
高度不平衡物體尺寸的指數對數損失三維分割
3D Segmentation with Exponential Logarithmic Loss for Highly Unbalanced Object Sizes
隨著完全卷積神經網路的引入,深度學習提高了醫學影象分割的速度和準確度的基準,並且已經提出了用於2D和3D分割的不同網路,並且具有有希望的結果。然而,大多數網路僅處理相對較少數量的標籤(<10),並且在處理高度不平衡的物件尺寸方面的工作非常有限,尤其是在3D分割中。在本文中,我們提出了一種網路架構和相應的損失函式,它們可以改善非常小的結構的分割。通過結合跳過連線和深度監督三維分割的計算可行性,我們提出了一種快速收斂和計算有效的網路架構,以實現精確分割。此外,受焦點損失概念的啟發,我們提出了一種指數對數損失,它不僅通過它們的相對大小而且通過它們的分割困難來平衡標記。我們使用20個標籤對大腦分割實現平均Dice係數為82%,最小物件大小與最大物件大小的比率為0.14%。要達到這樣的精確度,需要不到100個時期,而分割128×128×128的音量只需要大約0.4秒。
隨著完全卷積神經網路(CNN)的引入,深度學習提高了醫學影象分割速度和準確度的基準[7]。提出了不同的2D [5,8]和3D [1,2,6,10]網路,以從醫學影象中分割出各種解剖結構,例如心臟,腦,肝臟和前列腺。無論這些網路的有希望的結果如何,3D CNN影象分割仍然具有挑戰性。大多數網路應用於具有少量標籤(<10)的資料集,尤其是在3D分割中。當需要更詳細的分割以及更多的解剖結構時,需要通過新的網路架構和演算法來解決先前未見過的問題,例如計算可行性和高度不平衡的物件大小。
對於高度不平衡的標籤,只提出了一些框架。在[8]中,提出了2D網路架構來分割3D腦容積的所有切片。引入了錯誤校正增強來計算標籤權重,強調對具有較低驗證準確性的類的引數更新。儘管結果很有希望,但標籤權重僅應用於加權交叉熵但不應用於骰子損失,並且用於3D分割的2D結果的堆疊可能導致連續切片之間的不一致。
在[9]中,廣義骰子損失被用作損失函式。 不是計算每個標籤的Dice損失,而是針對廣義Dice損失計算產品在地面實況和預測概率之和之間的加權和上的加權和,其中權重與標籤頻率成反比。 實際上,Dice係數對於小結構是不利的,因為誤分類的一些畫素可能導致係數的大幅減小,並且這種靈敏度與結構之間的相對尺寸無關。 因此,通過標籤頻率進行平衡對於Dice損失是非最優的。
為了解決三維分割中高度不平衡的物體尺寸和計算效率的問題,我們在本文中有兩個關鍵的貢獻。 (I)我們提出指數對數損失函式。在[4]中,為了處理兩類影象分類問題的高度不平衡的資料集,僅通過網路輸出的softmax概率計算的調製因子乘以加權的交叉熵以關注不太準確的類。受這種平衡分類困難的概念的啟發,我們提出了一種包含對數Dice損失的損失函式,其本質上更側重於不太精確的分段結構。對數Dice損失和加權交叉熵的非線性可以通過所提出的指數引數進一步控制。以這種方式,網路可以在小型和大型結構上實現精確分割。 (II)我們提出了一種快速收斂和計算效率高的網路架構,它結合了跳過連線和深度監控的優點,它只有V-Net的1/14,並且速度是V-Net的兩倍[6]。 。在具有20個高度不平衡標籤的腦磁共振(MR)影象上進行實驗。結合這兩項創新,平均分割係數達到82%,平均分割時間為0.4秒。
2 Methodology
2.1 Proposed Network Architecture
3D分割網路比2D網路需要更多的計算資源。因此,我們提出了一種網路架構,旨在針對有限的資源進行精確分割和快速收斂(圖1)。與大多數分段網路類似,我們的網路包括編碼和解碼路徑。該網路由卷積塊組成,每個卷積塊包括與批量歸一化(BN)和整流線性單元(ReLU)相關聯的n個通道的k級聯3×3×3卷積層。為了更好地收斂,在每個塊中使用具有1×1×1卷積層的跳過連線。我們將兩個分支新增在一起以減少記憶體消耗,而不是連線,因此該塊允許有效的多規模處理,並且可以訓練更深的網路。每次最大池化後,通道數(n)加倍,每次上取樣後減半。更多層(k)與較小尺寸的張量一起使用,以便在可行的儲存器使用的情況下可以學習更抽象的知識。來自編碼路徑的特徵通道與解碼路徑中的相應張量連線,以便更好地收斂。我們還包括高斯噪聲層和丟失層,以避免過度擬合。
與[5]類似,我們利用深度監督,允許更直接的反向傳播到隱藏層,以實現更快的收斂和更高的準確性[3]。 雖然深度監督可以顯著提高收斂性,但在3D網路中尤其是記憶體昂貴。 因此,我們省略了具有最多通道的塊的張量(塊(192,3)),以便可以在具有12GB記憶體的GPU上執行訓練。 具有softmax函式的1×1×1卷積的最後一層提供分割概率。

2.2指數對數損失
我們提出了一種損失函式,可以改善小結構的分割:
![]()
用w Dice和w交叉指數對數Dice損失(LDice)和加權指數交叉熵(LCross)的各自權重:
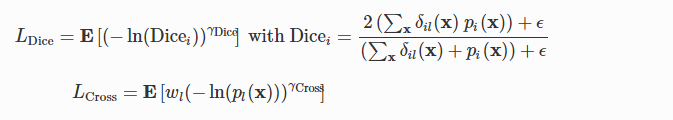
用x表示畫素位置和標籤。 l是x的地面實況標籤。 E [∙]分別是LDice和LCross中關於i和x的平均值。 δil(x)是Kronecker delta,當i = 1時為1,否則為0。 pi(x)是softmax概率,其在計算Dicei時充當標籤i所擁有的畫素x的部分。 ε= 1是用於處理訓練樣本中缺失標籤的加法平滑的偽計數。 wl =((Σkfk)/ fl)0.5,標籤k的頻率為fk,是用於減少更常見標籤影響的標籤重量。 γDice和γCross進一步控制損失函式的非線性,為簡單起見,我們在這裡使用γDice=γCross=γ。
在[6]中提出了在CNN中使用骰子損失。 Dice係數不利於小結構,因為對幾個畫素進行錯誤分類會導致係數大幅下降。標籤權重的使用不能減輕這種敏感性,因為它與相對物件大小無關,並且Dice係數已經是標準化度量。因此,我們使用對數骰子損失而不是尺寸差異,而骰子損失更多地集中在不太準確的標籤上。圖2顯示了線性(E [1-Dicei])和對數Dice損失之間的比較。
我們通過引入指數γDice和γCross來進一步控制損耗的非線性。在[4]中,調製因子(1-pl)γ乘以加權交叉熵,變為wl(1-pl)γ(-ln(pl)),用於兩類影象分類。除了使用標籤權重wl平衡標籤頻率之外,該焦點損失還在易於和硬的樣本之間平衡。我們的指數損失實現了類似的目標。當γ> 1時,損失更多地集中在比對數損失更不準確的標籤上(圖2)。雖然焦點損失適用於[4]中的兩類影象分類,但是當應用於具有20個標籤的分割問題時,我們得到了更差的結果。這可能是由於標籤精度變高時過度抑制損耗功能引起的。相反,我們可以在0 <γ<1時獲得更好的結果。圖2顯示當γ= 0.3時,在x = 0.5附近存在拐點,其中x可以是Dicei或pl(x)。對於x <0.5,該損失表現類似於γ≥1時的損耗,隨著x增加,梯度幅度減小。隨著梯度幅度的增加,這種趨勢在x> 0.5時反轉。因此,這種損失促進了低預測精度和高預測精度的改進。這個特徵是使用所提出的指數形式而不是[4]中的指數形式的原因。

2.3培訓策略
影象增強用於學習不變特徵並避免過度擬合。 由於實際的非剛性變形難以實現且計算成本昂貴,因此我們將增強限制為剛性變換,包括旋轉(軸向,±30∘),偏移(±20%)和縮放([0.8,1.2])。 每個影象有80%的機會在訓練中被轉換,因此增強影象的數量與時期的數量成比例。 優化器Adam與Nesterov動量一起用於快速收斂,學習率為10 -3,批量大小為1,並且100個時期。 使用具有12 GB記憶體的TITAN X GPU。
3實驗
3.1資料和實驗設定
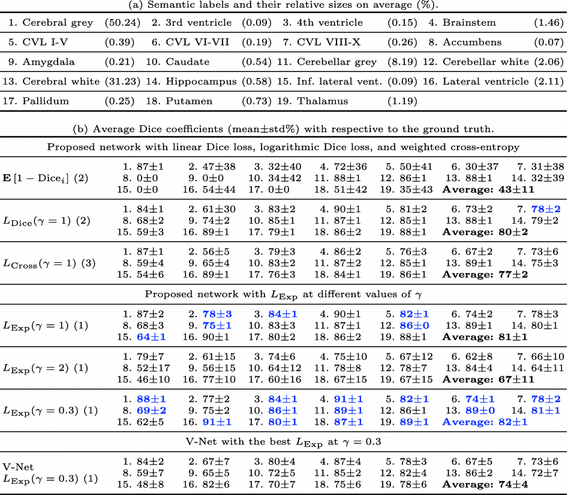
來自不同患者的43個3D腦MR影象的資料集被神經解剖學標記以提供訓練和驗證樣品。影象由T1加權的MP-RAGE脈衝序列產生,其提供高組織對比度。它們由訓練有素的專家手動分割,結果由諮詢神經解剖學家審查。每個分割具有19個腦結構的語義標籤,因此包括20個具有背景的標籤(表1(a))。由於存在各種影象尺寸(128至337)和間距(0.9至1.5mm),每個影象使用最小間距重新取樣為各向同性間距,在短邊上填充零,並調整為128×128×128。
表1(a)顯示標籤高度不平衡。背景平均佔據了影象的93.5%。在沒有背景的情況下,最小和最大結構的相對尺寸分別為0.07%和50.24%,因此比率為0.14%。
我們使用所提出的網路研究了六種損失函式,並將最好的一種應用於V-Net架構[6],因此總共研究了七種情況。對於LExp,我們設定wDice = 0.8和wCross = 0.2,因為它們提供了最好的結果。通過改組和拆分資料集生成五組資料,其中70%用於培訓,30%用於每組驗證。對於每個研究的案例,對所有五組資料進行了實驗,以獲得更具統計學意義的結果。針對每個驗證影象計算實際Dice係數,而不是(2)中的Dicei。在所有實驗中使用相同的設定和訓練策略。
表格1。
語義腦分割。 (a)語義標籤及其相對大小(%),沒有背景。 CVL代表小腦的小葉。 背景平均佔據了影象的93.5%。 (b)從五次實驗中平均預測和地面實況之間的骰子係數(格式:平均值±標準%)。 最佳結果以藍色突出顯示。 對於所有LExp,wDice = 0.8並且wCross = 0.2。
3.2結果與討論
表1(b)顯示了五次實驗的平均Dice係數。線性骰子損失(E [1-Dicei])具有最差的效能。它在灰色和白色等相對較大的結構上表現良好,但效能隨著結構尺寸的減小而降低。在所有實驗中都遺漏了非常小的結構,例如伏隔核和扁桃體。相反,對數Dice損失(LDice(γ= 1))提供了更好的結果,儘管標籤2的大標準偏差表明存在未命中。我們還進行了加權交叉熵(LCross(γ= 1))的實驗,其效能優於線性Dice損失但差於對數Dice損失。對數Dice損失和加權交叉熵(LExp(γ= 1))的加權和優於單個損失,並且在測試案例中提供了第二好的結果。正如在Sect。中所討論的。 2.2,LExp(γ= 2)即使在較大的結構上也是無效的。這與我們在圖2中的觀察結果一致,即當精度越來越高時,損失函式被過度抑制。相反,LExp(γ= 0.3)給出了最好的結果。雖然在平均值方面僅略好於LExp(γ= 1),但較小的標準偏差表明它也更精確。

圖4。
視覺化的一個例子。 上圖:軸向檢視。 底部:隱藏的腦灰色,腦白色和小腦灰色的3D檢視,以便更好地說明。
當將最佳損失函式應用於V-Net時,其效能僅優於線性Dice損失和LExp(γ= 2)。這表明我們提出的網路架構在這個問題上比V-Net表現得更好。
圖3顯示了驗證Dice係數與時間的關係,平均來自五個實驗。我們顯示Dice係數,而不是損失,因為它們的大小在各個案例中是一致的。與表1(b)類似,對數Dice損失,LExp(γ= 1)和LExp(γ= 0.3)具有良好的收斂性和效能,LExp(γ= 0.3)表現稍好。這三個案例聚集在大約80個時代。加權交叉熵和LExp(γ= 2)更加波動。線性骰子損失也在約80個時期收斂,但Dice係數小得多。使用LExp(γ= 0.3)比較V-Net和建議的網路,V-Net的收斂性更差,特別是在早期時期。這表明所提出的網路具有更好的收斂性。
圖4顯示了一個示例的視覺化。有兩個明顯的觀察結果。首先,與表1(b)一致,線性骰子損失錯過了一些小結構,例如伏隔核和扁桃體,儘管它在大型結構上表現良好。其次,V-Net的分割偏離了實際情況。對數Dice損失,LExp(γ= 1)和LExp(γ= 0.3)具有最佳分割和平均Dice係數。加權交叉熵具有與LExp(γ= 2)相同的平均Dice係數,儘管加權交叉熵過分割一些結構如腦幹和LExp(γ= 2)具有噪聲分割。
比較擬議網路和V-Net之間的效率,建議的網路有大約500萬個引數,而V-Net有大約7100萬個引數,相差14倍。此外,建議的網路平均僅花費約0.4秒來分割128×128×128的體積,而V-Net花費約0.9秒。因此,建議的網路更有效。
4。結論
在本文中,我們提出了一種針對三維影象分割優化的網路架構,以及一種用於分割非常小的結構的損失函式。 所提出的網路架構僅具有大約1/14的引數,並且是V-Net的兩倍。 對於損失函式,對數Dice損失優於線性Dice損失,並且對數Dice損失和加權交叉熵的加權和優於單個損失。 通過引入指數形式,可以進一步控制損失函式的非線性,以提高分割的準確性和精度。