
利用python內建函式,快速統計單詞在文字中出現的次數
阿新 • • 發佈:2019-01-06
python中包含許多標準程式設計資料結構,如list(列表),tuple(元組)、dict(字典)和set(),如果現有的資料型別不能滿足需求,可以派生某個內建型別進行定製,或者使用collections中定義的某個抽象基類作為起點構建一個新的容器型別。
collections模組包含除內建list,dict,tuple 以外的其它容器資料型別。counter作為一個容器,可以跟蹤相同的值增加了多少次。這個類可以用來實現其他語言中常用的 bag 和 multiset 資料結構來實現演算法。
初始化 counter支援三種形式的初始化,條用counter的建構函式時可以提供一個元素序列或者一個包含鍵和計數的字典,還可以使用關鍵字引數將字串名對映到計數。
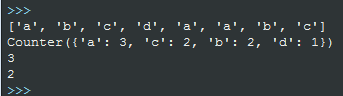
簡單演示:
#coding=utf-8
import collections
str1=['a','b','c','d','a','a','b','c']
m=collections.Counter(str1)
print str1
print m
print m['a']#字元a出現的次數
print m['b']#字元b出現的次數
結果:
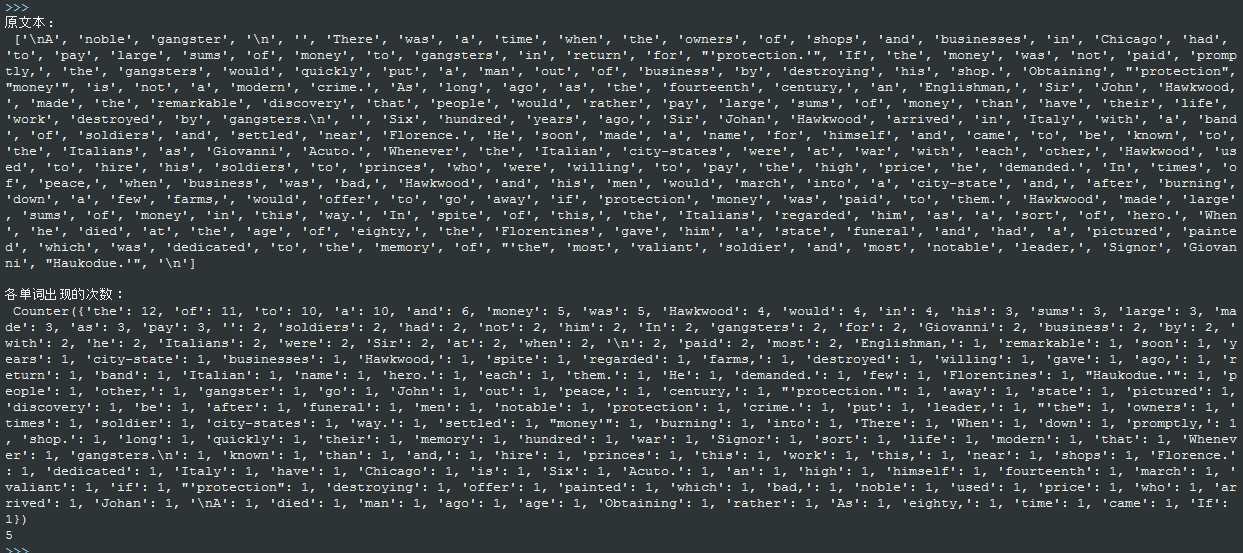
下面選取一個英文的文字,並對其中單詞出現的次數進行統計,返回某個單詞出現的次數
python一行程式碼能實現的功能,就不要用兩行
#coding=utf-8
import collections
import os
with open 結果:
簡短的程式碼,十分易懂,一看就會。