
Elasticsearch如何保證資料不丟失?
上篇文章提到過,在elasticsearch和磁碟之間還有一層cache也就是filesystem cache,大部分新增或者修改,刪除的資料都在這層cache中,如果沒有flush操作,那麼就不能100%保證系統的資料不會丟失,比如突然斷電或者機器宕機了,但實際情況是es中預設是30分鐘才flush一次磁碟,這麼長的時間內,如果發生不可控的故障,那麼是不是必定會丟失資料呢?
很顯然es的設計者早就考慮了這個問題,在兩次full commit操作(flush)之間,如果發生故障也不能丟失資料,那麼es是如何做到的呢?
在es裡面引入了transaction log(簡稱translog),這個log的作用就是每條資料的任何操作都會被記錄到該log中,非常像Hadoop裡面的edits log和hbase裡面的WAL log,如下圖: 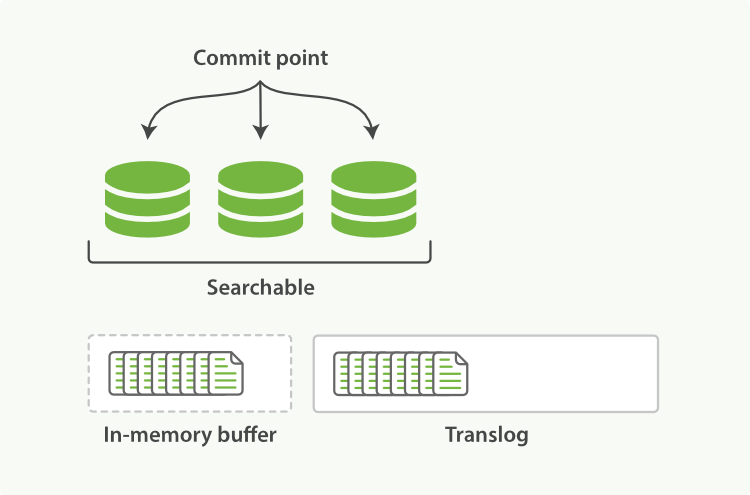
transaction log的工作流程如下:
(1)當一個文件被索引時,它會被新增到記憶體buffer裡面同時也會在translog裡面追加
(2)當每個shard每秒執行一次refresh操作完畢後,記憶體buffer會被清空但translog不會。
過程如下:
2.1 當refresh動作執行完畢後,記憶體buffer裡面的資料會被寫入到一個segment裡面,這個還在cache中,並沒有執行flush命令
2.2 新生成的segment在cache中,會被開啟,這個時候就可以搜尋新加的資料
2.3 最後記憶體buffer裡面的資料會被清空上面過程如下圖: 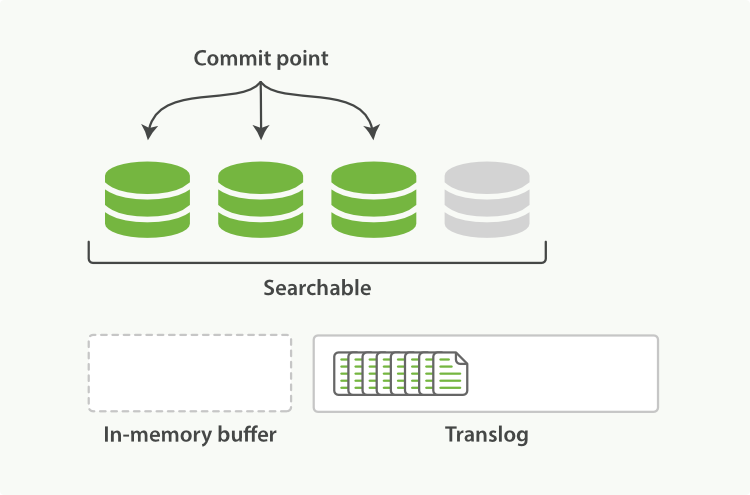
(3)隨著更多的document新增,記憶體buffer區會不斷的refresh,然後clear,但translog數量卻越增越多,如下圖:
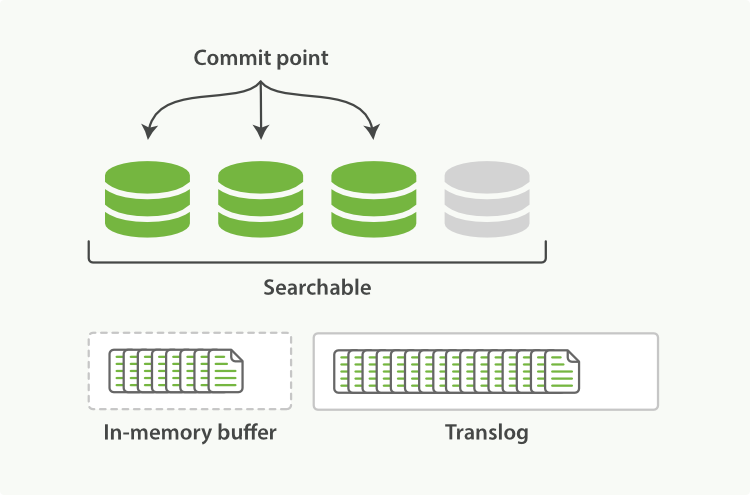
(4)當達到預設的30分鐘時候,translog也會變得非常大,這個時候index要執行一次flush操作,同時會生成一個新的translog檔案,並且要執行full commit操作,流程如下:
4.1 記憶體buffer裡的所有document會被生成一個新的segment
4.2 然後segment被refresh到系統cache後,記憶體buffer會被清空
4.3 接著commit point會被寫入到磁碟上
4.4 filesystem cache會被flush到磁碟上通過fsync操作
4.5 最後舊的translog會被刪除,並會生成一個新的translog如下圖: 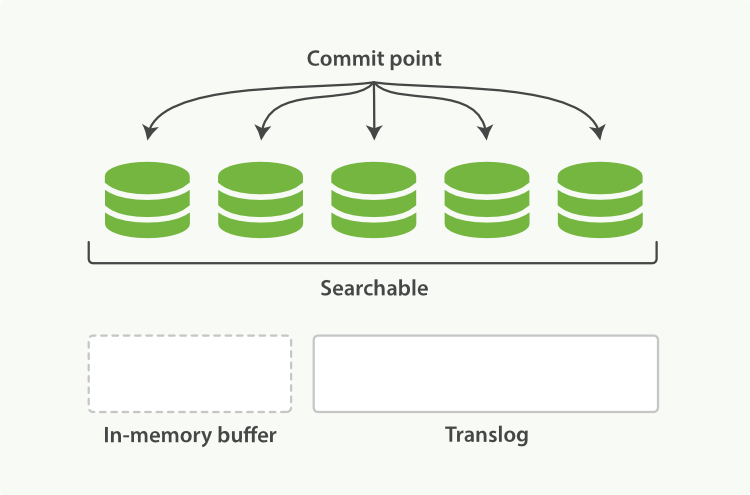
tanslog的作用就是給所有還沒有flush到硬碟上的資料提供持久化記錄,當es重啟時,它首先會根據上一次停止時的commit point檔案把所有已知的segments檔案給恢復出來,然後再通過translog檔案把上一次commit point之後的所有索引變化包括新增,刪除,更新等操作給重放出來。
除此之外tanslog檔案還用於提供一個近實時的CURD操作,當我們通過id讀取,更新或者刪除document時,es在從相關的segments裡面查詢document之前,es會首先從translog裡面獲取最近的變化,這樣就意味著es總是近實時的優先訪問最新版本的資料。
我們知道執行flush命令之後,所有系統cache中的資料會被同步到磁碟上並且會刪除舊的translog然後生成新的translog,預設情況下es的shard會每隔30分鐘自動執行一次flush命令,或者當translog變大超過一定的閾值後。
flush命令的api如下:
POST /blogs/_flush //flush特定的index
POST /_flush?wait_for_ongoing//flush所有的index知道操作完成之後返回響應flush命令基本不需要我們手動操作,但當我們要重啟節點或者關閉索引時,最好提前執行以下flush命令作為優化,因為es恢復索引或者重新開啟索引時,它必須要先把translog裡面的所有操作給恢復,所以也就是說translog越小,recovery恢復操作就越快。
我們知道了tangslog的目的是確保操作記錄不丟失,那麼問題就來了,tangslog有多可靠?
預設情況下,translog會每隔5秒或者在一個寫請求(index,delete,update,bulk)完成之後執行一次fsync操作,這個程序會在所有的主shard和副本shard上執行。 這個守護程序的操作在客戶端是不會收到200 ok的請求。
在每個請求完成之後執行一次translog的fsync操作還是比較耗時的,雖然資料量可能比並不是很大。 預設的es的translog的配置如下:
"index.translog.durability": "request"如果在一個大資料量的叢集中資料並不是很重要,那麼就可以設定成每隔5秒進行非同步fsync操作translog,配置如下:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}上面的配置可以在每個index中設定,並且隨時都可以動態請求生效,所以如果我們的資料相對來說並不是很重要的時候,我們開啟非同步重新整理translog這個操作,這樣效能可能會更好,但壞的情況下可能會丟失5秒之內的資料,所以在設定之前要考慮清楚業務的重要性。
如果不知道怎麼用,那麼就用es預設的配置就行,在每次請求之後就執行translog的fsycn操作從而避免資料丟失。