
例說STM32F7快取記憶體——Cache一致性問題(一)
為了說清楚這個問題,我特意翻出了壓箱底的那本杜春雷老師的《ARM體系結構與程式設計》,內容雖然是舊了點,但經典畢竟是經典,每次看都會有新的收穫。
本來想把標題定為“xxx,看這篇就夠了”,但因為功力不夠,怕是誤人子弟,擔心最終只能成為標題黨,畢竟這個話題涉及到計算機架構和儲存系統。所以還是把標題改成了“例說STM32F7快取記憶體——Cache一致性問題”。那麼,就從應用的角度出發好了,從標題大概也可以看出,這篇文章的內容編排就是,先介紹快取記憶體(俗稱 Cache)的概念,再以具體的微控制器(STM32F769)為例進行探討,最後引入一個例子進行分析,讓大家深刻理解 Cache 一致性問題及其解決辦法。
好了,廢話不多說,開始吧!
1. Cache的基本概念和工作原理
1.1 為什麼需要Cache
大概十年前,常用的微控制器的主頻一般為幾十 MHz,時至今日,上百 MHz 主頻的 MCU 已經很常見了。比如,採用 ST 最新40nm工藝的 STM32H7 已經可以跑到 400 MHz 了,而一旦 ARM Cortex M7 發展到 28nm 技術,頻率將達到 800 MHz。(想想就覺得好可怕,裝置越來越智慧了,好擔心以後找不到敲程式碼的活了 >_<)
本文所使用的是基於 Cortex-M7 的 STM32F769I-DISCO 板,其主頻高達 216 MHz。但仔細想想,雖然微控制器的頻率大幅提高了,可是一般作為主儲存器使用的動態儲存器(DRAM),其儲存週期僅為幾十 ns。那麼,如果指令和資料都存放在主儲存中,主儲存器的速度將會嚴重製約整個系統的效能。因此,高效能的微控制器會在主儲存器和 CPU 之間增加高速緩衝儲存器(Cache),目的是提高對儲存器的平均訪問速度,從而提高儲存系統的效能。
通過引入 cache,儲存系統的效能得到了很大的提高,但同時也帶來了一些問題,比如,由於資料將存在於系統中不同的物理位置,可能造成資料的不一致性。
1.2 基本概念
時間區域性性 和 空間區域性性
高速緩衝儲存器是全部用硬體來實現的,因此,它不僅對應用程式設計師是透明的,而且對系統程式設計師也是透明的。Cache 與主儲存器之間以塊(cache line)為單位進行資料交換。當 CPU 讀取資料或者指令時,它同時將讀取到的資料或者指令儲存到一個 cache 塊中。這樣當 CPU 第2次需要讀取相同的資料時,它可以從相應的 cache 塊中得到相應的資料。因為 cache 的速度遠遠大於主儲存器的速度,系統的整體效能就得到很大的提高。實際上,在程式中通常相鄰的一段時間內 CPU 訪問相同資料的概率是很大的,這種規律稱為時間區域性性
不同系統中,cache 的塊大小也是不同的。通常 cache 的塊大小為幾個字。這樣當 CPU 從主儲存器中讀取一個字的資料時,它將會把主儲存器中和 cache 塊同樣大小的資料讀取到 cache 的一個塊中。比如,如果 cache 的塊大小為4個字,當CPU從主儲存器中讀取地址為 n 的字資料時,它同時將地址為 n、n+1、n+2、n+3 的4個字的資料讀取到 cache 中的一個塊中。這樣,當 CPU 需要讀取地址為 n、n+1、n+2 或者 n+3 的資料時,它可以從 cache 中得到該資料,系統的效能將得到很大的提高。實際上,在程式中,CPU 訪問相鄰的儲存空間的資料的概率是很大的,這種規律稱為空間區域性性。
時間區域性性和空間區域性性保證了系統採用 cache 後,通常效能都能得到很大的提高,所以想要充分發揮 Cache 的作用,就要保證有比較高的命中率(Cache Hit)。
I-Cache 和 D-Cache
如果一個儲存系統中指令預取時使用的 cache 和資料讀寫時使用的 cache 是各自獨立的,這是稱系統使用了獨立的 cache,反之則為統一的 cache。其中,用於指令預取的 cache 稱為指令 cache(I-Cache),用於資料讀寫的 cache 稱為資料 cache(D-Cache)。使用獨立的 I-Cache 和 D-Cache,可以在同一個時鐘週期中讀取指令和資料,而不需要雙埠的 cache。但這時候,要注意保證指令和資料的一致性。
Cortex-M7 架構為我們配備了獨立的高速指令快取(I-Cache)和高速資料快取(D-Cache)。
Cache line
Cache 與主儲存器之間以塊(cache line)為單位進行資料交換,Cache 在邏輯上被劃分為若干 cache line,對應著一組儲存器的位置,因此,Cache 與主儲存器交換資料的最小粒度就是 cache line。
Cache Hit 和 Cache Miss
Cache命中(Cache Hit)——要訪問的資料/指令已經存在快取裡;
Cache缺失(Cache Miss)——要訪問的資料/指令不在快取裡;
如果發生 cache miss 並且 cache 未滿,則在 cache 中發現一個位置,並把新的快取資料存到這個位置。如果 cache 已滿,則要通過 cache 替換策略進行 cache line 的替換,騰出空閒的位置後,再將新的快取資料存到這個位置。
Read-allocate 和 Write-allocate
根據不同的分配方式,可以把 cache 分為讀操作分配(Read-allocate)cache 和寫操作分配(Write-allocate)cache。
對於讀操作分配 cache,當進行資料寫操作時,如果 cache 未命中,只是簡單地將資料寫入主存中。只有在資料讀取時,才進行 cache 內容預取。
對於寫操作分配 cache,當進行資料寫操作時,如果 cache 未命中,cache 系統將會進行 cache 內容預取,從主存中將相應的塊讀取到 cache 中相應的位置,並執行寫操作,把資料寫入到 cache 中。對於寫通型別的 cache,資料將會同時被寫入到主存中,對於寫回型別的 cache 資料將在合適的時候寫回到主存中。
由於寫操作分配 cache 增加了 cache 內容預取的次數,它增加了寫操作的開銷,但同時可能提高 cache 的命中率,因此這種技術對於系統的整體效能的影響與程式中讀操作和寫運算元量有關。
讀操作分配(Read-allocate)方式的簡寫為 RA,寫操作分配(Write-allocate)方式的簡寫是 WA。
Write-back 和 Write-through
按 cache 中內容寫回主存中的方式分類,可分為 Write-back 和 Write-through 兩種方式。
Write-back(翻譯為“寫回”或“回寫”)——寫資料時,只更新快取,然後將 cache line 標記為“dirty”,當這個快取行被新的快取行替換,或者手動 clean 的時候,再將資料寫到儲存器中。
Write-through(可能翻譯為“寫通”、“透寫”或“直寫”)——寫資料時同時更新快取和二級儲存,快取行不被標記為“dirty。這樣,當某一個 cache line 需要替換時,就不必將其中的資料寫到主儲存器中去了,新調入的塊可以立即把這一塊覆蓋掉。
回寫(Write-back)方式的簡寫為 WB,透寫(Write-through)方式的簡寫是 WT。
另外,Dirty 是標記那些需要寫回到儲存器中的快取資料。當一個“dirty”的快取行被新的快取行替代時,就需要從快取中移除一個快取行(cache line),為新的資料騰位置,這個過程稱為驅逐(Eviction)。
1.3 Cache的工作方式
Cache的工作原理
相信如果大家認真看了上面描述的基本概念後,大概也猜到 Cache 的工作流程,下面我們一起來理清一下吧。
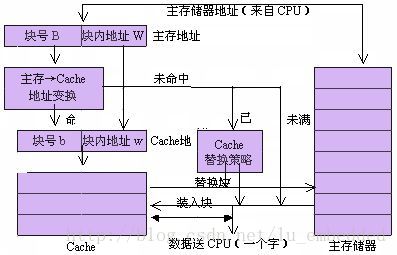
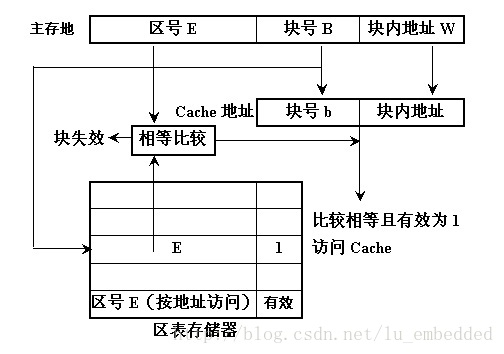
在 cache 儲存系統中,把 cache 和主儲存器都劃分成相同大小的塊。因此,主存地址可以由塊號 B 和塊內地址 W 兩部分組成。同樣,cache 的地址也可以由塊號 b 和塊內地址 w 兩部分組成。
當 CPU 要訪問 cache 時,CPU 送來主存地址,放到主存地址暫存器中。通過地址變換部件把主存地址中的塊號 B 變換成 cache 的塊號 b,並放到 cache 地址暫存器中。同時將主存地址中的塊內地址 W 直接作為 cache 的塊內地址 w 裝入到 cache 地址暫存器中。如果變換成功(即 Cache 命中),就用得到的 cache 地址去訪問 cache,從 cache 中取出資料送到 CPU 中。如果變換不成功,則產生 Cache 失效資訊,並且用主存地址訪問主儲存器。從主儲存器中讀出一個字送往 CPU,同時,把包含被訪問字在內的一整塊都從主儲存器讀出來,裝入到 cache 中去。這時,如果 cache 已經滿了,則要採用某種 cache 替換策略把不常用的塊先調出到主儲存器中相應的塊中,以便騰出空間來存放新調入的塊。由於程式具有區域性性特點,每次塊失效時都把一塊(由多個字組成)調入到 cache 中,能夠提高 cache 的命中率。
Cache 的對映方式
上面我們提高,cache 中的塊與主儲存器中的塊有一個地址轉換關係,也就是 cache 的對映方式。
一般來說有如下幾種對映方式:
(1)全關聯(full-associative)方式
【區塊劃分】
將主存與 Cache 劃分成若干個大小相等的塊(lines)。
【對映關係】
主存中任意一塊都可以對映到 Cache 中的任意一塊的位置上。
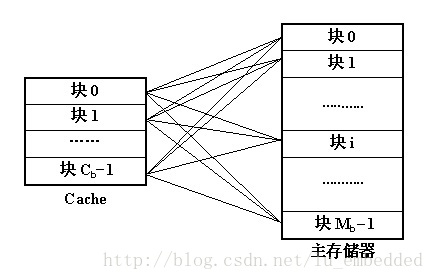
如果 Cache 的塊容量為 Cb,主存的塊容量為 Mb,則主存和 cache 之間的對映關係共有 Cb * Mb 種。如果採用目錄來存放這些對映關係,則目錄表的容量為 Cb。
【優缺點】
優點:訪問靈活,命中率高,Cache 儲存空間利用率高,衝突率低,只有 Cache 滿時才會出現在衝突。
缺點:地址變換比較複雜,每次都要與全部內容比較,速度相對慢,成本高,因而應用少。
【地址組成】
主存:塊號 + 塊內地址
快取:塊號 + 塊內地址
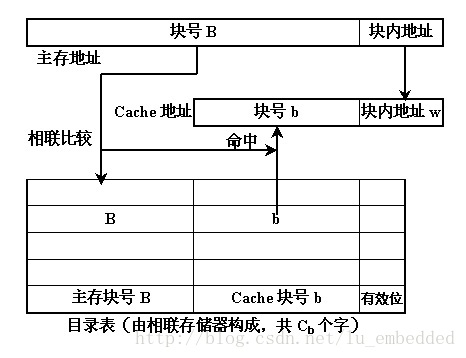
(2)直接對映(direct-mapping)方式
【區塊劃分】
將主存根據 Cache 的大小分成若干分割槽(主存的大小為 Cache 的整數倍),Cache 分成若干個相等的塊(lines),主存的每個分割槽也分成與 Cache 相等的塊。
【對映關係】
主存中的每一個分割槽由於大小與 Cache 完全相同,可以與整個 Cache 相像,每個分割槽中的每一塊正好與 Cache 的每一塊配對。也就是說,主存中一塊只能對映到 Cache 中的一個特定的塊,編號不一致的塊是不能相互對映的。
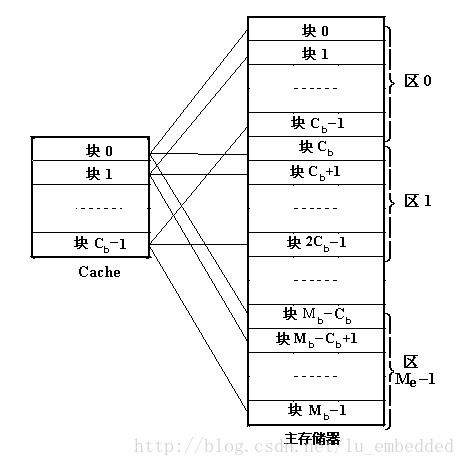
【優缺點】
優點:地址變換簡單,只需檢查區號是否相等即可,因而可以得到比較快的訪問速度,硬體裝置簡單。
缺點:替換操作頻繁,命中率比較低,每塊相互對應,不夠靈活。
【地址組成】
主存:區號 + 塊號 + 塊內地址
快取:塊號 + 塊內地址
(3)組相聯(set-associative)方式
【區塊劃分】
主存:主存根據 Cache 大小劃分成若干個區,每個區內劃分成若干個組(sets),每個組再劃分成若干個塊(lines)。
Cache:劃分成若干個組(sets),每個組劃分成若干個塊(lines)。
【對映關係】
從主存的組到 Cache 的組之間採用直接對映方式,當主存中的一組與 Cache 中的一組之間建立了直接對映關係之後,在兩個對應的組內部採用全關聯對映方式。
【優缺點】
融合了直接對映與全關聯對映兩種對映方式,結合了兩者的優點。具體實現容易,命中率與全關聯對映接近。
【地址組成】
主存:區號 + 組號 + 塊號 + 塊內地址
快取:組號 + 塊號 + 塊內地址
實際上,現代的 CPU 或者 MCU,絕大多數都是採用組相聯的 cache 對映方式。
1.4 儲存系統的一致性問題
當儲存系統中引入了 cache 時,同一地址單元的資料可能在系統中有多個副本,分別儲存在cache、寫緩衝區和主存中。如果系統採用了獨立的資料 cache 和指令 cache,同一地址單元的資料還可能在資料 cache 和指令 cache 中有不同的版本。位於不同物理位置的同一地址單元的資料可能會不同,使得資料讀操作可能得到的不是系統中“最新的”數值,這樣就帶來了儲存系統中資料的一致性問題。
在 ARM 儲存系統體系中,資料不一致的問題有一些是通過儲存系統自動保證的,另外一些資料不一致的問題則需要通過程式設計時遵守一定的規則來保證。
(1)地址對映關係變化造成的資料不一致
當系統中使用了 MMU 時,就建立了虛擬地址到實體地址的對映關係。如果查詢 cache 時進行的相聯比較使用的是虛擬地址,則當系統中虛擬地址到實體地址的對映關係發生變化時,可能造成 cache 中資料和主存中資料不一致的情況。
(2)指令 cache 的資料一致性問題
當系統中採用獨立的資料 cache 和指令 cache 時,一些操作序列可能造成指令不一致的情況。
(3)DMA 造成的資料不一致問題
DMA 操作直接訪問主存,而不會更新 cache 和寫緩衝區中相應的內容,這樣就可能造成資料的不一致。
如果 DMA 從主存中讀取的資料已經包含在 cache 中,而且 cache 中對應的資料已經被更新,這樣 DMA 讀到的將不是系統中最新的資料。同樣,DMA 寫操作直接更新主存中的資料,如果該資料已經包含在 cache 中,則 cache 中的資料將會比主存中對應的資料“老”,也將造成資料不一致。
為了避免這種資料不一致的情況的發生,根據系統的具體情況,執行下面的操作序列中的一種或幾種。
- 將 DMA 訪問的儲存區域設定成非緩衝的(uncachable 及 unbufferable);
- 將 DMA 訪問的儲存區域所涉及的資料 cache 中的塊設定為無效,或者清空資料 cache;
- 清空寫緩衝區(執行寫緩衝區中延遲的所有寫操作);
- 在 DMA 操作期間限制處理器訪問 DMA 所訪問的儲存區域。
(先寫到這裡吧,要去打球了。。。)