
2萬5千字各大廠前端程式設計師面試經歷-如何寫一個漂亮的簡歷
以下面試題來自騰訊、阿里、網易、餓了麼、美團、拼多多、百度等等大廠綜合起來常考的題目。

如何寫一個漂亮的簡歷
簡歷不是一份記流水賬的東西,而是讓用人方瞭解你的亮點的。
平時有在做一些修改簡歷的收費服務,也算看過蠻多簡歷了。很多簡歷都有如下特徵
喜歡說自己的特長、優點,用人方真的不關注你的性格是否陽光等等
個人技能能夠佔半頁的篇幅,而且長得也都差不多
專案經驗流水賬,比如我會用這個 API 實現了某某功能
簡歷頁數過多,真心看不下去
以上類似簡歷可以說用人方也看了無數份,完全抓不到你的亮點。除非你呆過大廠或者教育背景不錯或者技術棧符合人家要求了,否則基本就是看運氣約面試了。
以下是我經常給別人修改簡歷的意見:
簡歷頁數控制在 2 頁以下
技術名詞注意大小寫
突出個人亮點,擴充內容。比如在專案中如何找到 Bug,解決 Bug 的過程;比如如何發現的效能問題,如何解決效能問題,最終提升了多少效能;比如為何如此選型,目的是什麼,較其他有什麼優點等等。總體思路就是不寫流水賬,突出你在專案中具有不錯的解決問題的能力和獨立思考的能力。
斟酌熟悉、精通等字眼,不要給自己挖坑
確保每一個寫上去的技術點自己都能說出點什麼,杜絕面試官問你一個技術點,你只能答出會用 API 這種減分的情況
做到以上內容,然後在投遞簡歷的過程中加上一份求職信,對你的求職之路相信能幫上很多忙。

如果有想一起學習web前端,想製作酷炫的網頁,可以來一下我的前端群:731771211,從最基礎的HTML+CSS+JavaScript【炫酷特效,遊戲,外掛封裝,設計模式】到移動端HTML5的專案實戰的學習資料都有整理好友都會在裡面交流,分享一些學習的方法和需要注意的小細節,每天也會準時的講一些前端的專案實戰,及免費前端直播課程學習
點選:加入
JS 相關
談談變數提升?
當執行 JS 程式碼時,會生成執行環境,只要程式碼不是寫在函式中的,就是在全域性執行環境中,函式中的程式碼會產生函式執行環境,只此兩種執行環境。
接下來讓我們看一個老生常談的例子,var
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}想必以上的輸出大家肯定都已經明白了,這是因為函式和變數提升的原因。通常提升的解釋是說將宣告的程式碼移動到了頂部,這其實沒有什麼錯誤,便於大家理解。但是更準確的解釋應該是:在生成執行環境時,會有兩個階段。第一個階段是建立的階段,JS 直譯器會找出需要提升的變數和函式,並且給他們提前在記憶體中開闢好空間,函式的話會將整個函式存入記憶體中,變數只宣告並且賦值為 undefined,所以在第二個階段,也就是程式碼執行階段,我們可以直接提前使用。
在提升的過程中,相同的函式會覆蓋上一個函式,並且函式優先於變數提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'var 會產生很多錯誤,所以在 ES6中引入了 let。let 不能在宣告前使用,但是這並不是常說的 let 不會提升,let 提升了,在第一階段記憶體也已經為他開闢好了空間,但是因為這個宣告的特性導致了並不能在宣告前使用。
bind、call、apply 區別
首先說下前兩者的區別。
call 和 apply 都是為了解決改變 this 的指向。作用都是相同的,只是傳參的方式不同。
除了第一個引數外,call 可以接收一個引數列表,apply 只接受一個引數陣列。
let a = {
value: 1
}
function getValue(name, age) {
console.log(name)
console.log(age)
console.log(this.value)
}
getValue.call(a, 'yck', '24')
getValue.apply(a, ['yck', '24'])bind 和其他兩個方法作用也是一致的,只是該方法會返回一個函式。並且我們可以通過 bind 實現柯里化。
如何實現一個 bind 函式
對於實現以下幾個函式,可以從幾個方面思考
- [ ] 不傳入第一個引數,那麼預設為 window
- [ ] 改變了 this 指向,讓新的物件可以執行該函式。那麼思路是否可以變成給新的物件新增一個函式,然後在執行完以後刪除?
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
var _this = this
var args = [...arguments].slice(1)
// 返回一個函式
return function F() {
// 因為返回了一個函式,我們可以 new F(),所以需要判斷
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}如何實現一個 call 函式
Function.prototype.myCall = function (context) {
var context = context || window
// 給 context 新增一個屬性
// getValue.call(a, 'yck', '24') => a.fn = getValue
context.fn = this
// 將 context 後面的引數取出來
var args = [...arguments].slice(1)
// getValue.call(a, 'yck', '24') => a.fn('yck', '24')
var result = context.fn(...args)
// 刪除 fn
delete context.fn
return result
}如何實現一個 apply 函式
Function.prototype.myApply = function (context) {
var context = context || window
context.fn = this
var result
// 需要判斷是否儲存第二個引數
// 如果存在,就將第二個引數展開
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}簡單說下原型鏈
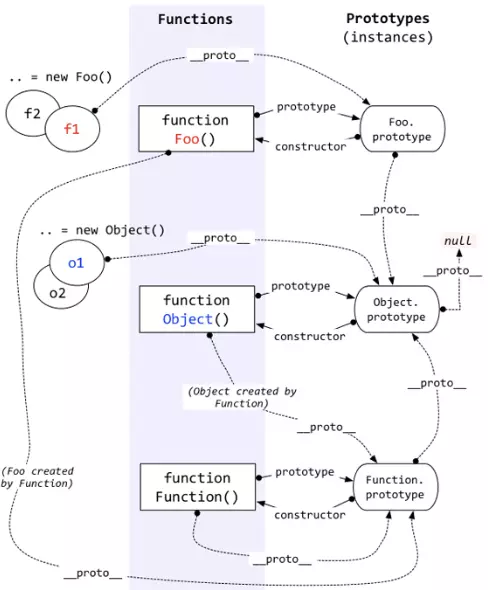
每個函式都有 prototype 屬性,除了 Function.prototype.bind(),該屬性指向原型。
每個物件都有 proto 屬性,指向了建立該物件的建構函式的原型。其實這個屬性指向了 [[prototype]],但是 [[prototype]] 是內部屬性,我們並不能訪問到,所以使用 proto 來訪問。
物件可以通過 proto 來尋找不屬於該物件的屬性,proto 將物件連線起來組成了原型鏈。
如果你想更進一步的瞭解原型,可以仔細閱讀 深度解析原型中的各個難點。
怎麼判斷物件型別?
可以通過 Object.prototype.toString.call(xx)。這樣我們就可以獲得類似 [object Type] 的字串。
instanceof 可以正確的判斷物件的型別,因為內部機制是通過判斷物件的原型鏈中是不是能找到型別的 prototype。
箭頭函式的特點
function a() {
return () => {
return () => {
console.log(this)
}
}
}
console.log(a()()())箭頭函式其實是沒有 this 的,這個函式中的 this 只取決於他外面的第一個不是箭頭函式的函式的 this。在這個例子中,因為呼叫 a 符合前面程式碼中的第一個情況,所以 this 是 window。並且 this 一旦綁定了上下文,就不會被任何程式碼改變。
This
this 是很多人會混淆的概念,但是其實他一點都不難,你只需要記住幾個規則就可以了。
function foo() {
console.log(this.a)
}
var a = 1
foo()
var obj = {
a: 2,
foo: foo
}
obj.foo()
// 以上兩者情況 `this` 只依賴於呼叫函式前的物件,優先順序是第二個情況大於第一個情況
// 以下情況是優先順序最高的,`this` 只會繫結在 `c` 上,不會被任何方式修改 `this` 指向
var c = new foo()
c.a = 3
console.log(c.a)
// 還有種就是利用 call,apply,bind 改變 this,這個優先順序僅次於 newasync、await 優缺點
async 和 await 相比直接使用 Promise 來說,優勢在於處理 then 的呼叫鏈,能夠更清晰準確的寫出程式碼。缺點在於濫用 await 可能會導致效能問題,因為 await 會阻塞程式碼,也許之後的非同步程式碼並不依賴於前者,但仍然需要等待前者完成,導致程式碼失去了併發性。
下面來看一個使用 await 的程式碼。
var a = 0
var b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
a = (await 10) + a
console.log('3', a) // -> '3' 20
}
b()
a++
console.log('1', a) // -> '1' 1對於以上程式碼你可能會有疑惑,這裡說明下原理
- [ ] 首先函式 b 先執行,在執行到 await 10 之前變數 a 還是 0,因為在 await 內部實現了 generators
,generators 會保留堆疊中東西,所以這時候 a = 0 被儲存了下來 - [ ] 因為 await是非同步操作,遇到await就會立即返回一個pending狀態的Promise物件,暫時返回執行程式碼的控制權,使得函式外的程式碼得以繼續執行,所以會先執行
console.log('1', a) - [ ] 這時候同步程式碼執行完畢,開始執行非同步程式碼,將儲存下來的值拿出來使用,這時候 a = 10
- [ ] 然後後面就是常規執行程式碼了
generator 原理
Generator 是 ES6 中新增的語法,和 Promise 一樣,都可以用來非同步程式設計
// 使用 * 表示這是一個 Generator 函式
// 內部可以通過 yield 暫停程式碼
// 通過呼叫 next 恢復執行
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }從以上程式碼可以發現,加上 * 的函式執行後擁有了 next 函式,也就是說函式執行後返回了一個物件。每次呼叫 next 函式可以繼續執行被暫停的程式碼。以下是 Generator 函式的簡單實現
// cb 也就是編譯過的 test 函式
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// 如果你使用 babel 編譯後可以發現 test 函式變成了這樣
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以發現通過 yield 將程式碼分割成幾塊
// 每次執行 next 函式就執行一塊程式碼
// 並且表明下次需要執行哪塊程式碼
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// 執行完畢
case 6:
case "end":
return _context.stop();
}
}
});
}Promise
Promise 是 ES6 新增的語法,解決了回撥地獄的問題。
可以把 Promise 看成一個狀態機。初始是 pending 狀態,可以通過函式 resolve 和 reject ,將狀態轉變為 resolved 或者 rejected 狀態,狀態一旦改變就不能再次變化。
then 函式會返回一個 Promise 例項,並且該返回值是一個新的例項而不是之前的例項。因為 Promise 規範規定除了 pending 狀態,其他狀態是不可以改變的,如果返回的是一個相同例項的話,多個 then 呼叫就失去意義了。
對於 then 來說,本質上可以把它看成是 flatMap
如何實現一個 Promise
// 三種狀態
const PENDING = "pending";
const RESOLVED = "resolved";
const REJECTED = "rejected";
// promise 接收一個函式引數,該函式會立即執行
function MyPromise(fn) {
let _this = this;
_this.currentState = PENDING;
_this.value = undefined;
// 用於儲存 then 中的回撥,只有當 promise
// 狀態為 pending 時才會快取,並且每個例項至多快取一個
_this.resolvedCallbacks = [];
_this.rejectedCallbacks = [];
_this.resolve = function (value) {
if (value instanceof MyPromise) {
// 如果 value 是個 Promise,遞迴執行
return value.then(_this.resolve, _this.reject)
}
setTimeout(() => { // 非同步執行,保證執行順序
if (_this.currentState === PENDING) {
_this.currentState = RESOLVED;
_this.value = value;
_this.resolvedCallbacks.forEach(cb => cb());
}
})
};
_this.reject = function (reason) {
setTimeout(() => { // 非同步執行,保證執行順序
if (_this.currentState === PENDING) {
_this.currentState = REJECTED;
_this.value = reason;
_this.rejectedCallbacks.forEach(cb => cb());
}
})
}
// 用於解決以下問題
// new Promise(() => throw Error('error))
try {
fn(_this.resolve, _this.reject);
} catch (e) {
_this.reject(e);
}
}
MyPromise.prototype.then = function (onResolved, onRejected) {
var self = this;
// 規範 2.2.7,then 必須返回一個新的 promise
var promise2;
// 規範 2.2.onResolved 和 onRejected 都為可選引數
// 如果型別不是函式需要忽略,同時也實現了透傳
// Promise.resolve(4).then().then((value) => console.log(value))
onResolved = typeof onResolved === 'function' ? onResolved : v => v;
onRejected = typeof onRejected === 'function' ? onRejected : r => throw r;
if (self.currentState === RESOLVED) {
return (promise2 = new MyPromise(function (resolve, reject) {
// 規範 2.2.4,保證 onFulfilled,onRjected 非同步執行
// 所以用了 setTimeout 包裹下
setTimeout(function () {
try {
var x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === REJECTED) {
return (promise2 = new MyPromise(function (resolve, reject) {
setTimeout(function () {
// 非同步執行onRejected
try {
var x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === PENDING) {
return (promise2 = new MyPromise(function (resolve, reject) {
self.resolvedCallbacks.push(function () {
// 考慮到可能會有報錯,所以使用 try/catch 包裹
try {
var x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
self.rejectedCallbacks.push(function () {
try {
var x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
}));
}
};
// 規範 2.3
function resolutionProcedure(promise2, x, resolve, reject) {
// 規範 2.3.1,x 不能和 promise2 相同,避免迴圈引用
if (promise2 === x) {
return reject(new TypeError("Error"));
}
// 規範 2.3.2
// 如果 x 為 Promise,狀態為 pending 需要繼續等待否則執行
if (x instanceof MyPromise) {
if (x.currentState === PENDING) {
x.then(function (value) {
// 再次呼叫該函式是為了確認 x resolve 的
// 引數是什麼型別,如果是基本型別就再次 resolve
// 把值傳給下個 then
resolutionProcedure(promise2, value, resolve, reject);
}, reject);
} else {
x.then(resolve, reject);
}
return;
}
// 規範 2.3.3.3.3
// reject 或者 resolve 其中一個執行過得話,忽略其他的
let called = false;
// 規範 2.3.3,判斷 x 是否為物件或者函式
if (x !== null && (typeof x === "object" || typeof x === "function")) {
// 規範 2.3.3.2,如果不能取出 then,就 reject
try {
// 規範 2.3.3.1
let then = x.then;
// 如果 then 是函式,呼叫 x.then
if (typeof then === "function") {
// 規範 2.3.3.3
then.call(
x,
y => {
if (called) return;
called = true;
// 規範 2.3.3.3.1
resolutionProcedure(promise2, y, resolve, reject);
},
e => {
if (called) return;
called = true;
reject(e);
}
);
} else {
// 規範 2.3.3.4
resolve(x);
}
} catch (e) {
if (called) return;
called = true;
reject(e);
}
} else {
// 規範 2.3.4,x 為基本型別
resolve(x);
}
}== 和 ===區別,什麼情況用 ==

上圖中的 toPrimitive 就是物件轉基本型別。
這裡來解析一道題目 [] == ![] // -> true ,下面是這個表示式為何為 true 的步驟
// [] 轉成 true,然後取反變成 false
[] == false
// 根據第 8 條得出
[] == ToNumber(false)
[] == 0
// 根據第 10 條得出
ToPrimitive([]) == 0
// [].toString() -> ''
'' == 0
// 根據第 6 條得出
0 == 0 // -> true=== 用於判斷兩者型別和值是否相同。 在開發中,對於後端返回的 code,可以通過 == 去判斷。
垃圾回收
V8 實現了準確式 GC,GC 演算法採用了分代式垃圾回收機制。因此,V8 將記憶體(堆)分為新生代和老生代兩部分。
新生代演算法
新生代中的物件一般存活時間較短,使用 Scavenge GC 演算法。
在新生代空間中,記憶體空間分為兩部分,分別為 From 空間和 To 空間。在這兩個空間中,必定有一個空間是使用的,另一個空間是空閒的。新分配的物件會被放入 From 空間中,當 From 空間被佔滿時,新生代 GC 就會啟動了。演算法會檢查 From 空間中存活的物件並複製到 To 空間中,如果有失活的物件就會銷燬。當複製完成後將 From 空間和 To 空間互換,這樣 GC 就結束了。
老生代演算法
老生代中的物件一般存活時間較長且數量也多,使用了兩個演算法,分別是標記清除演算法和標記壓縮演算法。
在講演算法前,先來說下什麼情況下物件會出現在老生代空間中:
- [ ] 新生代中的物件是否已經經歷過一次 Scavenge 演算法,如果經歷過的話,會將物件從新生代空間移到老生代空間中。
- [ ] To 空間的物件佔比大小超過 25 %。在這種情況下,為了不影響到記憶體分配,會將物件從新生代空間移到老生代空間中。
老生代中的空間很複雜,有如下幾個空間
enum AllocationSpace {
// TODO(v8:7464): Actually map this space's memory as read-only.
RO_SPACE, // 不變的物件空間
NEW_SPACE, // 新生代用於 GC 複製演算法的空間
OLD_SPACE, // 老生代常駐物件空間
CODE_SPACE, // 老生代程式碼物件空間
MAP_SPACE, // 老生代 map 物件
LO_SPACE, // 老生代大空間物件
NEW_LO_SPACE, // 新生代大空間物件
FIRST_SPACE = RO_SPACE,
LAST_SPACE = NEW_LO_SPACE,
FIRST_GROWABLE_PAGED_SPACE = OLD_SPACE,
LAST_GROWABLE_PAGED_SPACE = MAP_SPACE
};在老生代中,以下情況會先啟動標記清除演算法:
- [ ] 某一個空間沒有分塊的時候
- [ ] 空間中被物件超過一定限制
- [ ] 空間不能保證新生代中的物件移動到老生代中
在這個階段中,會遍歷堆中所有的物件,然後標記活的物件,在標記完成後,銷燬所有沒有被標記的物件。在標記大型對記憶體時,可能需要幾百毫秒才能完成一次標記。這就會導致一些效能上的問題。為了解決這個問題,2011 年,V8 從 stop-the-world 標記切換到增量標誌。在增量標記期間,GC 將標記工作分解為更小的模組,可以讓 JS 應用邏輯在模組間隙執行一會,從而不至於讓應用出現停頓情況。但在 2018 年,GC 技術又有了一個重大突破,這項技術名為併發標記。該技術可以讓 GC 掃描和標記物件時,同時允許 JS 執行
清除物件後會造成堆記憶體出現碎片的情況,當碎片超過一定限制後會啟動壓縮演算法。在壓縮過程中,將活的物件像一端移動,直到所有物件都移動完成然後清理掉不需要的記憶體。
閉包
閉包的定義很簡單:函式 A 返回了一個函式 B,並且函式 B 中使用了函式 A 的變數,函式 B 就被稱為閉包。
function A() {
let a = 1
function B() {
console.log(a)
}
return B
}你是否會疑惑,為什麼函式 A 已經彈出呼叫棧了,為什麼函式 B 還能引用到函式 A 中的變數。因為函式 A 中的變數這時候是儲存在堆上的。現在的 JS 引擎可以通過逃逸分析辨別出哪些變數需要儲存在堆上,哪些需要儲存在棧上。
經典面試題,迴圈中使用閉包解決 var 定義函式的問題
for ( var i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}首先因為 setTimeout 是個非同步函式,所有會先把迴圈全部執行完畢,這時候 i 就是 6 了,所以會輸出一堆 6。
解決辦法兩種,第一種使用閉包
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}第二種就是使用 setTimeout 的第三個引數
for ( var i=1; i<=5; i++) {
setTimeout( function timer(j) {
console.log( j );
}, i*1000, i);
}第三種就是使用 let 定義 i 了
for ( let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}因為對於 let 來說,他會建立一個塊級作用域,相當於
{ // 形成塊級作用域
let i = 0
{
let ii = i
setTimeout( function timer() {
console.log( ii );
}, i*1000 );
}
i++
{
let ii = i
}
i++
{
let ii = i
}
...
}基本資料型別和引⽤型別在儲存上的差別
前者儲存在棧上,後者儲存在堆上
瀏覽器 Eventloop 和 Node 中的有什麼區別
眾所周知 JS 是門非阻塞單執行緒語言,因為在最初 JS 就是為了和瀏覽器互動而誕生的。如果 JS 是門多執行緒的語言話,我們在多個執行緒中處理 DOM 就可能會發生問題(一個執行緒中新加節點,另一個執行緒中刪除節點),當然可以引入讀寫鎖解決這個問題。
JS 在執行的過程中會產生執行環境,這些執行環境會被順序的加入到執行棧中。如果遇到非同步的程式碼,會被掛起並加入到 Task(有多種 task) 佇列中。一旦執行棧為空,Event Loop 就會從 Task 佇列中拿出需要執行的程式碼並放入執行棧中執行,所以本質上來說 JS 中的非同步還是同步行為。
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');以上程式碼雖然 setTimeout 延時為 0,其實還是非同步。這是因為 HTML5 標準規定這個函式第二個引數不得小於 4 毫秒,不足會自動增加。所以 setTimeout 還是會在 script end 之後列印。
不同的任務源會被分配到不同的 Task 佇列中,任務源可以分為 微任務(microtask) 和 巨集任務(macrotask)。在 ES6 規範中,microtask 稱為 jobs,macrotask 稱為 task。
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout以上程式碼雖然 setTimeout 寫在 Promise 之前,但是因為 Promise 屬於微任務而 setTimeout 屬於巨集任務,所以會有以上的列印。
微任務包括 process.nextTick ,promise ,Object.observe ,MutationObserver
巨集任務包括 script , setTimeout ,setInterval ,setImmediate ,I/O ,UI rendering
很多人有個誤區,認為微任務快於巨集任務,其實是錯誤的。因為巨集任務中包括了 script ,瀏覽器會先執行一個巨集任務,接下來有非同步程式碼的話就先執行微任務。
所以正確的一次 Event loop 順序是這樣的
1.執行同步程式碼,這屬於巨集任務
2.執行棧為空,查詢是否有微任務需要執行
3.執行所有微任務
4.必要的話渲染 UI
5.然後開始下一輪 Event loop,執行巨集任務中的非同步程式碼
通過上述的 Event loop 順序可知,如果巨集任務中的非同步程式碼有大量的計算並且需要操作 DOM 的話,為了更快的 介面響應,我們可以把操作 DOM 放入微任務中。
Node 中的 Event loop
Node 中的 Event loop 和瀏覽器中的不相同。
Node 的 Event loop 分為6個階段,它們會按照順序反覆執行
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘timer
timers 階段會執行 setTimeout 和 setInterval
一個 timer 指定的時間並不是準確時間,而是在達到這個時間後儘快執行回撥,可能會因為系統正在執行別的事務而延遲。
下限的時間有一個範圍:[1, 2147483647] ,如果設定的時間不在這個範圍,將被設定為1。
I/O
I/O 階段會執行除了 close 事件,定時器和 setImmediate 的回撥
idle, prepare
idle, prepare 階段內部實現
poll
poll 階段很重要,這一階段中,系統會做兩件事情
執行到點的定時器
執行 poll 佇列中的事件
並且當 poll 中沒有定時器的情況下,會發現以下兩件事情
如果 poll 佇列不為空,會遍歷回撥佇列並同步執行,直到佇列為空或者系統限制
如果 poll 佇列為空,會有兩件事發生
如果有 setImmediate 需要執行,poll 階段會停止並且進入到 check 階段執行 setImmediate
如果沒有 setImmediate 需要執行,會等待回撥被加入到佇列中並立即執行回撥
如果有別的定時器需要被執行,會回到 timer 階段執行回撥。
check
check 階段執行 setImmediate
close callbacks
close callbacks 階段執行 close 事件
並且在 Node 中,有些情況下的定時器執行順序是隨機的
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 這裡可能會輸出 setTimeout,setImmediate
// 可能也會相反的輸出,這取決於效能
// 因為可能進入 event loop 用了不到 1 毫秒,這時候會執行 setImmediate
// 否則會執行 setTimeout當然在這種情況下,執行順序是相同的
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// 因為 readFile 的回撥在 poll 中執行
// 發現有 setImmediate ,所以會立即跳到 check 階段執行回撥
// 再去 timer 階段執行 setTimeout
// 所以以上輸出一定是 setImmediate,setTimeout上面介紹的都是 macrotask 的執行情況,microtask 會在以上每個階段完成後立即執行。
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// 以上程式碼在瀏覽器和 node 中列印情況是不同的
// 瀏覽器中一定列印 timer1, promise1, timer2, promise2
// node 中可能列印 timer1, timer2, promise1, promise2
// 也可能列印 timer1, promise1, timer2, promise2Node 中的 process.nextTick 會先於其他 microtask 執行。
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
process.nextTick(() => {
console.log("nextTick");
});
// nextTick, timer1, promise1setTimeout 倒計時誤差
JS 是單執行緒的,所以 setTimeout 的誤差其實是無法被完全解決的,原因有很多,可能是回撥中的,有可能是瀏覽器中的各種事件導致。這也是為什麼頁面開久了,定時器會不準的原因,當然我們可以通過一定的辦法去減少這個誤差。
以下是一個相對準備的倒計時實現
var period = 60 * 1000 * 60 * 2
var startTime = new Date().getTime();
var count = 0
var end = new Date().getTime() + period
var interval = 1000
var currentInterval = interval
function loop() {
count++
var offset = new Date().getTime() - (startTime + count * interval); // 程式碼執行所消耗的時間
var diff = end - new Date().getTime()
var h = Math.floor(diff / (60 * 1000 * 60))
var hdiff = diff % (60 * 1000 * 60)
var m = Math.floor(hdiff / (60 * 1000))
var mdiff = hdiff % (60 * 1000)
var s = mdiff / (1000)
var sCeil = Math.ceil(s)
var sFloor = Math.floor(s)
currentInterval = interval - offset // 得到下一次迴圈所消耗的時間
console.log('時:'+h, '分:'+m, '毫秒:'+s, '秒向上取整:'+sCeil, '程式碼執行時間:'+offset, '下次迴圈間隔'+currentInterval) // 列印 時 分 秒 程式碼執行時間 下次迴圈間隔
setTimeout(loop, currentInterval)
}
setTimeout(loop, currentInterval)防抖
你是否在日常開發中遇到一個問題,在滾動事件中需要做個複雜計算或者實現一個按鈕的防二次點選操作。
這些需求都可以通過函式防抖動來實現。尤其是第一個需求,如果在頻繁的事件回撥中做複雜計算,很有可能導致頁面卡頓,不如將多次計算合併為一次計算,只在一個精確點做操作。
PS:防抖和節流的作用都是防止函式多次呼叫。區別在於,假設一個使用者一直觸發這個函式,且每次觸發函式的間隔小於wait,防抖的情況下只會呼叫一次,而節流的 情況會每隔一定時間(引數wait)呼叫函式。
我們先來看一個袖珍版的防抖理解一下防抖的實現:
// func是使用者傳入需要防抖的函式
// wait是等待時間
const debounce = (func, wait = 50) => {
// 快取一個定時器id
let timer = 0
// 這裡返回的函式是每次使用者實際呼叫的防抖函式
// 如果已經設定過定時器了就清空上一次的定時器
// 開始一個新的定時器,延遲執行使用者傳入的方法
return function(...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
// 不難看出如果使用者呼叫該函式的間隔小於wait的情況下,上一次的時間還未到就被清除了,並不會執行函式這是一個簡單版的防抖,但是有缺陷,這個防抖只能在最後呼叫。一般的防抖會有immediate選項,表示是否立即呼叫。這兩者的區別,舉個栗子來說:
-
[ ] 例如在搜尋引擎搜尋問題的時候,我們當然是希望使用者輸入完最後一個字才呼叫查詢介面,這個時候適用延遲執行的防抖函式,它總是在一連串(間隔小於wait的)函式觸發之後呼叫。
- [ ] 例如使用者給interviewMap點star的時候,我們希望使用者點第一下的時候就去呼叫介面,並且成功之後改變star按鈕的樣子,使用者就可以立馬得到反饋是否star成功了,這個情況適用立即執行的防抖函式,它總是在第一次呼叫,並且下一次呼叫必須與前一次呼叫的時間間隔大於wait才會觸發。
下面我們來實現一個帶有立即執行選項的防抖函式
// 這個是用來獲取當前時間戳的
function now() {
return +new Date()
}
/**
* 防抖函式,返回函式連續呼叫時,空閒時間必須大於或等於 wait,func 才會執行
*
* @param {function} func 回撥函式
* @param {number} wait 表示時間視窗的間隔
* @param {boolean} immediate 設定為ture時,是否立即呼叫函式
* @return {function} 返回客戶呼叫函式
*/
function debounce (func, wait = 50, immediate = true) {
let timer, context, args
// 延遲執行函式
const later = () => setTimeout(() => {
// 延遲函式執行完畢,清空快取的定時器序號
timer = null
// 延遲執行的情況下,函式會在延遲函式中執行
// 使用到之前快取的引數和上下文
if (!immediate) {
func.apply(context, args)
context = args = null
}
}, wait)
// 這裡返回的函式是每次實際呼叫的函式
return function(...params) {
// 如果沒有建立延遲執行函式(later),就建立一個
if (!timer) {
timer = later()
// 如果是立即執行,呼叫函式
// 否則快取引數和呼叫上下文
if (immediate) {
func.apply(this, params)
} else {
context = this
args = params
}
// 如果已有延遲執行函式(later),呼叫的時候清除原來的並重新設定一個
// 這樣做延遲函式會重新計時
} else {
clearTimeout(timer)
timer = later()
}
}
}這是一個簡單版的防抖,但是有缺陷,這個防抖只能在最後呼叫。一般的防抖會有immediate選項,表示是否立即呼叫。這兩者的區別,舉個栗子來說:
- [ ] 例如在搜尋引擎搜尋問題的時候,我們當然是希望使用者輸入完最後一個字才呼叫查詢介面,這個時候適用延遲執行的防抖函式,它總是在一連串(間隔小於wait的)函式觸發之後呼叫。
- [ ] 例如使用者給interviewMap點star的時候,我們希望使用者點第一下的時候就去呼叫介面,並且成功之後改變star按鈕的樣子,使用者就可以立馬得到反饋是否star成功了,這個情況適用立即執行的防抖函式,它總是在第一次呼叫,並且下一次呼叫必須與前一次呼叫的時間間隔大於wait才會觸發。
下面我們來實現一個帶有立即執行選項的防抖函式
// 這個是用來獲取當前時間戳的
function now() {
return +new Date()
}
/**
* 防抖函式,返回函式連續呼叫時,空閒時間必須大於或等於 wait,func 才會執行
*
* @param {function} func 回撥函式
* @param {number} wait 表示時間視窗的間隔
* @param {boolean} immediate 設定為ture時,是否立即呼叫函式
* @return {function} 返回客戶呼叫函式
*/
function debounce (func, wait = 50, immediate = true) {
let timer, context, args
// 延遲執行函式
const later = () => setTimeout(() => {
// 延遲函式執行完畢,清空快取的定時器序號
timer = null
// 延遲執行的情況下,函式會在延遲函式中執行
// 使用到之前快取的引數和上下文
if (!immediate) {
func.apply(context, args)
context = args = null
}
}, wait)
// 這裡返回的函式是每次實際呼叫的函式
return function(...params) {
// 如果沒有建立延遲執行函式(later),就建立一個
if (!timer) {
timer = later()
// 如果是立即執行,呼叫函式
// 否則快取引數和呼叫上下文
if (immediate) {
func.apply(this, params)
} else {
context = this
args = params
}
// 如果已有延遲執行函式(later),呼叫的時候清除原來的並重新設定一個
// 這樣做延遲函式會重新計時
} else {
clearTimeout(timer)
timer = later()
}
}
}整體函式實現的不難,總結一下。
對於按鈕防點選來說的實現:如果函式是立即執行的,就立即呼叫,如果函式是延遲執行的,就快取上下文和引數,放到延遲函式中去執行。一旦我開始一個定時器,只要我定時器還在,你每次點選我都重新計時。一旦你點累了,定時器時間到,定時器重置為 null,就可以再次點選了。
對於延時執行函式來說的實現:清除定時器ID,如果是延遲呼叫就呼叫函式
陣列降維
[1, [2], 3].flatMap((v) => v + 1)
// -> [2, 3, 4]
如果想將一個多維陣列徹底的降維,可以這樣實現
const flattenDeep = (arr) => Array.isArray(arr)
? arr.reduce( (a, b) => [...a, ...flattenDeep(b)] , [])
: [arr]
flattenDeep([1, [[2], [3, [4]], 5]])深拷貝
這個問題通常可以通過 JSON.parse(JSON.stringify(object)) 來解決。
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'native'
console.log(b.jobs.first) // FE但是該方法也是有侷限性的:
- [ ] 會忽略 undefined
- [ ] 會忽略 symbol
- [ ] 不能序列化函式
- [ ] 不能解決迴圈引用的物件
let obj = {
a: 1,
b: {
c: 2,
d: 3,
},
}
obj.c = obj.b
obj.e = obj.a
obj.b.c = obj.c
obj.b.d = obj.b
obj.b.e = obj.b.c
let newObj = JSON.parse(JSON.stringify(obj))
console.log(newObj)如果你有這麼一個迴圈引用物件,你會發現你不能通過該方法深拷貝

在遇到函式、 undefined 或者 symbol 的時候,該物件也不能正常的序列化
let a = {
age: undefined,
sex: Symbol('male'),
jobs: function() {},
name: 'yck'
}
let b = JSON.parse(JSON.stringify(a))
console.log(b) // {name: "yck"}你會發現在上述情況中,該方法會忽略掉函式和 undefined 。
但是在通常情況下,複雜資料都是可以序列化的,所以這個函式可以解決大部分問題,並且該函式是內建函式中處理深拷貝效能最快的。當然如果你的資料中含有以上三種情況下,可以使用 lodash 的深拷貝函式。
如果你所需拷貝的物件含有內建型別並且不包含函式,可以使用
MessageChannelfunction structuralClone(obj) {
return new Promise(resolve => {
const {port1, port2} = new MessageChannel();
port2.onmessage = ev => resolve(ev.data);
port1.postMessage(obj);
});
}
var obj = {a: 1, b: {
c: b
}}
// 注意該方法是非同步的
// 可以處理 undefined 和迴圈引用物件
(async () => {
const clone = await structuralClone(obj)
})()typeof 於 instanceof 區別
typeof 對於基本型別,除了 null 都可以顯示正確的型別
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof b // b 沒有宣告,但是還會顯示 undefinedtypeof 對於物件,除了函式都會顯示 object
typeof [] // 'object'
typeof {} // 'object'
typeof console.log // 'function'對於 null 來說,雖然它是基本型別,但是會顯示 object,這是一個存在很久了的 Bug
typeof null // 'object'PS:為什麼會出現這種情況呢?因為在 JS 的最初版本中,使用的是 32 位系統,為了效能考慮使用低位儲存了變數的型別資訊,000 開頭代表是物件,然而 null 表示為全零,所以將它錯誤的判斷為 object 。雖然現在的內部型別判斷程式碼已經改變了,但是對於這個 Bug 卻是一直流傳下來。
instanceof 可以正確的判斷物件的型別,因為內部機制是通過判斷物件的原型鏈中是不是能找到型別的 prototype。
我們也可以試著實現一下 instanceof
function instanceof(left, right) {
// 獲得型別的原型
let prototype = right.prototype
// 獲得物件的原型
left = left.__proto__
// 判斷物件的型別是否等於型別的原型
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}Webpack
優化打包速度
減少檔案搜尋範圍
比如通過別名
loader 的 test,include & exclude
Webpack4 預設壓縮並行
Happypack 併發呼叫
babel 也可以快取編譯
Babel 原理
本質就是編譯器,當代碼轉為字串生成 AST,對 AST 進行轉變最後再生成新的程式碼
分為三步:詞法分析生成 Token,語法分析生成 AST,遍歷 AST,根據外掛變換相應的節點,最後把 AST 轉換為程式碼
如何實現一個外掛
- [ ] 呼叫外掛 apply 函式傳入 compiler 物件
- [ ] 通過 compiler 物件監聽事件
比如你想實現一個編譯結束退出命令的外掛
class BuildEndPlugin {
apply (compiler) {
const afterEmit = (compilation, cb) => {
cb()
setTimeout(function () {
process.exit(0)
}, 1000)
}
compiler.plugin('after-emit', afterEmit)
}
}
module.exports = BuildEndPlugin框架
React 生命週期
在 V16 版本中引入了 Fiber 機制。這個機制一定程度上的影響了部分生命週期的呼叫,並且也引入了新的 2 個 API 來解決問題。
在之前的版本中,如果你擁有一個很複雜的複合元件,然後改動了最上層元件的 state,那麼呼叫棧可能會很長
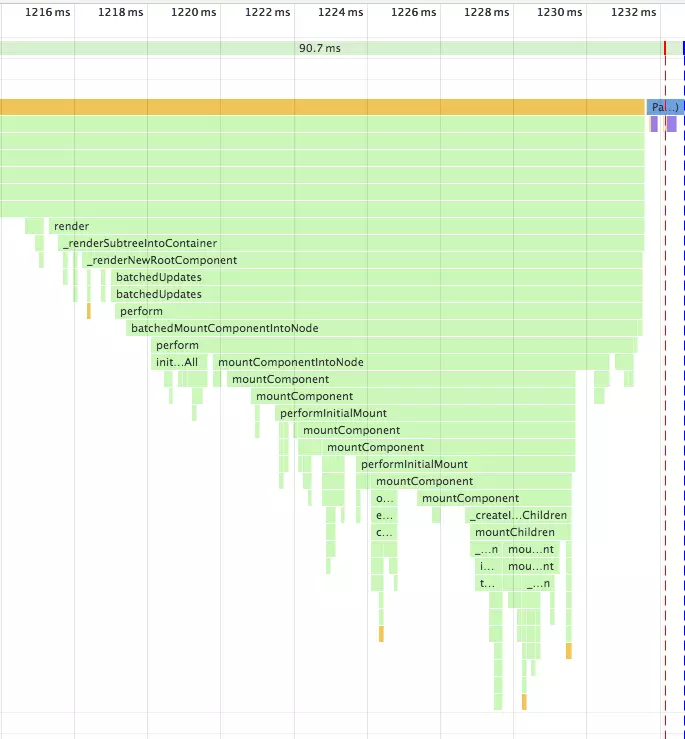
呼叫棧過長,再加上中間進行了複雜的操作,就可能導致長時間阻塞主執行緒,帶來不好的使用者體驗。Fiber 就是為了解決該問題而生。
Fiber 本質上是一個虛擬的堆疊幀,新的排程器會按照優先順序自由排程這些幀,從而將之前的同步渲染改成了非同步渲染,在不影響體驗的情況下去分段計算更新。
對於如何區別優先順序,React 有自己的一套邏輯。對於動畫這種實時性很高的東西,也就是 16 ms 必須渲染一次保證不卡頓的情況下,React 會每 16 ms(以內) 暫停一下更新,返回來繼續渲染動畫。
對於非同步渲染,現在渲染有兩個階段:reconciliation 和 commit 。前者過程是可以打斷的,後者不能暫停,會一直更新介面直到完成。
Reconciliation 階段
componentWillMount
componentWillReceiveProps
shouldComponentUpdate
componentWillUpdate
Commit 階段
componentDidMount
componentDidUpdate
componentWillUnmount
因為 reconciliation 階段是可以被打斷的,所以 reconciliation 階段會執行的生命週期函式就可能會出現呼叫多次的情況,從而引起 Bug。所以對於 reconciliation 階段呼叫的幾個函式,除了 shouldComponentUpdate 以外,其他都應該避免去使用,並且 V16 中也引入了新的 API 來解決這個問題。
getDerivedStateFromProps 用於替換 componentWillReceiveProps ,該函式會在初始化和 update 時被呼叫
class ExampleComponent extends React.Component {
// Initialize state in constructor,
// Or with a property initializer.
state = {};
static getDerivedStateFromProps(nextProps, prevState) {
if (prevState.someMirroredValue !== nextProps.someValue) {
return {
derivedData: computeDerivedState(nextProps),
someMirroredValue: nextProps.someValue
};
}
// Return null to indicate no change to state.
return null;
}
}getSnapshotBeforeUpdate 用於替換 componentWillUpdate ,該函式會在 update 後 DOM 更新前被呼叫,用於讀取最新的 DOM 資料。
V16 生命週期函式用法建議
class ExampleComponent extends React.Component {
// 用於初始化 state
constructor() {}
// 用於替換 `componentWillReceiveProps` ,該函式會在初始化和 `update` 時被呼叫
// 因為該函式是靜態函式,所以取不到 `this`
// 如果需要對比 `prevProps` 需要單獨在 `state` 中維護
static getDerivedStateFromProps(nextProps, prevState) {}
// 判斷是否需要更新元件,多用於元件效能優化
shouldComponentUpdate(nextProps, nextState) {}
// 元件掛載後呼叫
// 可以在該函式中進行請求或者訂閱
componentDidMount() {}
// 用於獲得最新的 DOM 資料
getSnapshotBeforeUpdate() {}
// 元件即將銷燬
// 可以在此處移除訂閱,定時器等等
componentWillUnmount() {}
// 元件銷燬後呼叫
componentDidUnMount() {}
// 元件更新後呼叫
componentDidUpdate() {}
// 渲染元件函式
render() {}
// 以下函式不建議使用
UNSAFE_componentWillMount() {}
UNSAFE_componentWillUpdate(nextProps, nextState) {}
UNSAFE_componentWillReceiveProps(nextProps) {}
}setState
setState 在 React 中是經常使用的一個 API,但是它存在一些問題,可能會導致犯錯,核心原因就是因為這個 API 是非同步的。
首先 setState 的呼叫並不會馬上引起 state 的改變,並且如果你一次呼叫了多個 setState ,那麼結果可能並不如你期待的一樣。
handle() {
// 初始化 `count` 為 0
console.log(this.state.count) // -> 0
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
console.log(this.state.count) // -> 0
}第一,兩次的列印都為 0,因為 setState 是個非同步 API,只有同步程式碼執行完畢才會執行。setState 非同步的原因我認為在於,setState 可能會導致 DOM 的重繪,如果呼叫一次就馬上去進行重繪,那麼呼叫多次就會造成不必要的效能損失。設計成非同步的話,就可以將多次呼叫放入一個佇列中,在恰當的時候統一進行更新過程。
第二,雖然呼叫了三次 setState ,但是 count 的值還是為 1。因為多次呼叫會合併為一次,只有當更新結束後 state 才會改變,三次呼叫等同於如下程式碼
Object.assign(
{},
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
)當然你也可以通過以下方式來實現呼叫三次 setState 使得 count 為 3
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
}如果你想在每次呼叫 setState 後獲得正確的 state ,可以通過如下程式碼實現
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }), () => {
console.log(this.state)
})
}Vue的 nextTick 原理
nextTick 可以讓我們在下次 DOM 更新迴圈結束之後執行延遲迴調,用於獲得更新後的 DOM。
在 Vue 2.4 之前都是使用的 microtasks,但是 microtasks 的優先順序過高,在某些情況下可能會出現比事件冒泡更快的情況,但如果都使用 macrotasks 又可能會出現渲染的效能問題。所以在新版本中,會預設使用 microtasks,但在特殊情況下會使用 macrotasks,比如 v-on。
對於實現 macrotasks ,會先判斷是否能使用 setImmediate ,不能的話降級為 MessageChannel ,以上都不行的話就使用 setTimeout
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (
typeof MessageChannel !== 'undefined' &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]')
) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}nextTick 同時也支援 Promise 的使用,會判斷是否實現了 Promise
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve
// 將回調函式整合進一個數組中
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// 判斷是否可以使用 Promise
// 可以的話給 _resolve 賦值
// 這樣回撥函式就能以 promise 的方式呼叫
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}Vue 生命週期
生命週期函式就是元件在初始化或者資料更新時會觸發的鉤子函式。
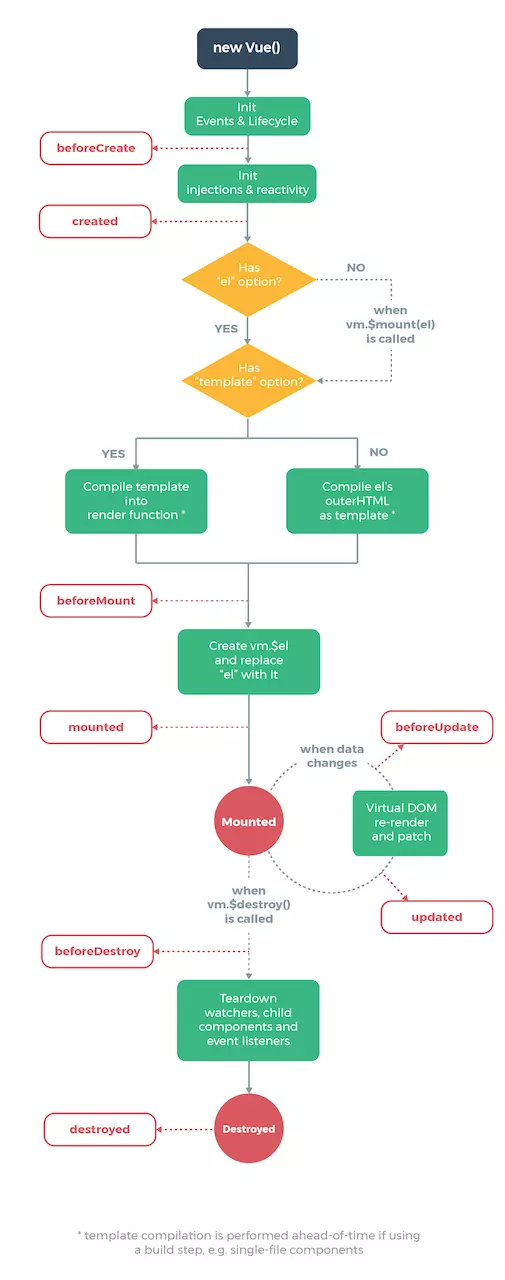
在初始化時,會呼叫以下程式碼,生命週期就是通過 callHook 呼叫的
Vue.prototype._init = function(options) {
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate') // 拿不到 props data
initInjections(vm)
initState(vm)
initProvide(vm)
callHook(vm, 'created')
}可以發現在以上程式碼中,beforeCreate 呼叫的時候,是獲取不到 props 或者 data 中的資料的,因為這些資料的初始化都在 initState 中。
接下來會執行掛載函式
export function mountComponent {
callHook(vm, 'beforeMount')
// ...
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
}beforeMount 就是在掛載前執行的,然後開始建立 VDOM 並替換成真實 DOM,最後執行 mounted 鉤子。這裡會有個判斷邏輯,如果是外部 new Vue({}) 的話,不會存在 $vnode ,所以直接執行 mounted 鉤子了。如果有子元件的話,會遞迴掛載子元件,只有當所有子元件全部掛載完畢,才會執行根元件的掛載鉤子。
接下來是資料更新時會呼叫的鉤子函式
function flushSchedulerQueue() {
// ...
for (index = 0; index < queue.length; index++) {
watcher = queue[index]
if (watcher.before) {
watcher.before() // 呼叫 beforeUpdate
}
id = watcher.id
has[id] = null
watcher.run()
// in dev build, check and stop circular updates.
if (process.env.NODE_ENV !== 'production' && has[id] != null) {
circular[id] = (circular[id] || 0) + 1
if (circular[id] > MAX_UPDATE_COUNT) {
warn(
'You may have an infinite update loop ' +
(watcher.user
? `in watcher with expression "${watcher.expression}"`
: `in a component render function.`),
watcher.vm
)
break
}
}
}
callUpdatedHooks(updatedQueue)
}
function callUpdatedHooks(queue) {
let i = queue.length
while (i--) {
const watcher = queue[i]
const vm = watcher.vm
if (vm._watcher === watcher && vm._isMounted) {
callHook(vm, 'updated')
}
}
}上圖還有兩個生命週期沒有說,分別為 activated 和 deactivated ,這兩個鉤子函式是 keep-alive 元件獨有的。用 keep-alive 包裹的元件在切換時不會進行銷燬,而是快取到記憶體中並執行 deactivated 鉤子函式,命中快取渲染後會執行 actived 鉤子函式。
最後就是銷燬元件的鉤子函數了
Vue.prototype.$destroy = function() {
// ...
callHook(vm, 'beforeDestroy')
vm._isBeingDestroyed = true
// remove self from parent
const parent = vm.$parent
if (parent && !parent._isBeingDestroyed && !vm.$options.abstract) {
remove(parent.$children, vm)
}
// teardown watchers
if (vm._watcher) {
vm._watcher.teardown()
}
let i = vm._watchers.length
while (i--) {
vm._watchers[i].teardown()
}
// remove reference from data ob
// frozen object may not have observer.
if (vm._data.__ob__) {
vm._data.__ob__.vmCount--
}
// call the last hook...
vm._isDestroyed = true
// invoke destroy hooks on current rendered tree
vm.__patch__(vm._vnode, null)
// fire destroyed hook
callHook(vm, 'destroyed')
// turn off all instance listeners.
vm.$off()
// remove __vue__ reference
if (vm.$el) {
vm.$el.__vue__ = null
}
// release circular reference (#6759)
if (vm.$vnode) {
vm.$vnode.parent = null
}
}在執行銷燬操作前會呼叫 beforeDestroy 鉤子函式,然後進行一系列的銷燬操作,如果有子元件的話,也會遞迴銷燬子元件,所有子元件都銷燬完畢後才會執行根元件的 destroyed 鉤子函式。