
PRISMA原理以及python包使用介紹
剛開始一直在尋找PRISMA的相關文件,感覺很少,結果後面才發現在下載包中的vignettes以及inst檔案下面,有對它的詳細介紹以及示例展示,還是自己不夠細心,導致浪費了很長一段時間。QAQ
Introduction
- PRISMA可以高效地處理sally輸出檔案,很快地處理n-gram過程;
- Testing-based feature dimension reduction(降維);
最優矩陣分解
整體流程圖:
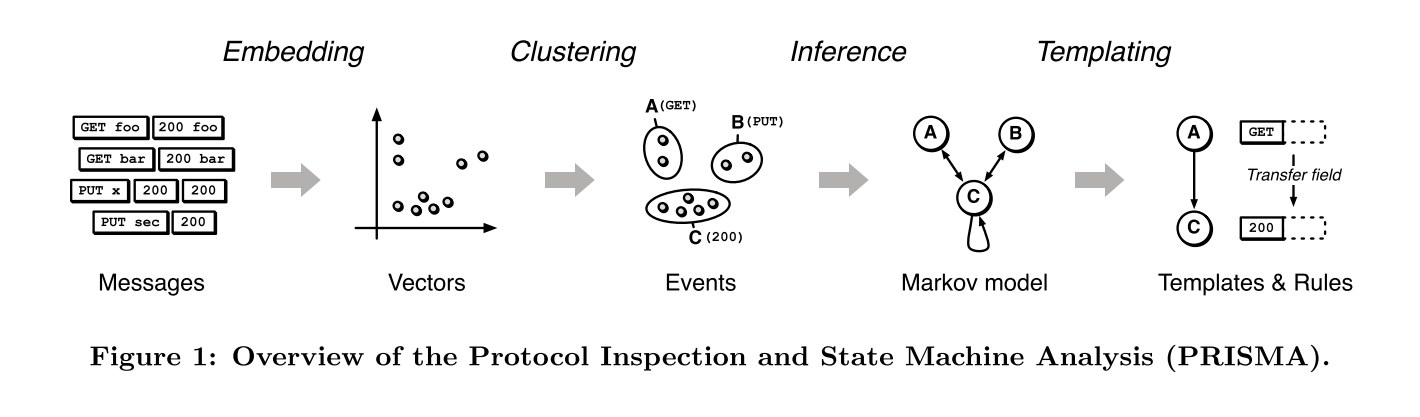
Loading the Data
首先需要 獲得“.sally”檔案,就是通過sally對原始網路流量進行處理;
在目錄/inst/extdata中有提供測試資料集asap,其中原始資料asap.raw如圖所示:

asap.cfg是Sally的配置檔案,通過如下命令得到PRISMA輸入。
sally -c asap.cfg asap.raw asap.sally
python sallyProcessing.py asap.sally asap.fsally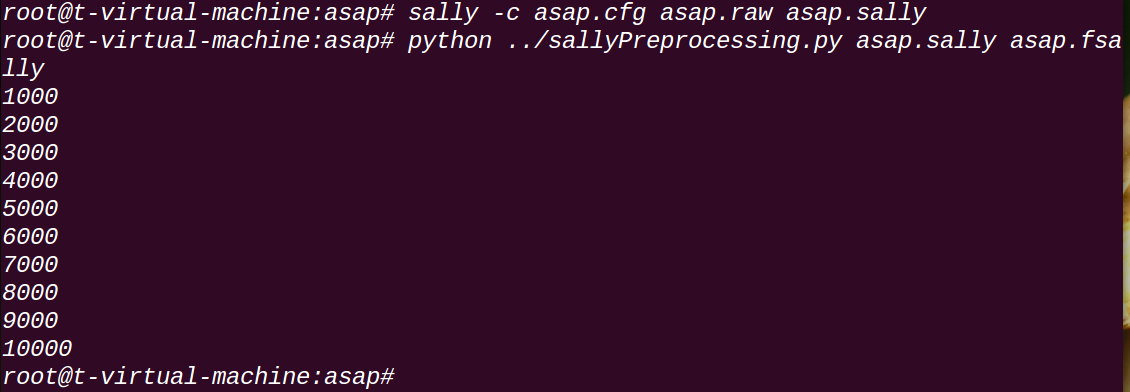
這裡筆者想說一下很重要的一點,就是sally是幹嘛的(之前很久沒有弄懂,終於看了原始碼以及幫助文件之後弄懂了)。
下面以granularity為tokens,輸出格式為“text”為例:
- 首先sally會根據配置檔案中設定的“ngram_delim”來對原始的“.raw”資料進行劃分,當然這裡還會有一個自動對URI進行解碼的過程。劃分了之後,就得到了很多的tokens,把所有的報文序列中分割得到的tokens都作為一個特徵,也作為初始矩陣的一維,所以才會有圖中的“16777216”這麼大的維數,很顯然這是一個稀疏矩陣,選擇用這種格式輸出其實也可以看做是用最簡單的方法來儲存結果,因為真的用矩陣存會相當大,所以就只記錄下來“value”為“1”的項;

- 然後,對於這些token一個一個的在報文序列中進行匹配,如果哪裡有匹配的就會做一個記錄,也就是下面的這種形式
417718110:NT:1,528173057:admin.php:1,542593949:5.1:1,709591711:Windows:1,1070264077:NeBkxkA0rw:1,1070607007:HTTP:1,1220141225:action:1,1369927740:de 每個匹配的token特徵由三部分組成:
- dimension :標識這個特徵的index (specifies the index of the dimension),因為劃分後得到了很多很多的token,每一個token都是一個特徵(後面的reduction就是為了獲得具有代表性的token),為了標識這些特徵所以每一個特徵都有一個index 。
- feature: a textual representation of the feature
- value: the value at the dimension.
這裡筆者將詳細講解sallyProcessing.py函式:
#!/usr/bin/python
import sys
from optparse import OptionParser
usage = "usage: %prog in.sally out.fsally"
parser = OptionParser(usage)
(options, args) = parser.parse_args()
if len(args) != 2:
parser.print_help()
sys.exit()
sallyIn = file(sys.argv[1])
sallyOut = file(sys.argv[2], "w")
# skip first line
sallyIn.readline()
allNgrams = {}
count = 0
for l in sallyIn:
count += 1
if count % 1000 == 0:
print(count)
info = l.split(" ")
if info[0] == "":
curNgrams = []
else:
curNgrams = [ngramInfo.split(":")[1] for ngramInfo in info[0].split(",")]
allNgrams.update(allNgrams.fromkeys(curNgrams))
sallyOut.write("%s\n" % " ".join(curNgrams))
sallyOut.write("%s\n" % " ".join(allNgrams.keys()))
sallyOut.close()
sallyIn.close()
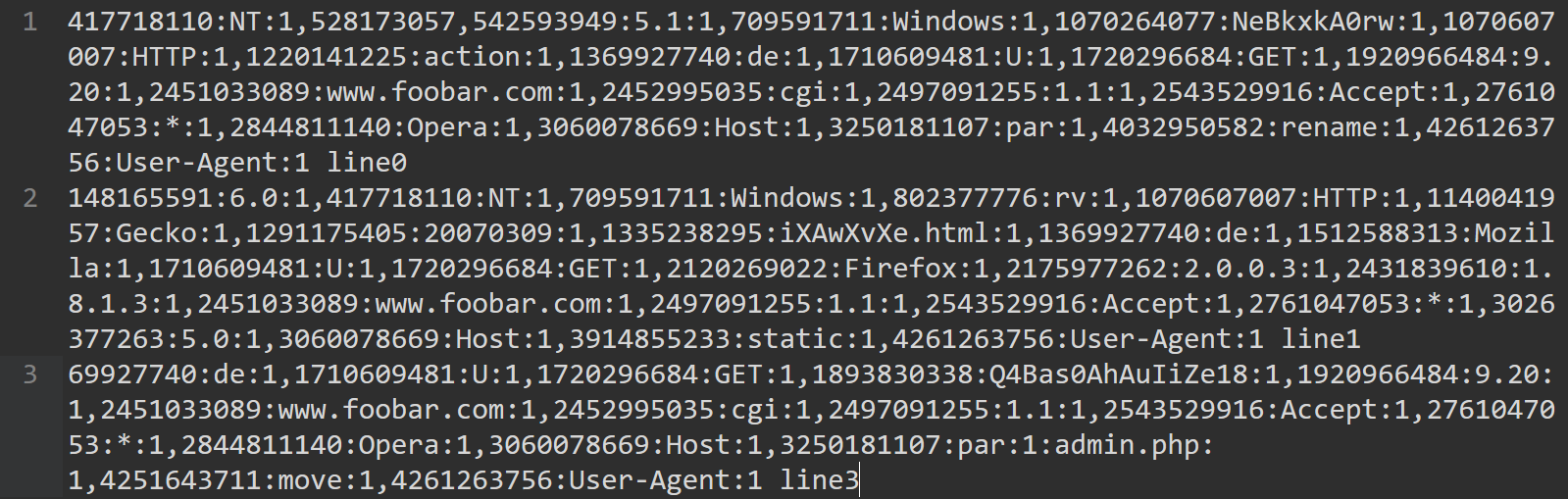
相信熟悉python的很快就能看明白,筆者是菜鳥所以自己摳了一個短的輸入檔案進行測試,便於理解。
輸入:
增加了print之後的顯示:
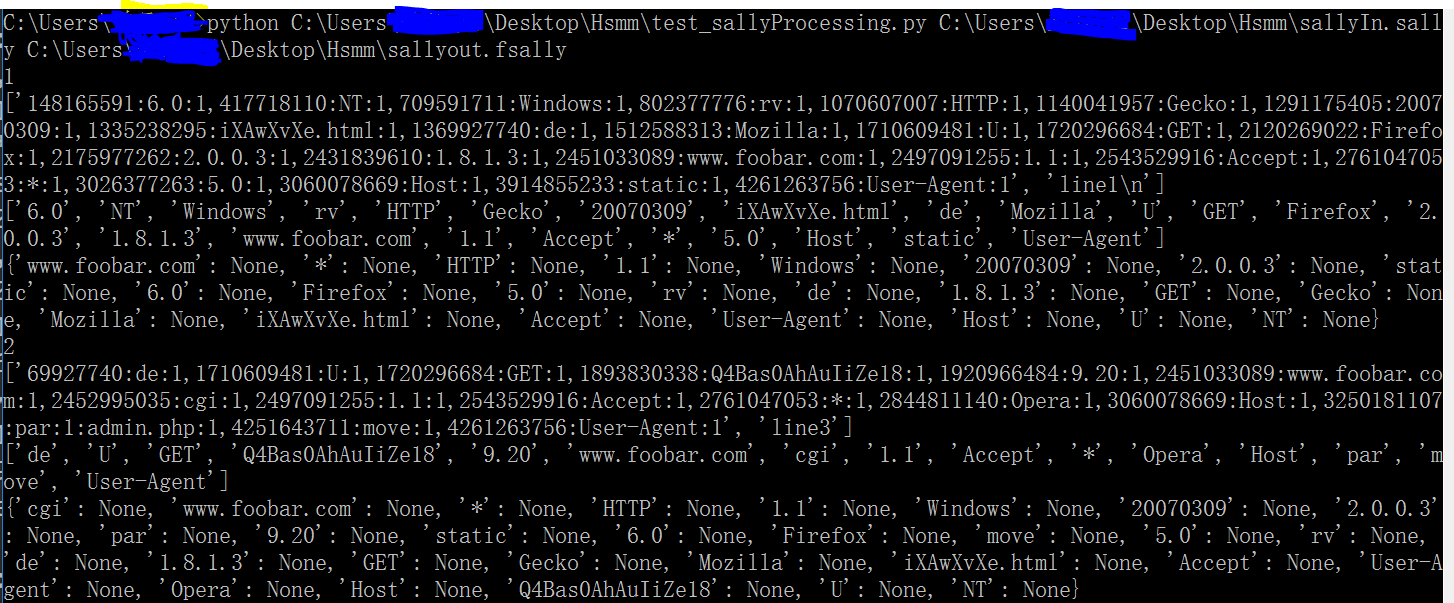
輸出:

實際上這裡的sallyProcessing.py主要作用就是把.sally檔案中格式變換一下,將“.sally”檔案中“148165591:6.0:1,417718110:NT:1,709591711:Windows:1”這種格式的內容中的中間值(這裡是6.0和NT以及Windows)讀出來存在.fsally中,其實也就是得到分好的gram的集合,也作為PRISMA的輸入。
這一部分主要是為了比較高效地完成token劃分過程,然後將劃分token的結果轉換成PRISMA比較好處理的輸入。
The PRISMA Data Set
對於上面得到的輸入,可以通過如下方法載入加以展示。
進入R環境,載入資料
R
library("PRISMA")
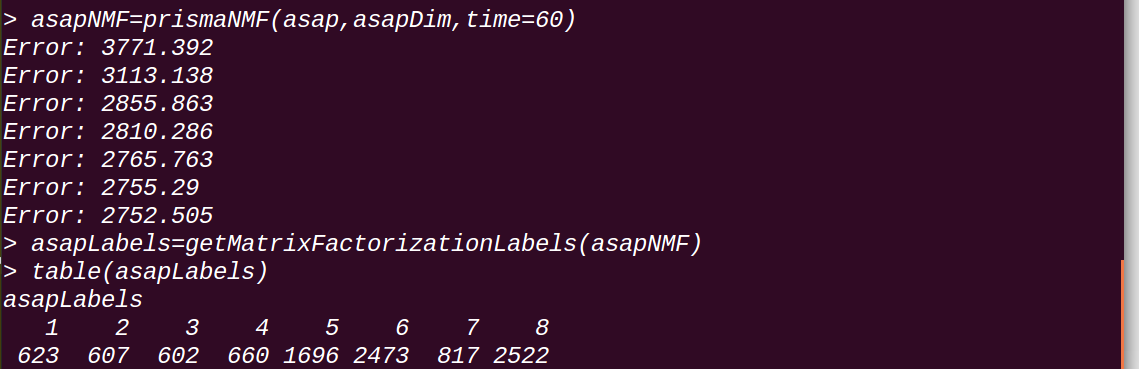
loadPrismaData("asap")
讀取asap資料集:
data(asap)
asap
可以看到由10000個樣本,然後有10034個特徵(這些特徵就是上面得到的token,雖然最初劃分的得到的tokens很多,但是由於會有重複的,通過sallyProcessing.py處理之後,將tokens都提取出來了,會得到很多相同的token,於是就會合並掉,最終這裡只有10034個tokens了也就是10034個特徵),通過處理變成了一個12*24的矩陣。
所謂的12*24是因為PRISMA會將一些tokens整合到一個集合中,用這一個集合來作為一個特徵,這個在另一篇文章中有提到對其的配置方法,具體是通過計算token之間的關聯絡數(correlation coefficient)將關聯絡數相近的合併為一組,如圖第二行就是將“admin.php par action”作為一個特徵,這裡有12個(或者組更合適)特徵;
asap$data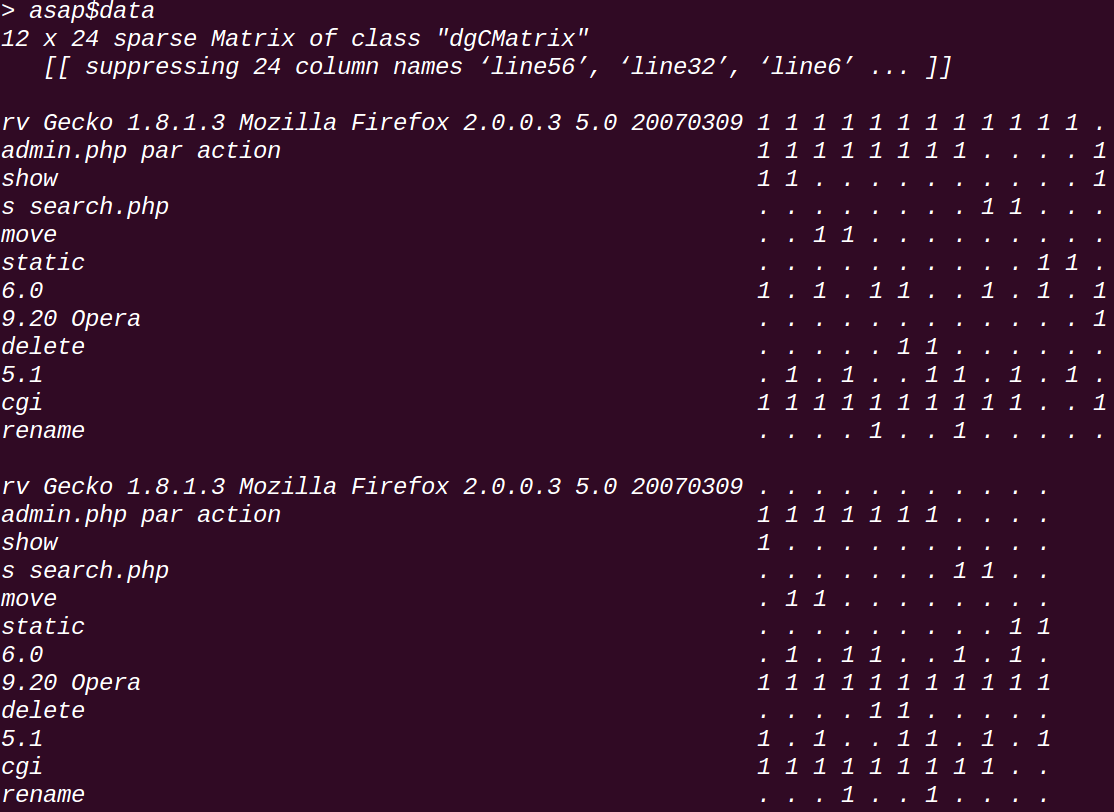
asap$group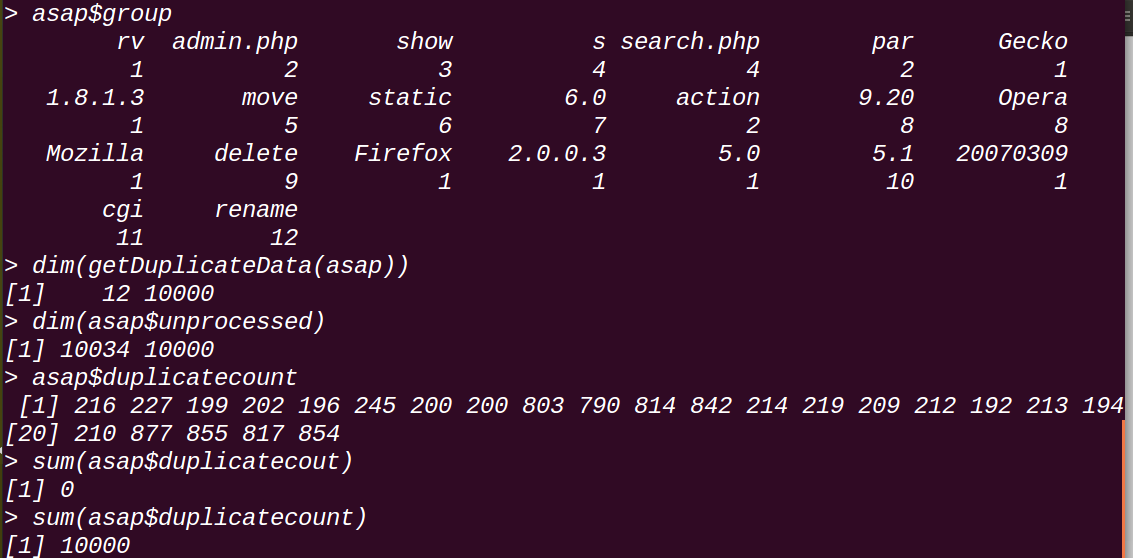
Dimensionnality Reduction
上面得到了12*24的矩陣是經過了降維(這裡可以參見ASAP的論文),具體實現將在下面詳細講解。
首先在提取報文結構的時候,由於資料集龐大,分析時候必須關注一些具有代表性的特徵,所以不能把初步劃分的10034個tokens都作為最終分析的特徵,需要進行降維,去除掉多餘的特徵(如時間戳、cookie等等,這些都是隨機出現,而且某一種取值基本都只會出現一次)。
論文中提到,會使用stastical test-driven dimension reduction,排除掉特徵集中的constant以及volatile特徵,詳細參見PRISMA的論文。
這裡的test去除了值出現頻繁很高以及很低的token,在實際報文序列中,這些可能對應著變值欄位和一個定值欄位,在找出具有代表性的特徵的時候,丟掉了這些,但是在後面的template推斷過程中又將其考慮進去了,這樣才能得到更準確的格式資訊。
擴充套件:這一步完成以後,報文資料就被轉換到了向量空間,並且經過了降維,篩選出了具有代表性的token特徵(詳細的可以參考ASAP論文中的講解),使用什麼方法來提取報文格式以及狀態機,個人覺得就可以“仁者見仁智者見智”了。
Clustering for Event Inference
出現在同一個特定通訊event中的報文,通常都會有相似的結構特徵(similar structural features),所以可以利用這種結構來提取event資訊。首先定義一種metric來衡量兩個報文之間的相似性,譬如歐氏距離(其中的
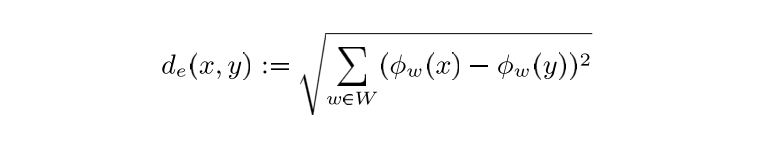
在PRISMA的論文中提到了兩種聚類方法:
- Part-based Clustring:
論文提到這種方法適用於Assembled of parts型別協議效果較好。先進行NMF,然後再按照NMF得到的座標計算報文之間的相似度來聚類。

非負矩陣分解實質就是通過將處理得到的矩陣A:features×N(data point),分解成兩個矩陣B:features×e,C:e×N,(e遠小於features的個數),得到的矩陣B可以解釋成一個新的基準向量,矩陣C表示在這個新的向量空間中每一個點的座標【也就是說B(B1,B2,...,Be)定義了新的基準向量,C(C1,C2,...,CN)則表示每一個點對應的每個基準向量的權值)】,C裡面的Ci就是每一個數據點的座標,這些座標就用來計算報文之間的相似度,進行聚類(這裡可以參考上面的流程圖來理解)。
而具體怎麼實現非負矩陣分解就不講了(因為我也講不清楚:-D囧:-D)。
- Position-based Clustering:
論文中提到這種方法適用於Monolithic communication,where tokens are weighted according to their absolute position in the message,因為某些協議體現出position-dependent 特徵,提出了一種weighted distance measure:

Inference of the State Machine
不論採用哪種聚類方法,都會將報文分成若干類,而每一類就代表了一個Event,正是需要依賴這些Event來進行狀態機推斷。論文中是通過Markov模型來進行推斷,筆者會在後面文章中詳細講述。
Learning Templates and ruls
大部分協議逆向工作都是先完成協議格式的提取,再利用得到的格式資訊進行狀態機推斷,而PRISMA則是先得到狀態機,再利用狀態機資訊來得到格式資訊Template,以及會話之間轉換的rules(為了完成後面的Protocol Simulation)。
Templates:
首先需要說明,Markov模型的一個狀態對應狀態機中的一個狀態,而每一個狀態裡面可能會有多個會話,一個會話中也會有多種格式的報文也就是會有多個Template。Learning Templates 的具體步驟如下:
- 根據之前的劃分方法將原始報文序列tokenize;
- 根據Markov模型將原始報文劃分成不同會話的報文;
對於Markov模型中的每一個狀態
- 將相同token數目的報文放到一個group中
- 如果一個group中的報文在某一個相同的位置,有一個相同的token,那麼就認為是最終Template中的一個定值欄位,否則就認為是一個變值欄位

最終會得到Markov模型中每一個狀態的Template,這個Template代表了這個狀態下通用的報文格式。需要注意的是,每一個狀態可能會對應很多個template,因為這裡是按照token數量進行的分組,每一組都會得到一個Template。
實際上這裡做了很大的簡化,會對得到的結果的準確率造成影響。
Rules:
所謂的Rules其實就是結合Markov模型,會話資訊,原始報文,提取出Template中每一個欄位的取值,這個就不用贅述了。