
Objective-C擷取字串時emoji表情的處理
阿新 • • 發佈:2019-01-06
我們在開發中會經常遇到限制字串長度的情況,如輸入框限制輸入字數,我們會經常使用substringToIndex進行字串擷取,這樣做有一個潛在的問題,那就是當擷取的index恰好是一個emoji表情的時候,因為一個emoij在字串的length並不等於1,這樣就會把emoji表情分割開來,從而造成整個字串不顯示或者最後一個字元是亂碼的情況。
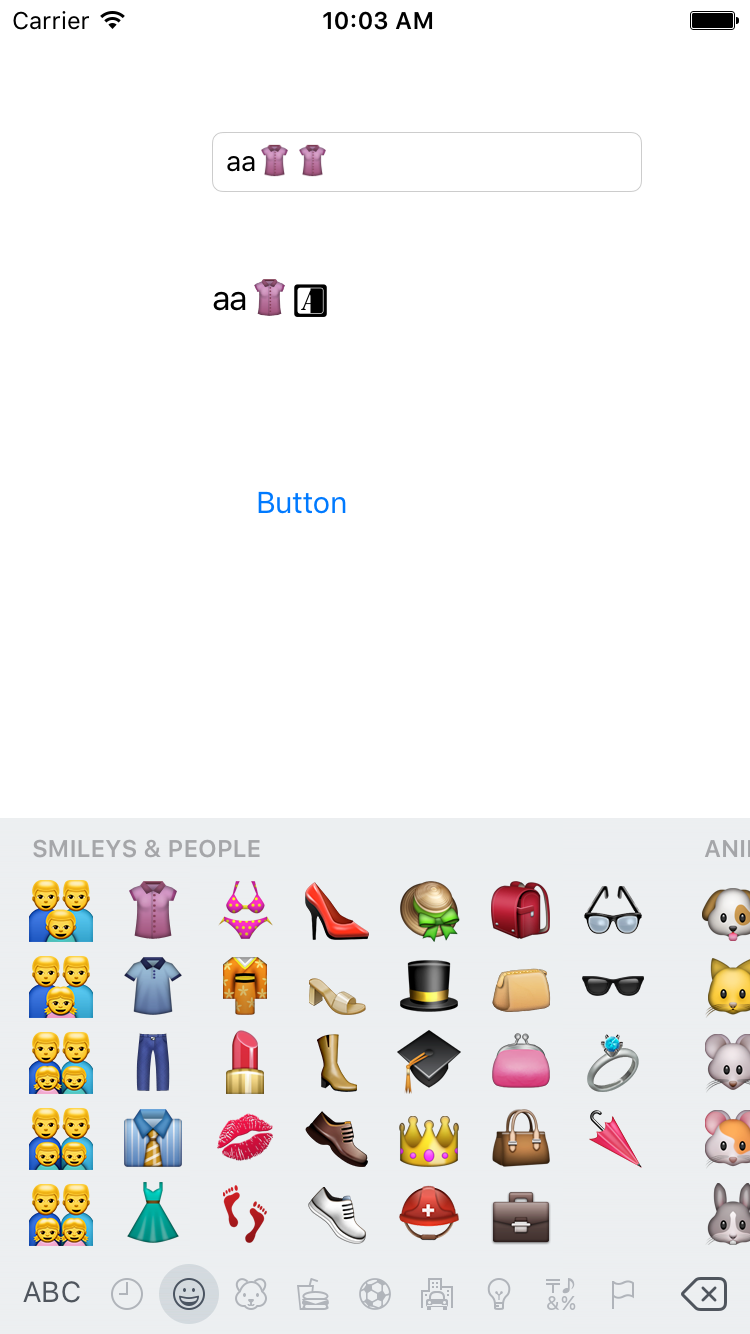
起初我發現擷取一半的emoji的時候吧字串進行UTF8String轉碼後為NULL,所以根據此我寫了這樣一個方法:
-(NSString *)subStringWith:(NSString *)string ToIndex:(NSInteger)index{
NSString *result 即少擷取一個字元以避免擷取到emoji的情形。
但是放到以前還行,現在的話就會有問題,這種方法是建立在emoji表情都佔兩個length的長度基礎上的,而現在新出的國旗emoji佔了四個長度,當擷取到emoji的前三個的時候進行轉碼並不等於NULL。後翻看NSString的文件,發現了這兩個方法官方文件沒有給出說明,索性試一試:
- (NSRange)rangeOfComposedCharacterSequenceAtIndex:(NSUInteger)index;
- (NSRange)rangeOfComposedCharacterSequencesForRange:(NSRange)range NS_AVAILABLE(10_5, 2_0);我發現當把擷取的index傳給rangeOfComposedCharacterSequenceAtIndex方法時返回的是index所在的emoji表情的range,所以Objective-C已經考慮到了emoji表情擷取的問題,但是沒有給出註釋。。。
故而修改方法如下:
-(NSString *)subStringWith:(NSString *)string ToIndex:(NSInteger)index{
NSString *result = string;
if (result.length > index) {
NSRange rangeIndex = [result rangeOfComposedCharacterSequenceAtIndex:index];
result = [result substringToIndex:(rangeIndex.location)];
}
return result;
}