
不平衡資料分類演算法介紹與比較
介紹
在資料探勘中,經常會存在不平衡資料的分類問題,比如在異常監控預測中,由於異常就大多數情況下都不會出現,因此想要達到良好的識別效果普通的分類演算法還遠遠不夠,這裡介紹幾種處理不平衡資料的常用方法及對比。
符號表示
- 記多數類的樣本集合為L,少數類的樣本集合為S。
- 用r=|S|/|L|表示少數類與多數類的比例
基準
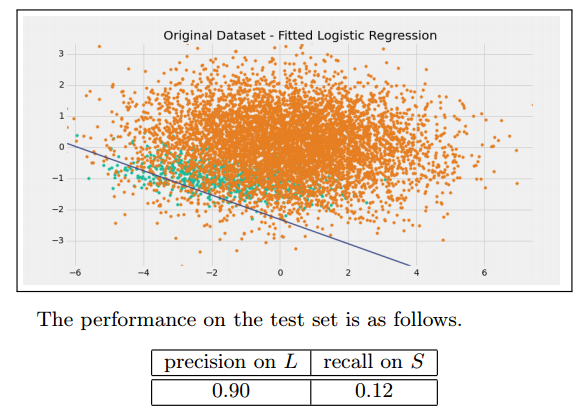
我們先用一個邏輯斯諦迴歸作為該實驗的基準:
Weighted loss function
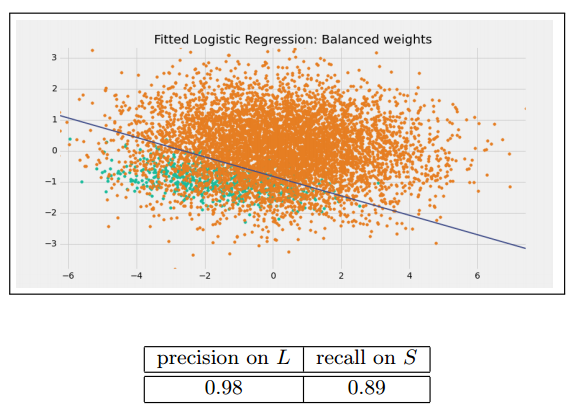
一個處理非平衡資料常用的方法就是設定損失函式的權重,使得少數類判別錯誤的損失大於多數類判別錯誤的損失。在python的scikit-learn中我們可以使用class_weight
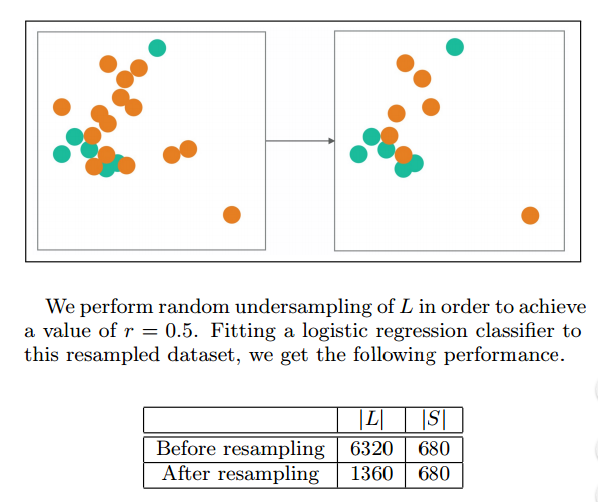
欠取樣方法(undersampling)
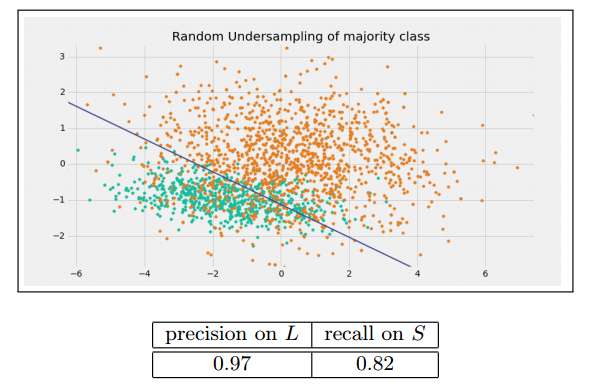
Random undersampling of majority class
一個最簡單的方法就是從多數類中隨機抽取樣本從而減少多數類樣本的數量,使資料達到平衡。
Edited Nearest Neighbor (ENN)
我們將那些L類的樣本,如果他的大部分k近鄰樣本都跟他自己本身的類別不一樣,我們就將他刪除。
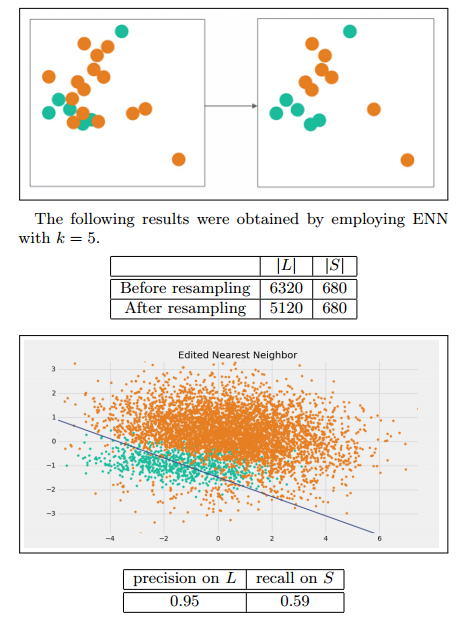
Repeated Edited Nearest Neighbor
這個方法就是不斷的重複上述的刪除過程,直到無法再刪除為止。
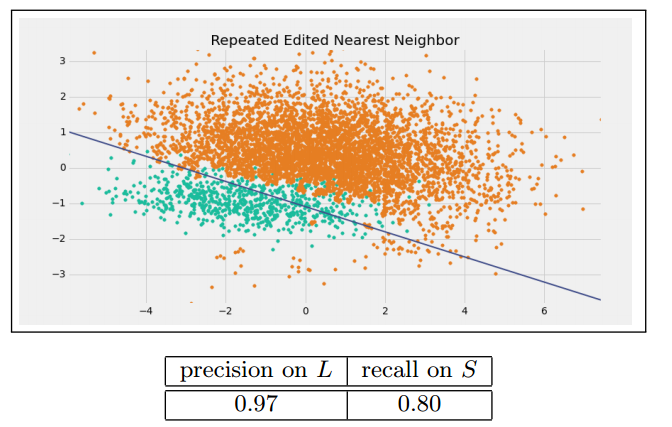
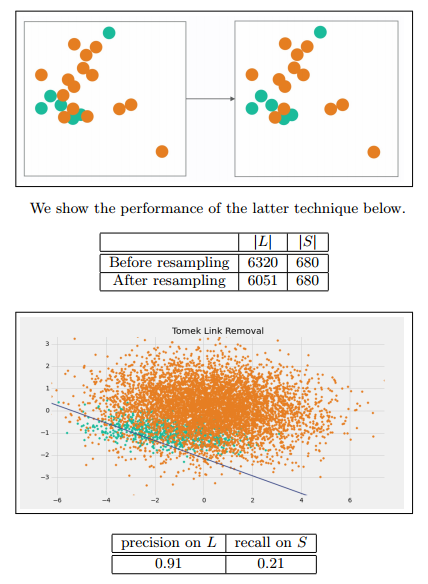
Tomek Link Removal
如果有兩個不同類別的樣本,它們的最近鄰都是對方,也就是A的最近鄰是B,B的最近鄰是A,那麼A,B就是Tomek link。我們要做的就是講所有Tomek link都刪除掉。那麼一個刪除Tomek link的方法就是,將組成Tomek link的兩個樣本,如果有一個屬於多數類樣本,就將該多數類樣本刪除掉。
過取樣方法(Oversampling)
我們可以通過欠抽樣來減少多數類樣本的數量從而達到平衡的目的,同樣我們也可以通過,過抽樣來增加少數類樣本的數量,從而達到平衡的目的。
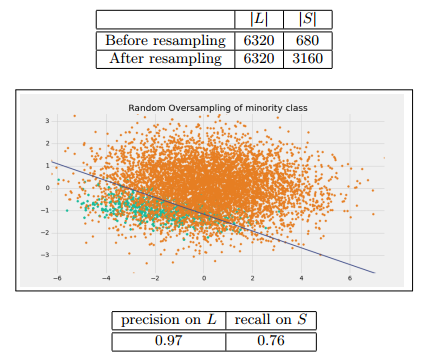
Random oversampling of minority class
一個最簡單的方法,就是通過有放回的抽樣,不斷的從少數類的抽取樣本,不過要注意的是這個方法很容易會導致過擬合。我們通過調整抽樣的數量可以控制使得r=0.5
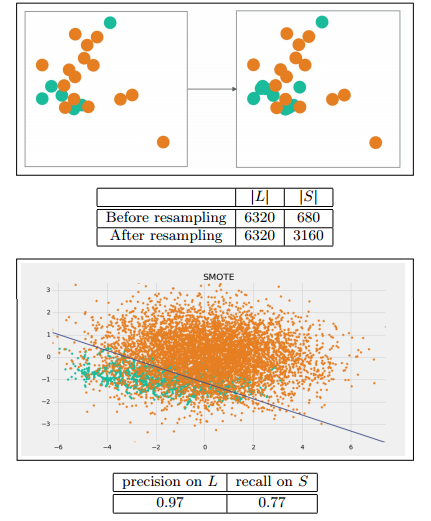
Synthetic Minority Oversampling Technique(SMOTE)
這是一個更為複雜的過抽樣方法,他的方法步驟如下:
For each For each point p in S:
1. 計算點p在S中的k個最近鄰
2. 有放回地隨機抽取R≤k個鄰居
3. 對這R個點,每一個點與點p可以組成一條直線,然後在這條直線上隨機取一個點,就產生了一個新的樣本,一共可以這樣做從而產生R個新的點。
4. 將這些新的點加入S中
Borderline-SMOTE1
這裡介紹兩種方法來提升SMOTE的方法。
For each point p in S:
1. Compute its m nearest neighbors in T. Call this set Mp and let m'= |Mp ∩ L|.
2. If m'= m, p is a noisy example. Ignore p and continue to the next point.
3. If 0 ≤ m'≤m/2, p is safe. Ignore p and continue to the next point.
4. If m/2 ≤ m'≤ m, add p to the set DANGER.
For each point d in DANGER, apply the SMOTE algorithm to generate synthetic examples.
For each point p in S:
1. 計算點p在訓練集T上的m個最近鄰。我們稱這個集合為Mp然後設 m'= |Mp ∩ L| (表示點p的最近鄰中屬於L的數量).
2. If m'= m, p 是一個噪聲,不做任何操作.
3. If 0 ≤m'≤m/2, 則說明p很安全,不做任何操作.
4. If m/2 ≤ m'≤ m, 那麼點p就很危險了,我們需要在這個點附近生成一些新的少數類點,所以我們把它加入到DANGER中.
最後,對於每個在DANGER中的點d,使用SMOTE演算法生成新的樣本.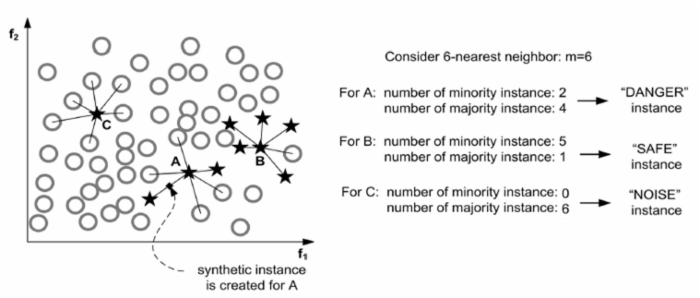
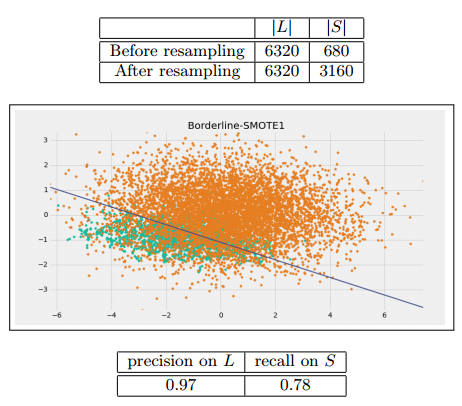
我們應用Borderline-SMOTE1的引數設定為k=5,為了使得r=0.5
Borderline-SMOTE2
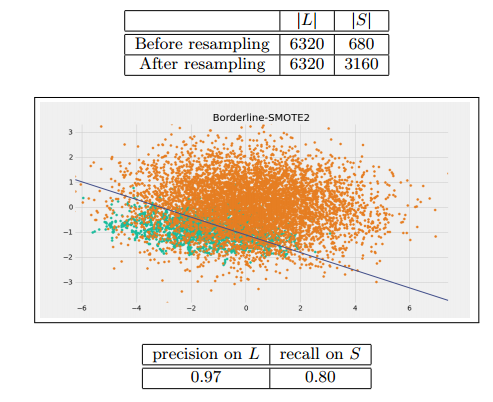
這個與Borderline-SMOTE1很像,只有最後一步不一樣。
在DANGER集中的點不僅從S集中求最近鄰並生成新的少數類點,而且在L集中求最近鄰,並生成新的少數類點,這會使得少數類的點更加接近其真實值。
FOR p in DANGER:
1.在S和L中分別得到k個最近鄰樣本Sk和Lk。
2.在Sk中選出α比例的樣本點和p作隨機的線性插值產生新的少數類樣本
3.在Lk中選出1−α比例的樣本點和p作隨機的線性插值產生新的少數類樣本。為了達到r=0.5 實驗取k=5
組合方法(Combination)
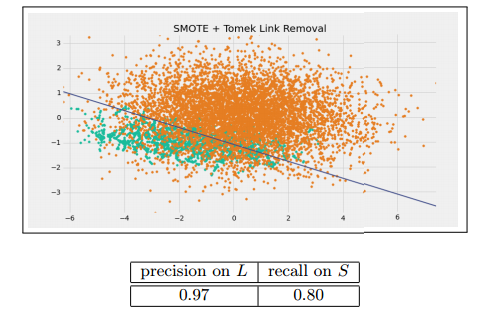
SMOTE + Tomek Link Removal
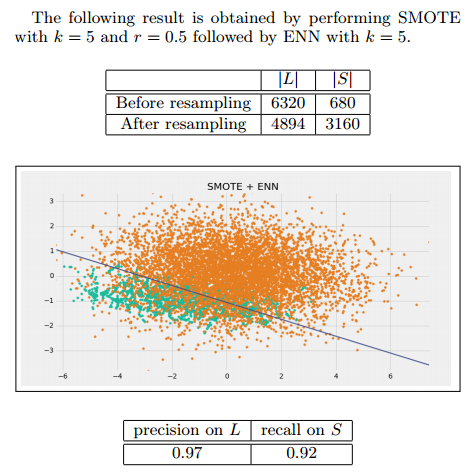
SMOTE + ENN
整合方法(Ensemble)
EasyEnsemble
一個最簡單的整合方法就是不斷從多數類中抽取樣本,使得每個模型的多數類樣本數量和少數類樣本數量都相同,最後將這些模型整合起來。
演算法虛擬碼如下:
1. For i = 1, ..., N:
(a) 隨機從 L中抽取樣本Li使得|Li| = |S|.
(b) 使用Li和S資料集,訓練AdaBoost分類器Fi。
2. 將上述分類器聯合起來
| precision on L | recall on S |
|---|---|
| 0.98 | 0.88 |
BalanceCascad
這個方法跟EasyEnsemble有點像,但不同的是,每次訓練adaboost後都會扔掉已被正確分類的樣本,經過不斷地扔掉樣本後,資料就會逐漸平衡。

該圖來自:劉胥影, 吳建鑫, 周志華. 一種基於級聯模型的類別不平衡資料分類方法[J]. 南京大學學報:自然科學版, 2006, 42(2):148-155
| precision on L | recall on S |
|---|---|
| 0.99 | 0.91 |
原文連結:Survey of resampling techniques for improving classification performance in unbalanced datasets
譯者:喬傑
作為分享主義者(sharism),本人所有網際網路釋出的圖文均遵從CC版權,轉載請保留作者資訊並註明作者a358463121專欄:http://blog.csdn.net/a358463121,如果涉及原始碼請註明GitHub地址:https://github.com/358463121/。商業使用請聯絡作者。