
23 mysql怎麼保證資料不丟失?
MySQL的wal機制,得到的結論是:只要redo log和binlog 持久化到磁碟,就能確保mysql異常重新啟動後,資料是可以恢復的。
binlog的寫入機制
其實,binlog的寫入邏輯比較簡單:事務執行過程中,先把日誌寫到binlog cache,事務提交的時候,再把binlog cache的內容寫到binlog檔案中。
一個事務的binlog是不能被拆開的,因此不論事務多大,也要確保一次性寫入,這就涉及到binlog cache的儲存問題。
系統給binlog cache分配了一片記憶體,每個執行緒一個,引數binlog_cache用於控制單個執行緒內binlog cache所佔記憶體的大小,如果超過這個值,就要
事務提交的時候,執行器把binlog cache的完整事務寫入到binlog 檔案中,並清空binlog cache,狀態如圖
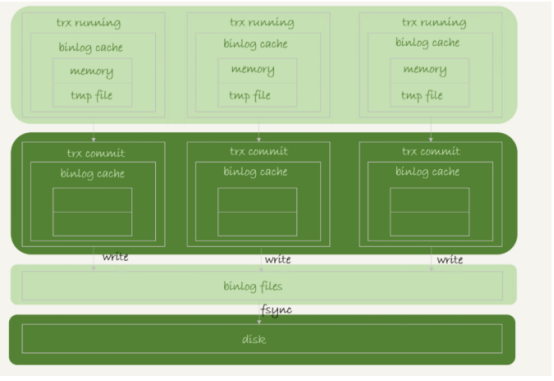
可以看到每個執行緒都自己的binlog cache,但是公用一個binlog檔案。
圖中的write就是把日誌寫入到檔案系統中的page cache,並沒有把資料持久化到磁碟,所以速度比較快
圖中的fsync,將資料持久化到磁碟的操作,一般情況下,我們認為fsync才是佔磁碟的IOPS。
write和fsync由引數sync_binlog控制
1 sync_binlog=0 表示每次提交的時候事務都只write,不fsync
2 sync_binlog=1 表示事務每次提交都會fsync到磁碟
3 sync_binlog=N(N>1)表示每次提交事務都會write,但累計N個事務後才fsync
因此,在出現io瓶頸的情況下,可以調整sync_binlog的值偏大一點,可以提升效能,但是在實際業務場景中,考慮到丟失日誌量的可控性,一般不建議將該值設定為0,比較常見的是設定為100~1000中的某個數值。
但是,將sync_binlog設定為N,對應的風險是:如果主機發生異常重啟,將丟失N個事務的binlog 日誌。
redo log的寫入機制
事務在執行過程中,生成的redo log是要先寫到redo log buffer,那
如果事務執行期間,mysql發生異常重啟,那麼這部分日誌就丟失了,由於事務還沒有提交,丟失的就不影響。
那麼在事務還沒有提交的時候,redo log buffer中的部分日誌會不會持久化到磁碟呢?答案是會有的,這個要從redo log的三種狀態說起
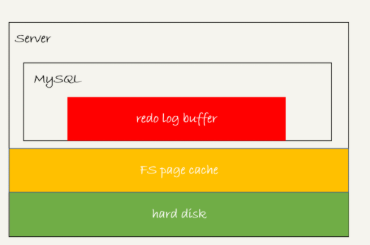
三種狀態分別是:
1 存在redo log buffer中,物理上就是mysql的程序記憶體中,紅色部分。
2 寫到磁碟(write),但是沒有持久化(fsync)到磁碟物理上就是作業系統的page cache,黃色的部分。
3 持久化到磁碟,對應的是hard disk,圖中綠色的部分。
日誌寫到redo log buffer是很快的,write寫到page cache也很快,但是持久化的速度就相對要慢很多。為了控制redo log的寫入策略,innodb提供了引數innodb_fush_log_at_trx_commit,它有三種取值:
1 設定為0的時候,表示每次事務提交都會只把redo log留在redo log buffer中
2 設定為1的時候,事務的每次提交都會持久化到磁碟
3 設定為2的時候,事務的每次提交都會把redo log 寫入到page cache中
Innodb有一個後臺執行緒,每1秒就會把redo log buffer中的寫入到redo log,呼叫write寫入系統的page cache,然後呼叫fsync持久化到磁碟。
注意,事務執行過程中的redo log也是直接寫在redo log buffer中的,這些redo log也會被後臺執行緒一起持久化到磁碟,也就是說,一個沒有提交的事務的redo log,也可能會已經持久化到了磁碟的。
實際上,除了後臺執行緒每秒一次的輪詢操作,還有場景讓沒有提交的事務的redo log寫入到磁碟中。
1 redo log buffer佔用的空間即將達到innodb_log_buffer_size的一半,後臺執行緒會主動寫盤。注意,由於這個事務並沒有提交,所以這個寫盤動作只是write,而沒有呼叫fsync,也就是隻留在了檔案系統page cache中。
2 並行的事務提交的時候,順帶將這個redo log buffer持久到了磁碟。假設事務A執行到一半,已經寫了一些redo log buffer,這時候另外一個執行緒的事務B提交,如果innodb_flush_log_at_trx_commit設定為1,那麼按照這個引數的邏輯,事務B要把redo buffer裡的日誌全部持久化到磁碟,這時候,就會帶上事務A的redo log buffer的日子一起持久化到磁碟。
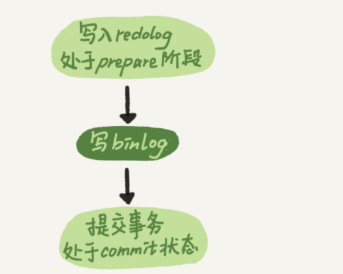
兩階段提交的時候,時序上redo log先prepare,在寫binlog,最後再把redo log commit。
如果把引數innodb_flush_log_at_trx_commit設定為1,那麼redo log在prepare階段就要持久化一次,因為有一個崩潰恢復邏輯是要依賴於prepare的redo log,再加上binlog來恢復。
每秒一次的後臺輪詢刷盤,再加上崩潰恢復的這個邏輯,innodb就認為redo log在commit的時候就不需要fsync了,只會write到檔案系統的page cache中就夠了。
通常我們說的”雙1”模式,就是把引數sync_binlog和innodb_flush_log_at_trx_commit都設定為1。也就說,一個事務完整提交前,需要等待兩次刷盤,一次是redo log(prepare)階段,一次是binlog。
這時候,如果看到mysql的tps是2w的話,每秒就會寫4w次磁碟,但是,用工具測試,磁碟能力也就2w左右,怎麼實現tps為2w呢?
要解釋這個問題,就要用到組提交(group commit)機制了
日誌的邏輯序列號(LSN)是單調遞增的,用來對應redo log的一個個寫入點,每次寫入的長度為length的redo log,LSN就會加上length。
LSN也會寫到innodb的資料頁中,來確保資料不會被多次執行重複的redo log,關於lsn,redo log和checkpoint後面會提到。
如圖所示,是三個併發事務(trx1,trx2,trx3)在prepare階段,都寫完redo log buffer,持久化到磁碟的過程,對應的LSN分別是50,120,160
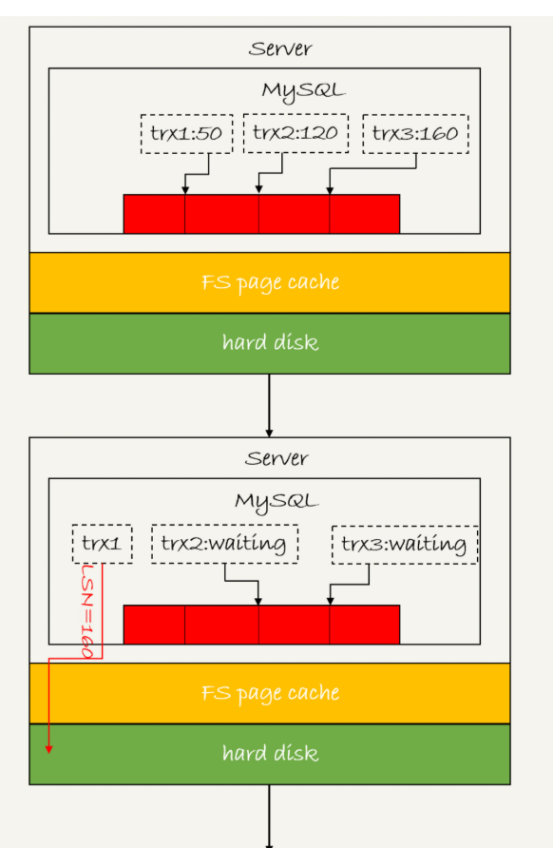
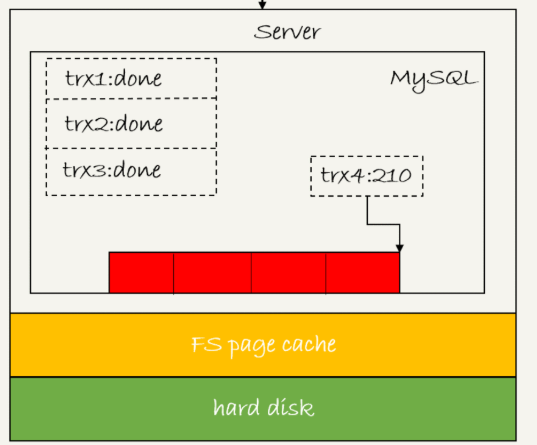
從圖中看到
1 trx1是第一個到達,會被選為這個組的leader
2 等trx1要開始寫盤的時候,這個組裡面已經有了三個事務,這時候LSN變成了160
3 trx1去寫盤的時候,帶的就是lsn=160,因此等trx1返回時,所有lsn小於160的redo log都已經持久化到磁碟
4 這時候trx2和trx3就可以直接返回了。
所以,一次組提交裡面,組員越多,節約磁碟的iops的效果就越好,但如果只是單執行緒壓測,那就還是一個事務對應一次持久化操作了。
在併發更新的場景下,第一個事務寫完redo log buffer以後,接下來這個fsync越晚呼叫,組員就能越多,節約的iops效果就越好。
為了讓一次fsync帶的組員更多,mysql有一個優化,託時間。
圖中,把寫binlog當成一個動作,但實際上寫binlog分為兩步
1 先把binlog從binlog cache中寫道磁碟上的binlog檔案
2 呼叫fsync持久化
Mysql為了讓組提交的效果更好,把redo log做fsync的時間拖到了步驟1之後,上圖變成如下
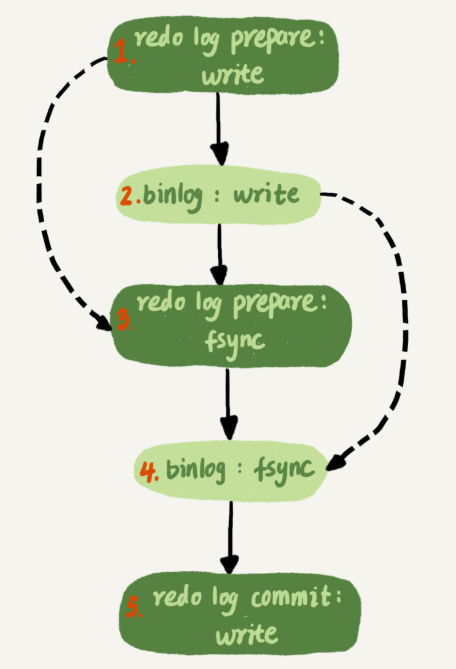
這麼一來,binlog也可以組提交了,在執行上圖的第四步把binlog fsync到磁碟時,如果有多個事務的binlog已經寫完了,也是一起持久化的,這樣也可以減少iops的消耗。
不過通常情況下第3步執行得會很快,所以binlog的write和fsync間的間隔很短,導致能合到一起持久化的binlog比較少,因此binlog的組提交的效果通常不如redo log的效果那麼好。
如果想提升binlog的組提交效果,可以通過設定(5.7)binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count來實現
1 binlog_group_commit_sync_delay引數,表示延遲多少微妙後才呼叫fsync
2 binlog_group_commit_sync_no_delay_count 引數,表示累計多少次後才呼叫fsync
這兩個條件是或的關係,也就說只要滿足其中一個就會呼叫fsync
當binlog_group_commit_sync_delay為0的時候,另外的引數也就無效了。
WAL機制主要得益於兩個方面
1 redo log和binlog都是順序寫,磁碟的順序寫比隨機寫速度快。
2 組提交機制,可以大幅度降低磁碟的iops的消耗。
到這裡,如果mysql出現了效能瓶頸,而且瓶頸在io上,可以考慮呢些方法來提升?
1 設定binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count引數,減少binlog的寫盤次數,這個方法是基於”額外的故意等待來實現”,因此可能會增加語句返回的響應時間,但是沒有丟失資料的風險。
2 將sync_binlog設定為大於1的值(100~1000),這樣做的風險是,主機掉電會丟失binlog日誌。
3 將innodb_flush_log_at_trx_commit=2,這樣做的風險是,主機掉電就丟失資料。
不建議把innodb_flush_log_at_trx_commit設定為0,如果=0的話,redo只儲存在記憶體中,這樣的話,mysql本身異常重啟也會丟失資料,風險太大,
而redo log寫到檔案系統的page cache的速度也是很快,所以這個引數設定為2和0的效能差不多,但是,這樣2就不會在mysql異常重啟時丟失資料。
小結
如果保證binlog和redo log是完整的,就可以保證mysql是crash-safe的。
問題1,執行一個update語句以後,再去執行hexdump命令直接檢視idb檔案,為什麼沒有看到資料改變?
回答:這可能是因為WAL機制的原因,update語句執行完成,innodb只保證redolog,記憶體,可能還沒來得及將資料寫到磁碟。
問題2,為什麼binlog cache每個執行緒自己維護,而redo log buffer是全域性公用?
回答:mysql這麼設計,binlog是不能”被打斷”,一個事務的binlog必須連續寫,因此要整個事務完成後,再一起寫入到檔案裡。
而redo log沒有這個要求,中間生成的日誌可以寫到redo log buffer中,還可以被寫到磁碟中。
問題3,事務執行期間,還沒到提交階段,如果發生crash,redo log肯定丟失,這會不會導致主備不一致。
回答:不會,這時候binlog還在binlog cache裡,沒發給備庫,carsh後,redo log和binlog都沒有,從業務角度看事務還沒有提交,所以資料是一致的。
問題4,如果binlog寫完後發生crash,這時候還沒有給客戶端答覆就重啟了,等客戶端重新連線進來,發現事務已經提交成功,這是不是bug
回答:不是,
假設整個事務提交成功了,redo log commit完成了,備庫也收到binlog並執行了,但是主庫和客戶端網路斷開了,導致事務成功的包返回不了,這時候客戶端收到”網路斷開”異常,這種也是算事務成功的,不能認為是bug
實際上資料庫的crash-safe保證的是:
1 如果客戶端收到事務成功的訊息,事務就一定持久化了
2 如果客戶端收到失敗(比如pk衝突,rollback等)的訊息,事務就一定失敗了
3 如果客戶端收到”執行異常”的訊息,應用需要重連通過當前查詢來繼續後續的邏輯,此時資料庫只需要保證內部(資料和日誌之間,主庫和備庫之間)一致就可以了。