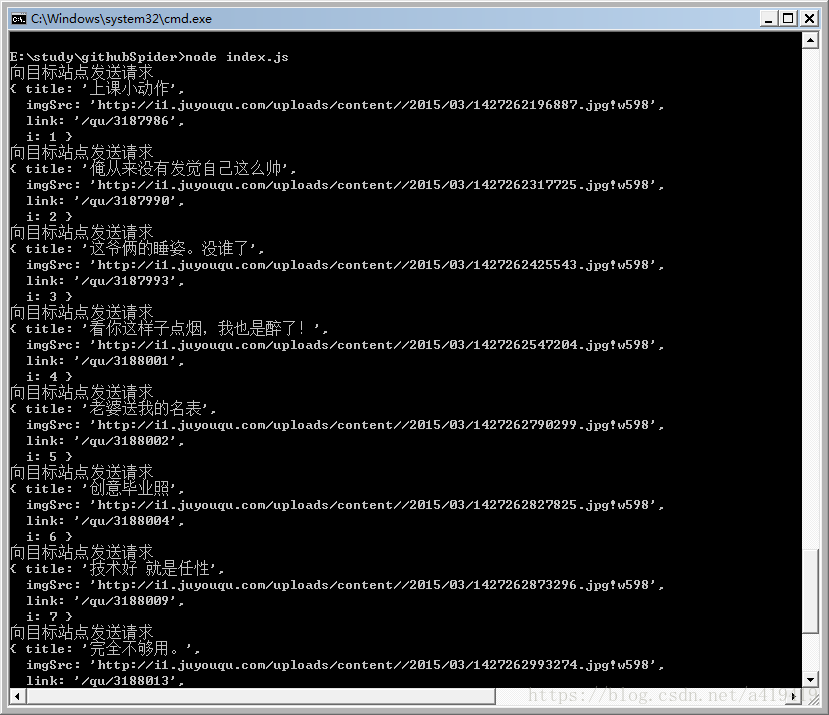
獲得的圖片:
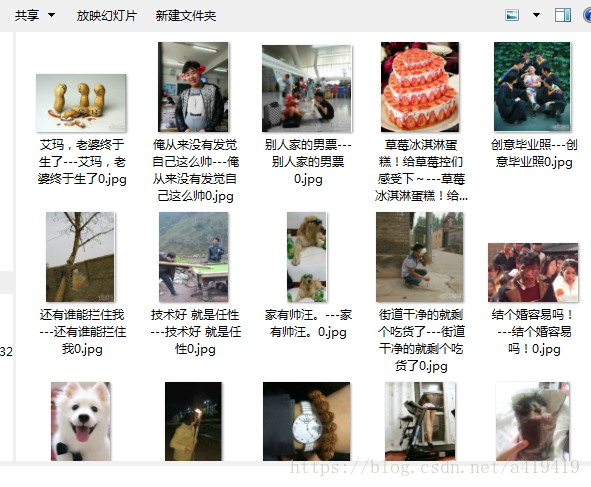
如果看不懂,或者配置不了的話,可以下載我的資源包,整個專案的完整程式碼我都放上去了。
這是資源地址
(解壓後,如果node_modules裡面你檔案路徑與你電腦的路徑不符,你可以刪除了node_modules這個檔案然後在執行一下npm install就可以了)