
LDA主題模型及python實現
LDA(Latent Dirichlet Allocation)中文翻譯為:潛在狄利克雷分佈。LDA主題模型是一種文件生成模型,是一種非監督機器學習技術。它認為一篇文件是有多個主題的,而每個主題又對應著不同的詞。一篇文件的構造過程,首先是以一定的概率選擇某個主題,然後再在這個主題下以一定的概率選出某一個詞,這樣就生成了這篇文件的第一個詞。不斷重複這個過程,就生成了整篇文章(當然這裡假定詞與詞之間是沒有順序的,即所有詞無序的堆放在一個大袋子中,稱之為詞袋,這種方式可以使演算法相對簡化一些)。
LDA的使用是上述文件生成過程的逆過程,即根據一篇得到的文件,去尋找出這篇文件的主題,以及這些主題所對應的詞。LDA是NLP領域一個非常重要的非監督演算法。
白話解釋:比如document1的內容為:[自從喬布斯去世之後,iPhone再難以產生革命性的創新了]
通過上述的方法,document1將對應兩個主題topic1,topic2,進而,主題topic1會對應一些詞:[蘋果創始人][蘋果手機],主題topic2會對應一些詞:[重大革新][技術突破]。於是LDA模型的好處顯而易見,就是可以挖掘文件中的潛在詞或者找到兩篇沒有相同詞的文件之間的聯絡。
1 LDA主題模型
假設我們有
篇文件,對應第
個文件中有有
個詞。即輸入為如下圖:
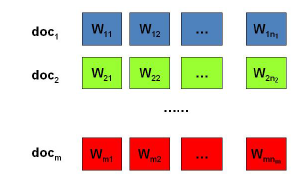
我們的目標是找到每一篇文件的主題分佈和每一個主題中詞的分佈。
在LDA模型中,我們需要先假定一個主題數
,這樣所有的分佈就都基於
個主題展開。那麼具體LDA模型是怎麼樣的呢?具體如下圖:
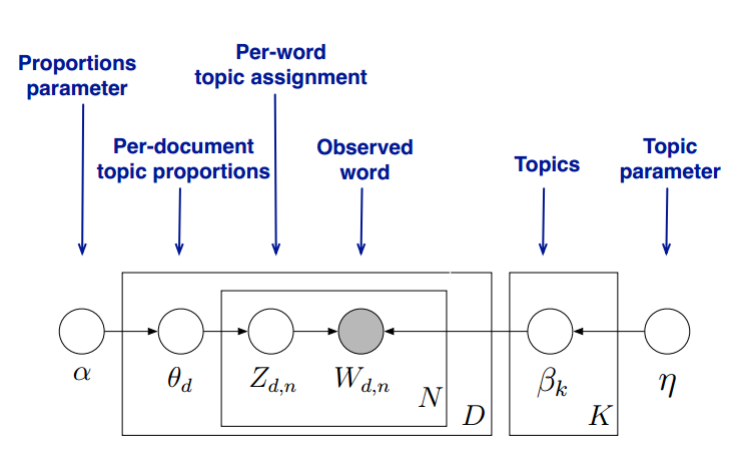
LDA假設文件主題的先驗分佈是Dirichlet分佈,即對於任一文件
, 其主題分佈
為:
其中, 為分佈的超引數,是一個 維向量。
LDA假設主題中詞的先驗分佈是Dirichlet分佈,即對於任一主題
, 其詞分佈
為:
其中, 為分佈的超引數,是一個 維向量。 代表詞彙表裡所有詞的個數。
對於資料中任意一篇文件
中的第
個詞,我們可以從主題分佈
中得到它的主題編號
的分佈為:
而對於該主題編號,得到我們看到的詞
的概率分佈為:
理解LDA主題模型的主要任務就是理解上面的這個模型。這個模型裡,我們有 個文件主題的Dirichlet分佈,而對應的資料有 個主題編號的多項分佈,這樣( )就組成了Dirichlet-multi共軛,可以使用貝葉斯推斷的方法得到基於Dirichlet分佈的文件主題後驗分佈。
如果在第
個文件中,第
個主題的詞的個數為:
, 則對應的多項分佈的計數可以表示為:
利用Dirichlet-multi共軛,得到
的後驗分佈為:
同樣的道理,對於主題與詞的分佈,我們有KK個主題與詞的Dirichlet分佈,而對應的資料有 個主題編號的多項分佈,這樣( )就組成了Dirichlet-multi共軛,可以使用貝葉斯推斷的方法得到基於Dirichlet分佈的主題詞的後驗分佈。
如果在第
個主題中,第
個詞的個數為:
, 則對應的多項分佈的計數可以表示為
利用Dirichlet-multi共軛,得到
的後驗分佈為: