
基於Inception v3進行單標籤訓練
bottleneck

Inception v3模型由堆疊在一起的許多層組成,TensorBoard的簡化影象如上所示。 這些層是預先訓練的,並且在查詢和總結有助於對大多數影象進行分類的資訊方面已經非常有價值。 對於這個codelab,你只訓練最後一層(下圖中的final_training_ops)。 雖然以前的所有層都保留了已經訓練好的狀態。
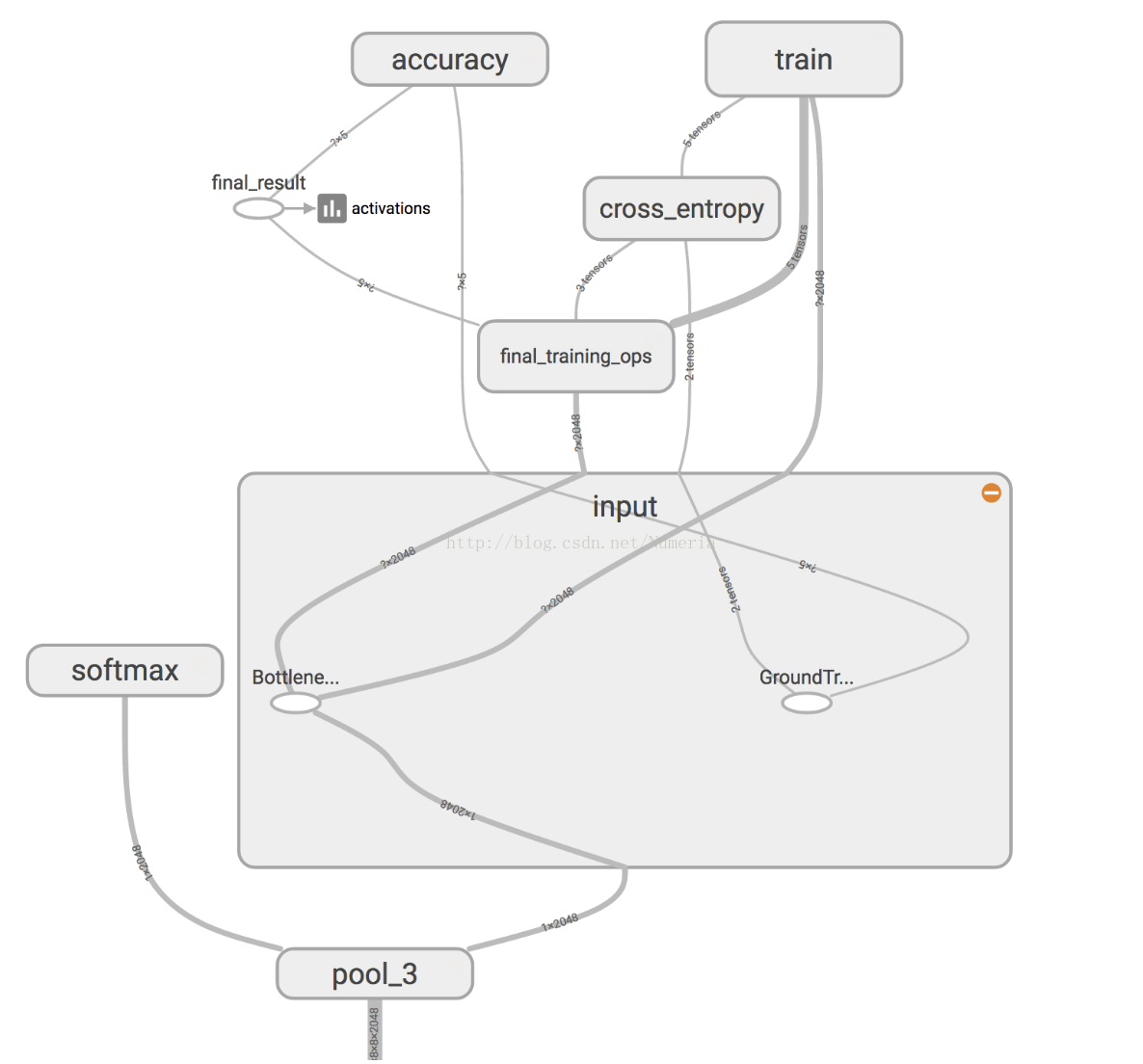
在上圖中,左側標有“softmax”的節點是原始模型的輸出層。 而右側的節點則由再訓練指令碼新增。 再培訓指令碼完成後,會自動刪除額外的節點。
“bottleneck”是我們經常用於實際進行分類的最終輸出層之前的層的非正式術語。 因為,在輸出附近,表示比網路的主體更緊湊。
每個影象在訓練期間重複使用多次。 計算每個影象bottleneck後面的層需要大量的時間。 由於網路的這些較低層沒有被修改,所以它們的輸出可以被快取並重新使用。
所以指令碼正在執行網路的常量部分,以下所有標記為Bottlene ...的節點,並快取結果。
您執行的命令將這些檔案儲存到bottlenecks /目錄。 如果您重新執行指令碼,它們將被重用,因此您不必再等待此部分。
traning
一旦指令碼完成生成所有的“bottleneck”檔案,網路的最後一層的實際訓練就開始了。
訓練通過將每個影象的快取值提供給“bottleneck”層來高效執行。 每個影象的真實標籤也被饋送到標記為GroundTruth的節點。 這兩個輸入就足以計算分類概率,訓練更新以及各種績效指標。
在訓練中,您將看到一系列步進輸出,每個輸出顯示訓練準確性,驗證精度和交叉熵:
訓練準確性顯示在當前訓練批中使用正確類別標記的影象的百分比。
驗證準確性:驗證精確度是來自不同集合的隨機選擇的影象組的精度(正確標記的影象的百分比)。
交叉熵是一個損失函式,可以看出學習過程的進步情況如何(這裡的數字越少越好)。
下圖顯示了模型在訓練時的準確性和交叉熵的進展情況。 如果您的模型已經生成”bottleneck“檔案,您可以通過開啟TensorBoard並點選圖形名稱來顯示模型的進度。 TensorBoard可能會向您的命令列列印警告。 這些可以安全地忽略。


網路效能的真正衡量標準是測量其在不在訓練資料中的資料集的效能。使用驗證精度測量此效能。如果訓練準確度很高,但是驗證精度仍然很低,這意味著網路過度擬合,並且網路正在記憶訓練影象中的特定特徵,這些功能不能更一般地分類影象。
培訓的目標是使交叉熵儘可能小,所以您可以通過關注失敗是否向下傾斜,忽略短期噪音來判斷學習是否正常工作。
預設情況下,此指令碼執行4000個培訓步驟。每個步驟從訓練集中隨機選擇10張影象,從快取中找到”bottleneck“,並將其饋送到最後一層以獲得預測。然後將這些預測與實際標籤進行比較,以通過反向傳播過程更新最終層的權重。
隨著流程的繼續,您應該看到報告的準確性提高。所有的訓練步驟完成後,該指令碼將對與培訓和驗證圖片分開的一組影象進行最終測試精度評估。該測試評估提供了對訓練模型如何在分類任務上執行的最佳估計。
您應該看到精度值在85%到99%之間,儘管訓練過程中隨機性的確切值會因執行而異。 (如果您僅在兩個班上進行訓練,則應該期望更高的精度。)該數值表示在模型完全訓練後給出正確標籤的測試集中的影象的百分比。
五.使用再訓練模型
重新訓練指令碼將會寫出一個Inception v3網路的版本,其中最後一個圖層被重新應用到您的類別為tf_files / retrained_graph.pb以及包含tf_files / retrained_labels.txt標籤的文字檔案。
這是一個python指令碼讀取你的新圖片檔案並開始訓練它
curl -L https://goo.gl/3lTKZs > label_image.py下面我們使用這個指令碼來對一張圖片進行測試:

這是一張雛菊的圖片,測試這個圖片的命令列為
python label_image.py flower_photos/daisy/21652746_cc379e0eea_m.jpg得出的結果為:
daisy (score = 0.99071)
sunflowers (score = 0.00595)
dandelion (score = 0.00252)
roses (score = 0.00049)
tulips (score = 0.00032)
你也通過修改圖片路徑,測試其他圖片。