
匈牙利演算法(簡單易懂)
matrix67(點選開啟連結):
說穿了,就是你從二分圖中找出一條路徑來,讓路徑的起點和終點都是還沒有匹配過的點,並且路徑經過的連線是一條沒被匹配、一條已經匹配過,再下一條又沒匹配這樣交替地出現。找到這樣的路徑後,顯然路徑裡沒被匹配的連線比已經匹配了的連線多一條,於是修改匹配圖,把路徑裡所有匹配過的連線去掉匹配關係,把沒有匹配的連線變成匹配的,這樣匹配數就比原來多1個。不斷執行上述操作,直到找不到這樣的路徑為止。
【書本上的演算法往往講得非常複雜,我和我的朋友計劃用一些簡單通俗的例子來描述演算法的流程】
匈牙利演算法是由匈牙利數學家Edmonds於1965年提出,因而得名。匈牙利演算法是基於Hall定理中充分性證明的思想,它是部圖匹配最常見的演算法,該演算法的核心就是尋找增廣路徑,它是一種用增廣路徑求二分圖最大匹配的演算法。
-------等等,看得頭大?那麼請看下面的版本:
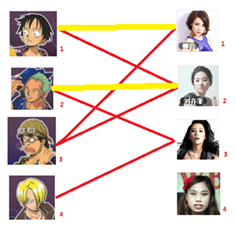
通過數代人的努力,你終於趕上了剩男剩女的大潮,假設你是一位光榮的新世紀媒人,在你的手上有N個剩男,M個剩女,每個人都可能對多名異性有好感( -_-||暫時不考慮特殊的性取向),如果一對男女互有好感,那麼你就可以把這一對撮合在一起,現在讓我們無視掉所有的單相思(好憂傷的感覺
-_-||暫時不考慮特殊的性取向),如果一對男女互有好感,那麼你就可以把這一對撮合在一起,現在讓我們無視掉所有的單相思(好憂傷的感覺 ),你擁有的大概就是下面這樣一張關係圖,每一條連線都表示互有好感。
),你擁有的大概就是下面這樣一張關係圖,每一條連線都表示互有好感。
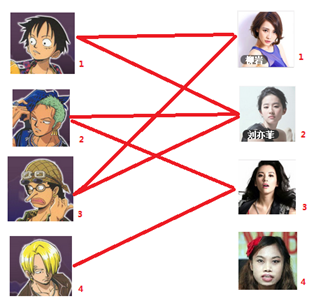
本著救人一命,勝造七級浮屠的原則,你想要儘可能地撮合更多的情侶,匈牙利演算法的工作模式會教你這樣做:
===============================================================================
一: 先試著給1號男生找妹子,發現第一個和他相連的1號女生還名花無主,got it,連上一條藍線
===============================================================================
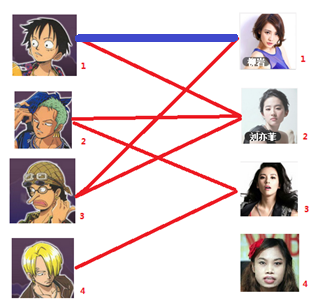
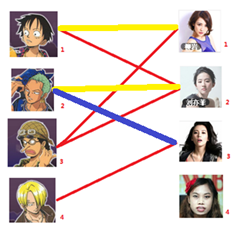
二:接著給2號男生找妹子,發現第一個和他相連的2號女生名花無主,got it
===============================================================================
三:接下來是3號男生,很遺憾1號女生已經有主了,怎麼辦呢?
我們試著給之前1號女生匹配的男生(也就是1號男生)另外分配一個妹子。
(黃色表示這條邊被臨時拆掉)
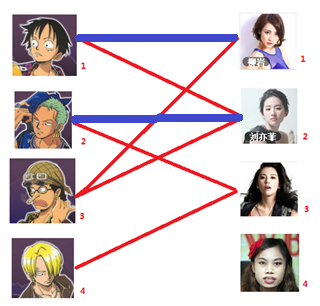
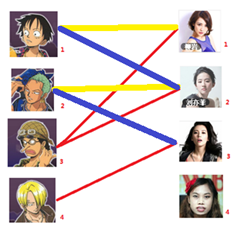
與1號男生相連的第二個女生是2號女生,但是2號女生也有主了,怎麼辦呢?我們再試著給2號女生的原配( )重新找個妹子(注意這個步驟和上面是一樣的,這是一個遞迴的過程)
)重新找個妹子(注意這個步驟和上面是一樣的,這是一個遞迴的過程)
此時發現2號男生還能找到3號女生,那麼之前的問題迎刃而解了,回溯回去
2號男生可以找3號妹子~~~ 1號男生可以找2號妹子了~~~ 3號男生可以找1號妹子
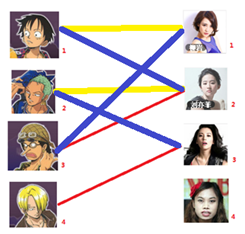
所以第三步最後的結果就是:
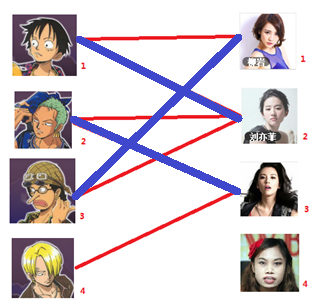
===============================================================================
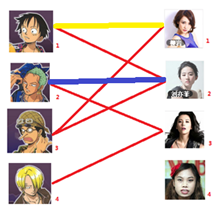
四: 接下來是4號男生,很遺憾,按照第三步的節奏我們沒法給4號男生騰出來一個妹子,我們實在是無能為力了……香吉士同學走好。
===============================================================================
這就是匈牙利演算法的流程,其中找妹子是個遞迴的過程,最最關鍵的字就是“騰”字其原則大概是:有機會上,沒機會創造機會也要上
【code】
- bool find(int x){
- int i,j;
- for (j=1;j<=m;j++){ //掃描每個妹子
- if (line[x][j]==true && used[j]==false)
- //如果有曖昧並且還沒有標記過(這裡標記的意思是這次查詢曾試圖改變過該妹子的歸屬問題,但是沒有成功,所以就不用瞎費工夫了)
- {
- used[j]=1;
- if (girl[j]==0 || find(girl[j])) {
- //名花無主或者能騰出個位置來,這裡使用遞迴
- girl[j]=x;
- returntrue;
- }
- }
- }
- returnfalse;
- }
在主程式我們這樣做:每一步相當於我們上面描述的一二三四中的一步
- for (i=1;i<=n;i++)
- {
- memset(used,0,sizeof(used)); //這個在每一步中清空
- if find(i) all+=1;
- }