
邊緣檢測︱基於 HED網路TensorFlow 和 OpenCV 實現圖片邊緣檢測
.
一、邊緣檢測
1、傳統邊緣檢測
Google 搜尋 opencv scan document,是可以找到好幾篇相關的教程的,這些教程裡面的技術手段,也都大同小異,關鍵步驟就是呼叫 OpenCV 裡面的兩個函式,cv2.Canny() 和 cv2.findContours()。
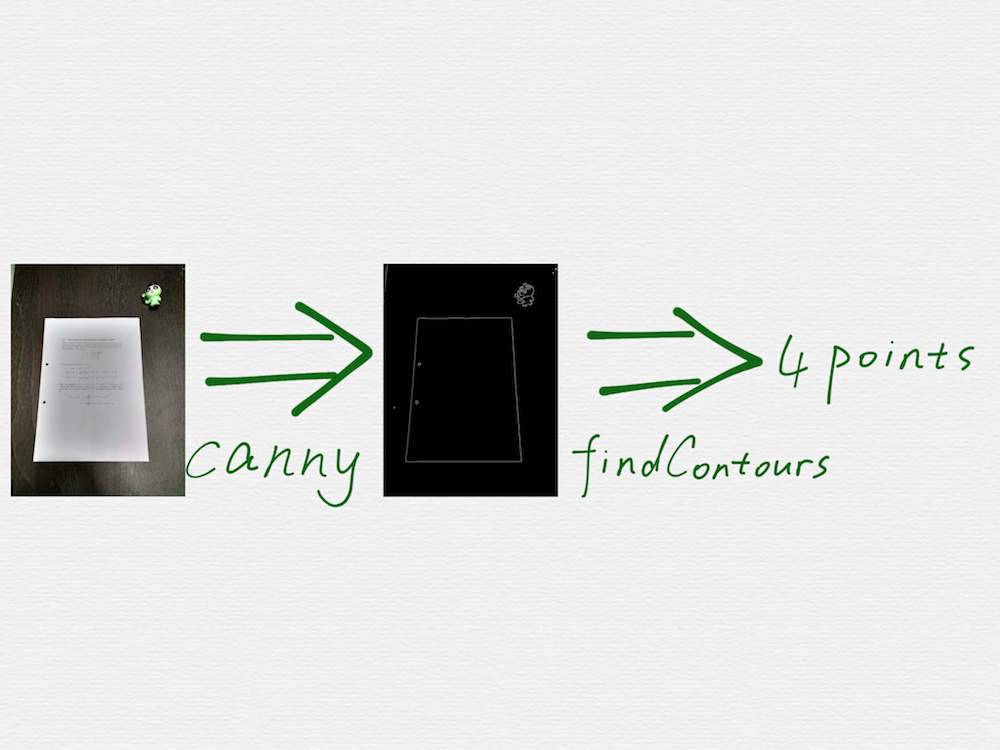
看上去很容易就能實現出來,但是真實情況是,這些教程,僅僅是個 demo 演示而已,用來演示的圖片,都是最理想的簡單情況,真實的場景圖片會比這個複雜的多,會有各種干擾因素,呼叫 canny 函式得到的邊緣檢測結果,也會比 demo 中的情況凌亂的多,比如會檢測出很多各種長短的線段,或者是文件的邊緣線被截斷成了好幾條短的線段,線段之間還存在距離不等的空隙。另外,findContours 函式也只能檢測閉合的多邊形的頂點,但是並不能確保這個多邊形就是一個合理的矩形。因此在我們的第一版技術方案中,對這兩個關鍵步驟,進行了大量的改進和調優,概括起來就是:
改進 canny 演算法的效果,增加額外的步驟,得到效果更好的邊緣檢測圖
針對 canny 步驟得到的邊緣圖,建立一套數學演算法,從邊緣圖中尋找出一個合理的矩形區域
.
2、傳統技術方案的難度和侷限性
canny 演算法的檢測效果,依賴於幾個閾值引數,這些閾值引數的選擇,通常都是人為設定的經驗值,在改進的過程中,引入額外的步驟後,通常又會引入一些新的閾值引數,同樣,也是依賴於除錯結果設定的經驗值。整體來看,這些閾值引數的個數,不能特別的多,因為一旦太多了,就很難依賴經驗值進行設定,另外,雖然有這些閾值引數,但是最終的引數只是一組或少數幾組固定的組合,所以演算法的魯棒性又會打折扣,很容易遇到邊緣檢測效果不理想的場景
在邊緣圖上建立的數學模型很複雜,程式碼實現難度大,而且也會遇到演算法無能為力的場景
下面這張圖表,能夠很好的說明上面列出的這兩個問題:

這張圖表的第一列是輸入的 image,最後的三列(先不用看這張圖表的第二列),是用三組不同閾值引數呼叫 canny 函式和額外的函式後得到的輸出 image,可以看到,邊緣檢測的效果,並不總是很理想的,有些場景中,矩形的邊,出現了很嚴重的斷裂,有些邊,甚至被完全擦除掉了,而另一些場景中,又會檢測出很多幹擾性質的長短邊。可想而知,想用一個數學模型,適應這麼不規則的邊緣圖,會是多麼困難的一件事情。
.
3、嘗試方案——YOLO&FCN
人臉對齊
首先想到的,就是仿照人臉對齊(face alignment)的思路,構建一個端到端(end-to-end)的網路,直接回歸擬合,也就是讓這個神經網路直接輸出 4 個頂點的座標,但是,經過嘗試後發現,根本擬合不出來。後來仔細琢磨了一下,覺得不能直接擬合也是對的,因為:
除了分類(classification)問題之外,所有的需求看上去都像是一個迴歸(regression)問題,如果迴歸是萬能的,學術界為啥還要去搞其他各種各樣的網路模型
face alignment 之所以可以用迴歸網路得到很好的擬合效果,是因為在輸入 image 上先做了 bounding box 檢測,縮小了人臉影象範圍後,才做的 regression
人臉上的關鍵特徵點,具有特別明顯的統計學特徵,所以 regression 可以發揮作用
在需要更高檢測精度的場景中,其實也是用到了更復雜的網路模型來解決 face alignment 問題的
YOLO && FCN
後來還嘗試過用 YOLO 網路做 Object Detection,用 FCN 網路做畫素級的 Semantic Segmentation,但是結果都很不理想,比如:
達不到文件檢測功能想要的精確度
網路結構複雜,運算量大,在手機上無法做到實時檢測
.
4、HED(Holistically-Nested Edge Detection) 網路
邊緣檢測這種需求,在影象處理領域裡面,通常叫做 Edge Detection 或 Contour Detection,按照這個思路,找到了 Holistically-Nested Edge Detection 網路模型。
HED 網路模型是在 VGG16 網路結構的基礎上設計出來的,所以有必要先看看 VGG16。
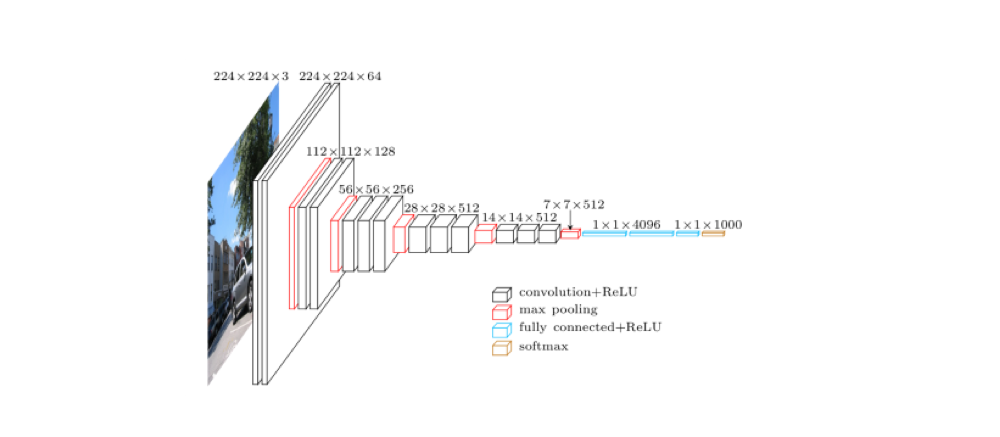
上圖是 VGG16 的原理圖,為了方便從 VGG16 過渡到 HED,我們先把 VGG16 變成下面這種示意圖:
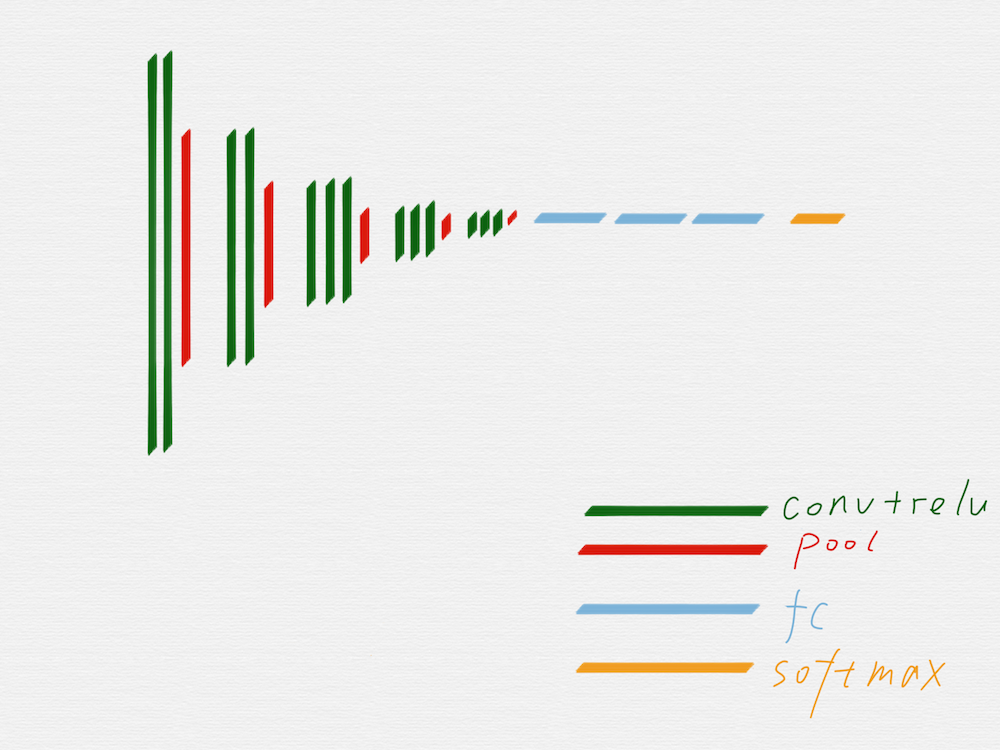
去掉不需要的部分後,就得到上圖這樣的網路結構,因為有池化層的作用,從第二組開始,每一組的輸入 image 的長寬值,都是前一組的輸入 image 的長寬值的一半。
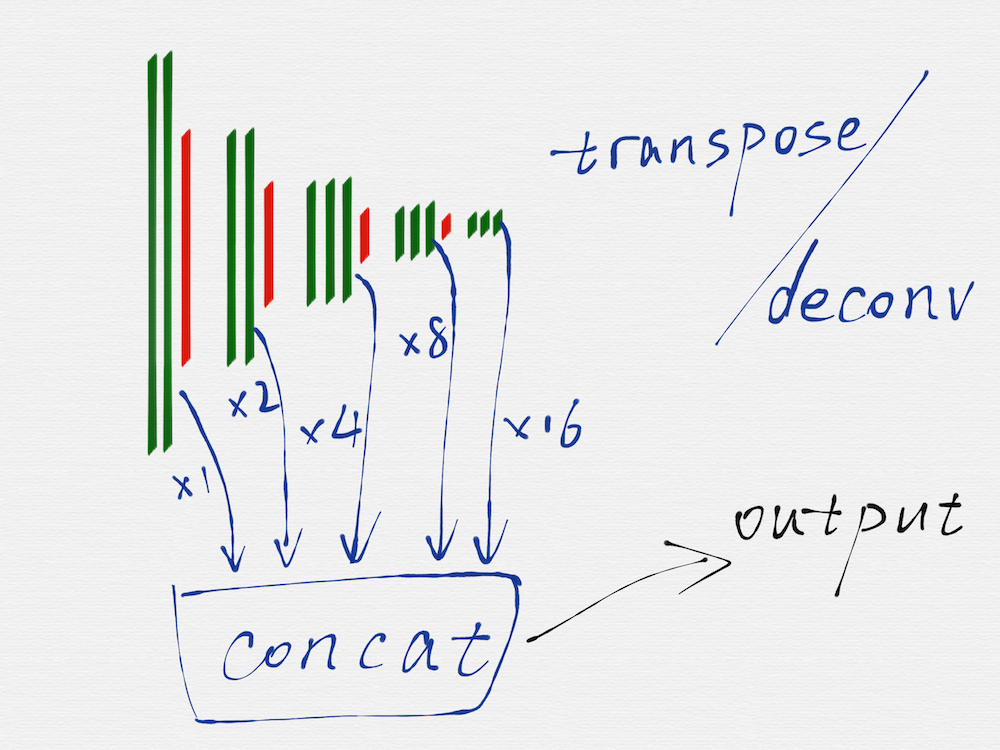
HED 網路是一種多尺度多融合(multi-scale and multi-level feature learning)的網路結構,所謂的多尺度,就是如上圖所示,把 VGG16 的每一組的最後一個卷積層(綠色部分)的輸出取出來,因為每一組得到的 image 的長寬尺寸是不一樣的,所以這裡還需要用轉置卷積(transposed convolution)/反捲積(deconv)對每一組得到的 image 再做一遍運算,從效果上看,相當於把第二至五組得到的 image 的長寬尺寸分別擴大 2 至 16 倍,這樣在每個尺度(VGG16 的每一組就是一個尺度)上得到的 image,都是相同的大小了。
其中還有:基於 TensorFlow 編寫的 HED 網路結構程式碼
.
5、OpenCV 演算法實現
雖然用神經網路技術,已經得到了一個比 canny 演算法更好的邊緣檢測效果,但是,神經網路也並不是萬能的,干擾是仍然存在的,所以,第二個步驟中的數學模型演算法,仍然是需要的,只不過因為第一個步驟中的邊緣檢測有了大幅度改善,所以第二個步驟中的演算法,得到了適當的簡化,而且演算法整體的適應性也更強了。
這部分的演算法如下圖所示:
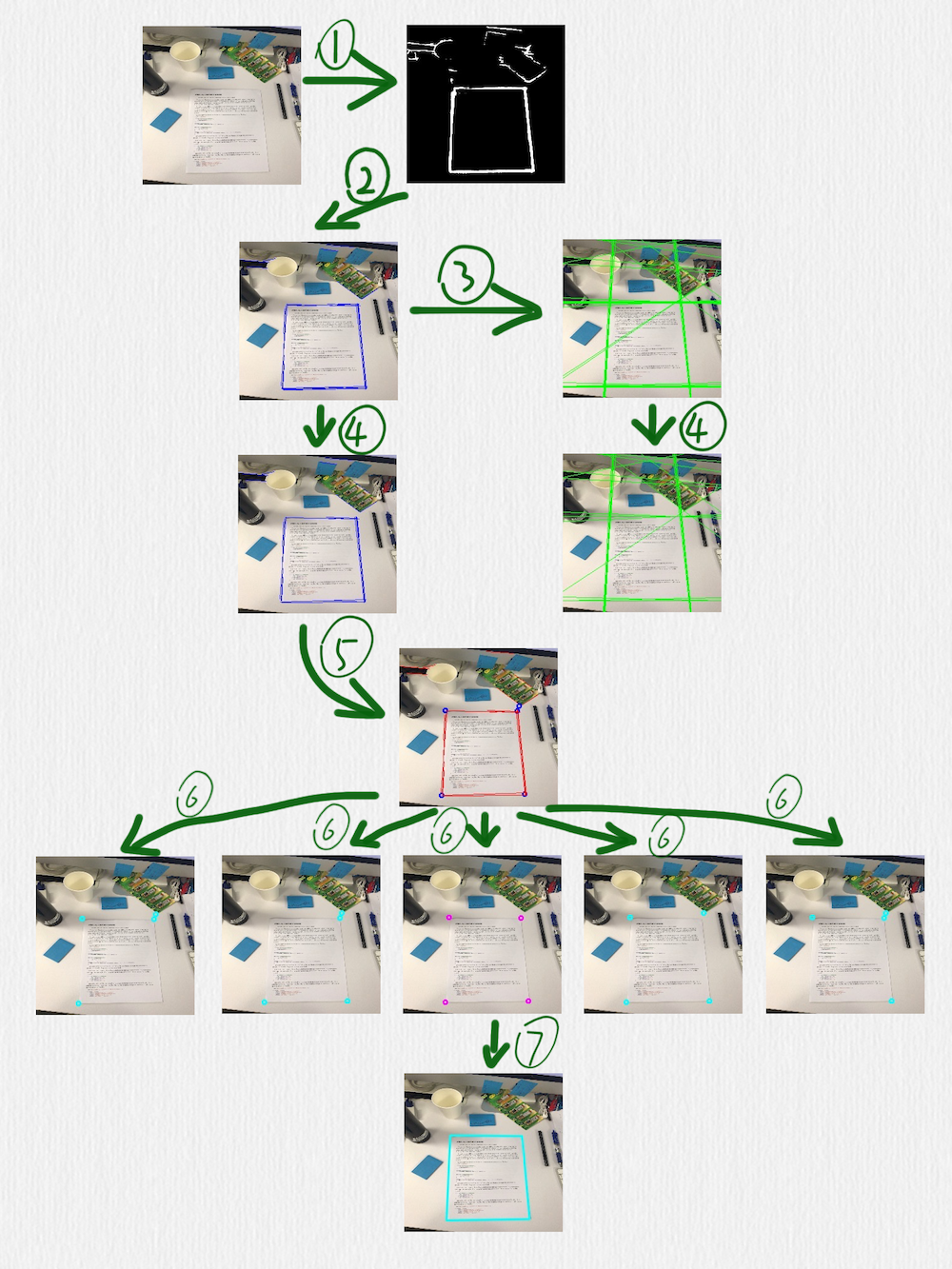
按照編號順序,幾個關鍵步驟做了下面這些事情:
用 HED 網路檢測邊緣,可以看到,這裡得到的邊緣線還是存在一些干擾的
在前一步得到的影象上,使用 HoughLinesP 函式檢測線段(藍色線段)
把前一步得到的線段延長成直線(綠色直線)
在第二步中檢測到的線段,有一些是很接近的,或者有些短線段是可以連線成一條更長的線段的,所以可以採用一些策略把它們合併到一起,這個時候,就要藉助第三步中得到的直線。定義一種策略判斷兩條直線是否相等,當遇到相等的兩條直線時,把這兩條直線各自對應的線段再合併或連線成一條線段。這一步完成後,後面的步驟就只需要藍色的線段而不需要綠色的直線了
根據第四步得到的線段,計算它們之間的交叉點,臨近的交叉點也可以合併,同時,把每一個交叉點和產生這個交叉點的線段也要關聯在一起(每一個藍色的點,都有一組紅色的線段和它關聯)
對於第五步得到的所有交叉點,每次取出其中的 4 個,判斷這 4 個點組成的四邊形是否是一個合理的矩形(有透視變換效果的矩形),除了常規的判斷策略,比如角度、邊長的比值之外,還有一個判斷條件就是每條邊是否可以和第五步中得到的對應的點的關聯線段重合,如果不能重合,則這個四邊形就不太可能是我們期望檢測出來的矩形
經過第六步的過濾後,如果得到了多個四邊形,可以再使用一個簡單的過濾策略,比如排序找出周長或面積最大的矩形
.
二、訓練集獲取(大量合成數據 + 少量真實資料)
HED 論文裡使用的訓練資料集,是針對通用的邊緣檢測目的的,什麼形狀的邊緣都有,比如下面這種:

用這份資料訓練出來的模型,在做文件掃描的時候,檢測出來的邊緣效果並不理想,而且這份訓練資料集的樣本數量也很小,只有一百多張圖片(因為這種圖片的人工標註成本太高了),這也會影響模型的質量。
現在的需求裡,要檢測的是具有一定透視和旋轉變換效果的矩形區域,所以可以大膽的猜測,如果準備一批針對性更強的訓練樣本,應該是可以得到更好的邊緣檢測效果的。
藉助第一版技術方案收集回來的真實場景圖片,我們開發了一套簡單的標註工具,人工標註了 1200 張圖片(標註這 1200 張圖片的時間成本也很高),但是這 1200 多張圖片仍然有很多問題,比如對於神經網路來說,1200 個訓練樣本其實還是不夠的,另外,這些圖片覆蓋的場景其實也比較少,有些圖片的相似度比較高,這樣的資料放到神經網路裡訓練,泛化的效果並不好。
所以,還採用技術手段,合成了80000多張訓練樣本圖片。

如上圖所示,一張背景圖和一張前景圖,可以合成出一對訓練樣本資料。在合成圖片的過程中,用到了下面這些技術和技巧:
在前景圖上新增旋轉、平移、透視變換
對背景圖進行了隨機的裁剪
通過試驗對比,生成合適寬度的邊緣線
OpenCV 不支援透明圖層之間的旋轉和透視變換操作,只能使用最低精度的插值演算法,為了改善這一點,後續改成了使用 iOS 模擬器,通過 CALayer 上的操作來合成圖片
在不斷改進訓練樣本的過程中,還根據真實樣本圖片的統計情況和各種途徑的反饋資訊,刻意模擬了一些更復雜的樣本場景,比如凌亂的背景環境、直線邊緣干擾等等
經過不斷的調整和優化,最終才訓練出一個滿意的模型,可以再次通過下面這張圖表中的第二列看一下神經網路模型的邊緣檢測效果: