
Ubuntu下搭建spark叢集開發環境
之前在windows下搭建了一個spark的開發環境,但是後來發現如果想要搞spark streaming的例子的話在Linux下使用更方便,於是在Ubuntu下面搭建一下spark開發環境,記錄以做備忘之用。
2 .
.

3 .之後利用XSheel5將下載的壓縮包傳遞到linux的主節點的目錄下,這裡我的主節點的ip為192.168.71.128

4 .之後切換到目錄下,用tar -zxvf命令進行解壓縮,解壓縮後得到去掉字尾的資料夾

5 .之後進入 sudo vi /etc/profile,修改配置檔案,新增spark的相關內容,見下圖,之後退出用source/etc/profile進行儲存

6 .接下來修改之前解壓縮目錄下的conf下的spark-env.sh檔案,通過cp命令複製一下模板
cp spark-env.sh.template spark-env.sh

7 .之後通過sudo vispark-env.sh進入,在末尾新增這些東西見下圖,最後一個是主節點的ip地址,根據實際情況改成自己的:加入如下:
exportJAVA_HOME=/usr/local/java/jdk1.8.0_11
exportSCALA_HOME=/usr/local/hadoop/spark/scala-2.10.6
SPARK_MASTER_IP=192.168.71.128 #根據自己的master
8 .在這之前先在任何一個位置輸入spark-shell,測試一下環境變數是否配置成功,如果出現下面這個圖表明成功

9 .接下來修改spark下的conf下面的slaves檔案,新增子節點的ip地址,如果這裡沒有這個檔案,可以通過cp命令進行復制slaves模板得到,我這裡有三個子節點,根據自己的實際情況進行修改即可 sudo vi slaves

10 .將上面這個儲存,到此主節點的spark的相關配置已經完成,接下來只需要將該配置分發到其他子節點即可,之前已經配置了免密登入,如果這裡有問題,可以參考我之前寫的免密登入的相關內容,我這裡有三個子節點,全部拷貝到相同目錄下即可
11 .之後先啟動hadoop,分別呼叫start-dfs.sh和start-yarn.sh,之後進入spark的sbin目錄啟動start-master.sh和start-slaves.sh,
如果出現如下問題:

啟動命令改為:./start-master.sh和./start-slaves.sh即可
如果執行hadoop的start-dfs.sh不動了,則需要輸入密碼,因為我的master端沒有配置好自己免密碼登入ssh,所以需要輸入master的密碼,尷尬。。。。
啟動完畢後在主節點和子節點分別呼叫jps檢視程序如下圖
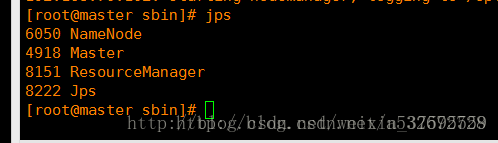
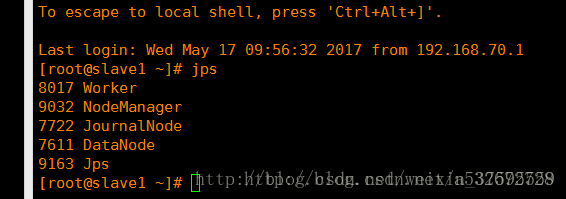
12 .之後登入8080檢視spark的管理介面,出現下圖說明叢集搭建成功暫時告一段落,這裡根據自己的主節點的ip地址進行修改即可。
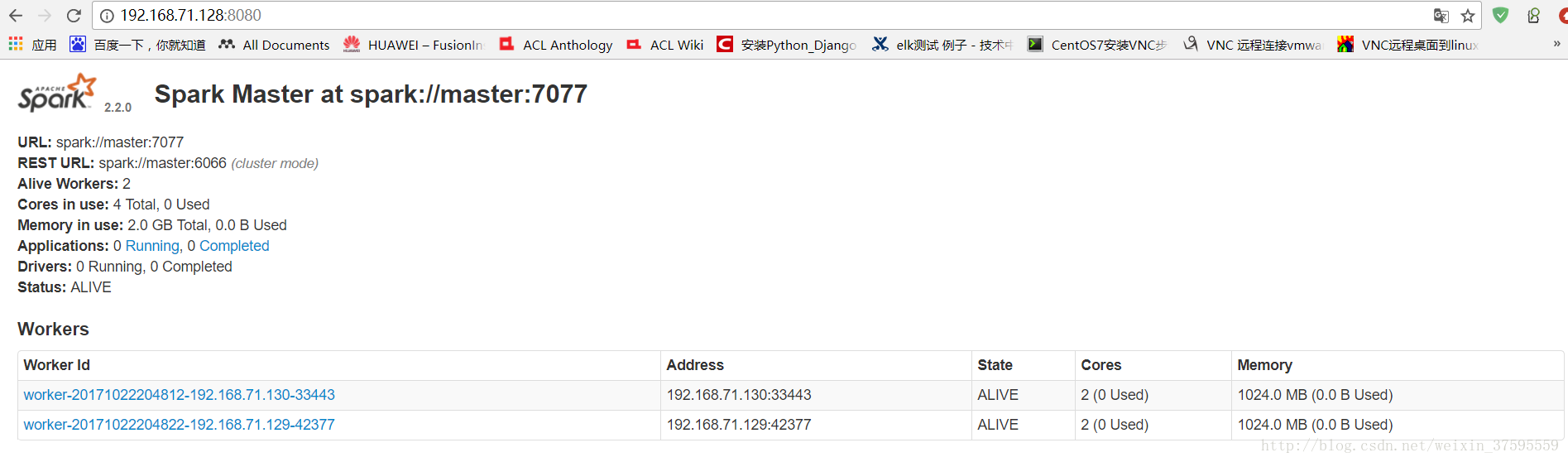
13 .接下里就可以進行實操了,