
Python爬蟲常見問題總結
Python爬蟲常見問題總結
問題一
背景:連結:https://blog.csdn.net/xxzj_zz2017/article/details/79739077
怎麼都無法測試成功
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 8 08:46:45 2018
@author: zwz
"""
#參考網站:https://blog.csdn.net/xxzj_zz2017/article/details/79739077、
from splinter.browser import Browser
from bs4 import BeautifulSoup
import 執行出現的問題:
70)
解決了一小時,還是沒解決,現放下問題,等待有緣人解決。
問題二
連結背景:https://mp.weixin.qq.com/s/E4EEgmQverifK5mc6W8onw
程式碼在這:百度雲連結:https://pan.baidu.com/s/17zlP3AMNCQdvEQpU7Rx_tw 提取碼:9z9q
問題程式:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 10 19:36:24 2018
@author: hzp0625
"""
from selenium import webdriver
import pandas as pd
from datetime import datetime
import numpy as np
import time
import os
os.chdir('D:\data_work')
def gethtml(url):
browser = webdriver.PhantomJS(executable_path="F:\Study_software\Anaconda\setup\Lib\site-packages\selenium\webdriver\phantomjs")
browser.get(url)
browser.implicitly_wait(10)
return(browser)
def getComment(url):
browser = gethtml(url)
i = 1
AllArticle = pd.DataFrame(columns = ['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like'])
print('連線成功,開始爬取資料')
while True:
xpath1 = '//*[@id="app"]/div[2]/div[2]/div/div[1]/div/div/div[4]/div/div/ul/li[{}]'.format(i)
try:
target = browser.find_element_by_xpath(xpath1)
except:
print('全部爬完')
break
author = target.find_element_by_xpath('div[1]/div[2]').text
comment = target.find_element_by_xpath('div[2]/div').text
stars1 = target.find_element_by_xpath('div[1]/div[3]/span/i[1]').get_attribute('class')
stars2 = target.find_element_by_xpath('div[1]/div[3]/span/i[2]').get_attribute('class')
stars3 = target.find_element_by_xpath('div[1]/div[3]/span/i[3]').get_attribute('class')
stars4 = target.find_element_by_xpath('div[1]/div[3]/span/i[4]').get_attribute('class')
stars5 = target.find_element_by_xpath('div[1]/div[3]/span/i[5]').get_attribute('class')
date = target.find_element_by_xpath('div[1]/div[4]').text
like = target.find_element_by_xpath('div[3]/div[1]').text
unlike = target.find_element_by_xpath('div[3]/div[2]').text
comments = pd.DataFrame([i,author,comment,stars1,stars2,stars3,stars4,stars5,like,unlike]).T
comments.columns = ['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like']
AllArticle = pd.concat([AllArticle,comments],axis = 0)
browser.execute_script("arguments[0].scrollIntoView();", target)
i = i + 1
if i%100 == 0:
print('已爬取{}條'.format(i))
AllArticle = AllArticle.reset_index(drop = True)
return AllArticle
url = 'https://www.bilibili.com/bangumi/media/md102392/?from=search&seid=8935536260089373525#short'
result = getComment(url)
#result.to_csv('工作細胞爬蟲.csv',index = False)
問題截圖:
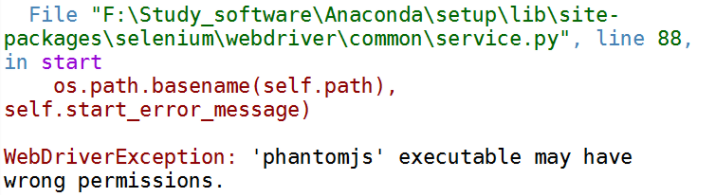
解決辦法:
1.首先,先自己安裝:pip install phantomjs (我是在anconda的基礎上進行的,windows 64)
2.發現,無法全部安裝成功,特別是這個phantomjs.exe
最後,通過查詢網上,該網址:https://stackoverflow.com/questions/37903536/phantomjs-with-selenium-error-message-phantomjs-executable-needs-to-be-in-pa
有較好的解決辦法,我是通過其中的它給出的網址,進行下載相應的phantomjs.exe。
我最後把上面的那句,更改為:
browser = webdriver.PhantomJS(executable_path="F:\Study_software\Anaconda\setup\Lib\site-packages\selenium\webdriver\phantomjs\phantomjs.exe")
就是把最後的指向是指向一個.exe檔案,結果就可以了。
問題三:
我發現原來詞雲的生成效果是與圖片的高清程度是有關的。
如果有需要,可以去看一下,我的文章:https://blog.csdn.net/weixin_38809485/article/details/83892939
分享一個下載高清圖片的網站:https://unsplash.com/
區別:

