
Bayesian Personalized Ranking(BPR個性化排序)
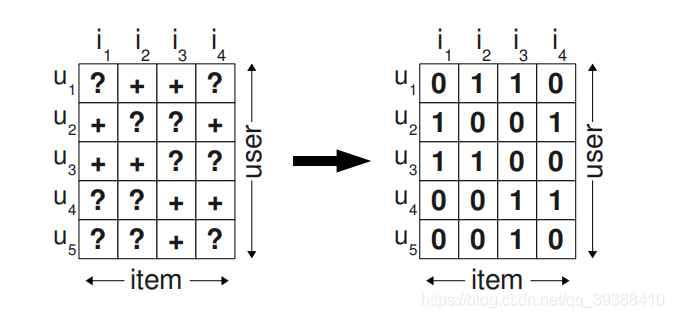
如題,在推薦系統中我們在推薦給使用者的商品中一定是需要先後順序的,即我們需要關心的是使用者將會更喜歡我們所推薦的商品,從而得到–個性化排序。但是沒錯,前幾篇所整理的方法目的也是為了預測使用者喜好,但往往我們只能通過觀察到的正例去估計暗含著負例與缺失值的“?”中,而實際填充也如上圖一樣,一般用0做填充。然後基於此計算出得分,從某種意義上也可以得到使用者優先順序的排序,所以首先同樣的我們需要解決的問題還是:
對於使用者集U和物品集I的對應的 U × I 的預測排序矩陣 X,避免矩陣分解所需要的稠密性,同樣採取分解為兩個矩陣,即:
然後同樣需要尋找最好的W和H,使其與真正X的誤差最小,但是與先前的
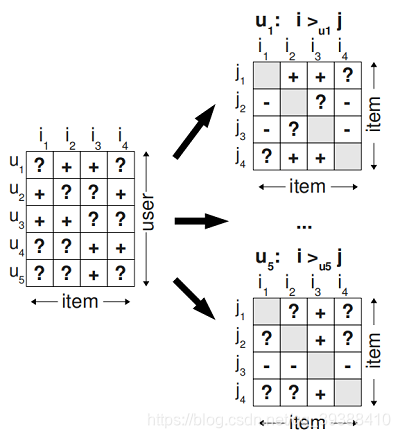
**首先為了排序,引入三元組的概念:即如果使用者u在同時有物品 i 和 j 的時候點選了 i,那麼定義三元組<u,i,j><u,i,j>,即對使用者u來說,i 的排序要比 j 靠前。如上圖中,在左側顯示了觀測資料和一些未知的“?”資料,三元組處理後,變成在右側的,“+” 表示使用者更喜歡項 i 大於 j 項;“-” 表示更喜歡j而不是i。
基於使用者的全序關係的貝葉斯就變成:
其中W和H用
表示,為了得到最好的W,H,即得到最好的
,需要優化後面的這一堆,同樣的分母(某使用者的全序,對所有的都是物品一樣)一樣,可以先捨去不考慮。那麼對於分子第一項可以有最大似然估計:
其中
P(i >u j | θ)即<u,i,j>,i 排名高於 j。
但是其實,既然是排序–定義使 i 大於 j,那麼就使P(i >u j|θ)出現的概率越大越好就行了。那麼
而且如果要是一方的概率越大,那麼另一方就小就好,那麼自然期望他們之間的差異就越大即:
而且這就已經直接是預測矩陣X中的對應位置的值了。即分子第一項變為:
然後分子第二項
,直接使用貝葉斯假設,即
符合正太分佈,而總所周知,正太分佈的對數形式是跟
成比的!(除了優化式子外,居然還能曲線救國,漂亮的完成了正則化的作用??所以直接假設使用引數符合正太分佈的操作設計很巧妙呀)那麼整個下來的的式子就直接變成了: