
機器學習中訓練資料集,交叉驗證資料集,測試資料集的作用
阿新 • • 發佈:2019-01-06
#1. 簡介
在Andrew Ng的機器學習教程裡,會將給定的資料集分為三部分:訓練資料集(training set)、交叉驗證資料集(cross validation set)、測試資料集(test set)。三者分別佔總資料集的60%、20%、20%。
那麼這些資料集分別是什麼作用呢?
#2. 三種資料集的作用
假設我們訓練一個數據集,有下面10中模型可以選擇:
(圖片來自Coursera Machine Learning Andrew Ng 第6周:Model Selection and Train/Validation/Test Sets)
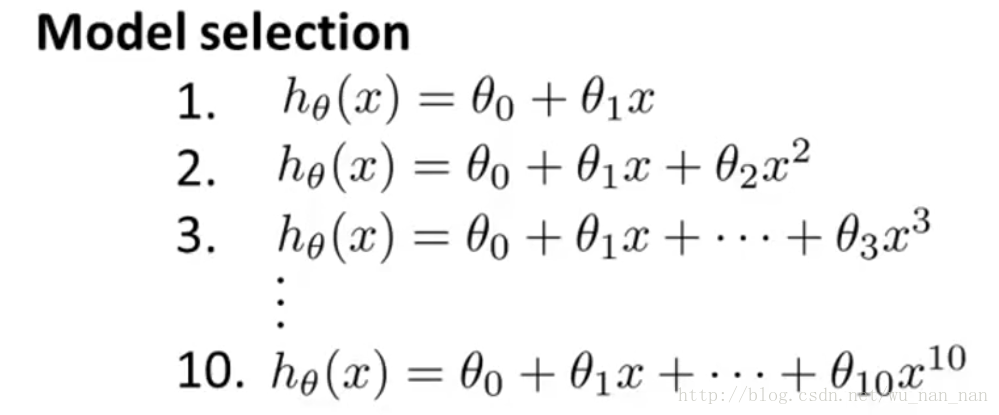
我們想知道兩件事:
- 1)這10中模型中哪種最好(決定多項式的階數d);
- 2)最好的模型的引數是什麼。
為此,我們需要,
- 使用訓練資料集分別訓練這10個模型;
- 用訓練好的這10個模型,分別處理交叉驗證資料集,統計它們的誤差,取誤差最小的模型為最終模型(這步就叫做Model Selection)。
- 用測試資料集測試其準確性。
這裡有個問題要回答:為什麼不直接使用測試資料集(Test Set)來執行上面的第2.步?
答:如果資料集只分成訓練資料集(Training Set)和測試資料集(Test Set),且訓練資料集用於訓練,測試資料集用於選擇模型,那麼就缺少能夠“公平”評判最終模型優劣的資料集,因為最終的模型就是根據訓練資料集和測試資料集訓練得到的,肯定在這兩個資料集上表現良好,但不一定在其他資料上也如此。