
KMP演算法(淺顯易懂)
KMP演算法求解什麼型別問題
字串匹配。給你兩個字串,尋找其中一個字串是否包含另一個字串,如果包含,返回包含的起始位置。
講道理
大串A(長度n) 小串B(長度m)
一般匹配字串,一個一個比,當前字元對了則比對下一個,不對了再從B的頭開始比,移動一個位置;這樣的時間複雜度是O(n*m)
KMP可以實現複雜度為O(m+n)
改進的點就在於通過當發生不匹配時,之前匹配完成的部分的資訊的利用:B串能往前走不止是1;
概念
最大相同前後綴
abcdab—–ab
ababa——-aba
構建一個與B對應的next陣列,記錄在當前這個位置字元的前邊的字元構成的字串的最大相同前後綴的值;
上個圖,網上找的:
說白了就是構建一個這個:
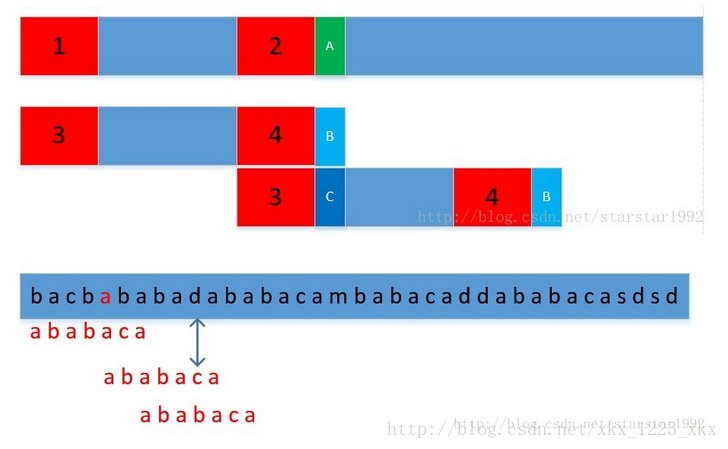
當AB不匹配,則直接讓3對過來。
理解這個圖,比看懂演算法更重要;
public static int next(int[] rootInt,int rootInt_position){
int[] next = new int[rootInt.length];
int position,key = 0;
for (position = 1;position<rootInt_position;position++ ){
if (key>0&&rootInt[position]!=rootInt[key]){
key=next[key-1 next表中用什麼值無所謂,因為你後期要用的時候可以稍加處理;
只要能將目標距離得到即可;
前期陷進了每次匹配都計算一個next的誤區,後發現前期對B先進行處理(即next的計算)即可。
相關推薦
KMP演算法(淺顯易懂)
KMP演算法求解什麼型別問題 字串匹配。給你兩個字串,尋找其中一個字串是否包含另一個字串,如果包含,返回包含的起始位置。 講道理 大串A(長度n) 小串B(長度m) 一般匹配字串,一個一個比,
對於spring中ioc的理解(淺顯易懂)
目錄 ioc是什麼? 首先ioc是Inversion of Control的縮寫 ,翻譯成中文就是:控制反轉的意思。接下來就把這個詞拆開來解釋 如何理解“控制”? 之前我們通過 "類名 物件名 = new 類名( )"的方式進行物件的建立,也就是說
匈牙利演算法(簡單易懂)
matrix67(點選開啟連結): 說穿了,就是你從二分圖中找出一條路徑來,讓路徑的起點和終點都是還沒有匹配過的點,並且路徑經過的連線是一條沒被匹配、一條已經匹配過,再下一條又沒匹配這樣交替地出現。找到這樣的路徑後,顯然路徑裡沒被匹配的連線比已經匹配了的連線多一條,於是修改
Spring中bean生命週期(淺顯易懂)
1、網上下的圖,以供參考 2、/** * 建立一個測試類的UserService * @author lion * */ public class UserService { private String username;//使用者名稱 pri
動態規劃 | 帶有萬用字元的字串匹配(淺顯易懂)
帶有萬用字元的字串匹配 一、Leetcode | 44 Wildcard Matching(只有一個字串包含萬用字元) 題目很簡單,就是說兩個字串,一個含有萬用字元,去匹配另一個字串;輸出兩個字串是否一致。 注意:’?’表示匹配任意一個字元,’
ORB特徵原理(淺顯易懂)
緒論 假如我有2張美女圖片,我想確認這2張圖片中美女是否是同一個人。這太簡單了,以我專研島國動作片錘鍊出來的火眼金睛只需輕輕掃過2張圖片就可以得出結論。但是,如果我想讓計算機來完成這個功能就困難重重了:再性感的美女在計算機眼中也只是0-1組成的資料而已。一種可行的方法是找出2張圖片中的特徵點,描述這些特
簡單易懂的KMP,NEXT陣列,BF演算法(例項講解)!!!
去了360面試,問了一個關於KMP的知識點,呀,完全忘了啊,太不應該了,然後就打算看看這個KMP,,, 看了好多關於KMP演算法的書籍和資料,總感覺沒有說的很清楚,為什麼會產生next陣列,為什麼給出了那麼簡短的程式,沒有一個過程,而有的帖子雖然next及其字串匹配說的很清
KMP演算法(字串)
純模板題:HDU1686 #include<cstdio> #include<cstdlib> #include<cstring> #define INF 1000005 int next[INF]; char a[INF],b[INF]; void
KMP 演算法(1):如何理解 KMP
http://www.61mon.com/index.php/archives/183/ 系列文章目錄 KMP 演算法(1):如何理解 KMPKMP 演算法(2):其細微之處 一:背景TOC 給定一個主字串(以 S 代替)和模式串(以 P 代替),要
有關串的模式匹配問題中的kmp演算法(俗稱 看毛片演算法)
========前言====== 最近準備考研,於是重新拾起資料結構這本書(嚴老師的) 對於之前的看毛片演算法想用自己的方式重新總結一下 ========沒有這方面基礎的先看 這個網址 (該網址為百度百科 本人只分享跟連結 若有其他影響本人概不負責)
Adaboost演算法原理分析和例項+程式碼(簡明易懂)
【尊重原創,轉載請註明出處】 http://blog.csdn.net/guyuealian/article/details/70995333 本人最初瞭解AdaBoost演算法著實是花了幾天時間,才明白他的基本原理。也許是自己能力有限吧,很多資料也是看得懵懵懂
KMP演算法(next演算法)
KMP演算法之前需要說一點串的問題: 串: 字串:ASCII碼為基本資料形成的一堆線性結構。 串是一個線性結構;它的儲存形式: typedef struct STRING { CHARACTER *head; int length; }; 樸素的串匹配
動態代理 靜態代理 代理模式詳解(講的很好 淺顯易懂)
們在Java程式碼中定義的。 通常情況下, 靜態代理中的代理類和委託類會實現同一介面或是派生自相同的父類。 一、概述 1. 什麼是代理 我們大家都知道微商代理,簡單地說就是代替廠家賣商品,廠家“委託”代理為其銷售商品。關於微商代理,首先我們從他們那裡買東
KMP演算法(字串匹配演算法)
KMP演算法主要是要計算匹配字元的字首表(prefix table), 舉例:如下面字串的字首表就是陰影框框中的部分。利用字首表來進行匹配 例子:(匹配字元)p=ABABCABAA, (待匹配字元)t=ABABABABCABAAB 具體主要就是求字首表,然後將
KMP演算法(改進的字串匹配演算法)
/** *KMP演算法 */ /* 目標串:ababcabcbababcabacaba 模式串:ababcabac next:001201230 首先獲取模式串的next陣列,next陣列實際是計算出模式串中重複出現的字元數量
kmp演算法(很短很清晰)
#include <iostream> #include <cstring> #include <cstdio> using namespace std; int main() { char t[10050],s[100000
KMP之一:從頭到尾徹底理解KMP演算法(2014年8月1日版)
作者:July 時間:最初寫於2011年12月,2014年7月21日晚10點 全部刪除重寫成此文。 1. 引言 本KMP原文最初寫於2年多前的2011年12月,因當時初次接觸KMP,思路混亂導致寫也寫得非常混亂,如此,留言也是“罵聲”一片。所以一直想找機會重新寫下KMP,但苦於一直以來對KMP的理
UML類圖總結(淺顯易懂實用)
UML類圖的作用是描述程式中類的資訊及各個類之間的關係。所有的面向物件(Object Oriented)語言都離不開類的概念,理解了程式中類的設計也就理解了程式的一半。但類的具體描述方式在各個類中都不一樣,UML類圖的提出是為了能夠脫離語言的限制,抽象地描述各個類的資訊及各個
KMP演算法與樸素模式匹配演算法(C語言)
在上一篇部落格中介紹了KMP演算法和樸素模式匹配演算法的區別,本文主要針對這兩種演算法的C語言實現進行講解。 #include<stdio.h> #define OK 0 #define ERROR -1 #define FAILED 1 in
【資料結構與演算法】模式匹配——從BF演算法到KMP演算法(附完整原始碼)
模式匹配子串的定位操作通常稱為串的模式匹配。模式匹配的應用很常見,比如在文書處理軟體中經常用到的查詢功能。我們用如下函式來表示對字串位置的定位:int index(const string &T