
一致性專題之cpu快取一致性(一)
只要涉及到快取的業務場景就一定會出現資料一致性問題。對於該問題,從微觀的角度來看cpu與記憶體之間建立了N級快取來提高效率,從巨集觀的角度來看分散式儲存使用資料副本機制來提高資料的安全性和訪問效率,不同的業務場景解決的技術手段不同,本文主要討論cpu的快取一致性問題。由於對cpu內部結構的詳細情況不熟,本文只會對核心的概念進行討論。
通過cpu-z工具就可以看到如下圖所示的內容:
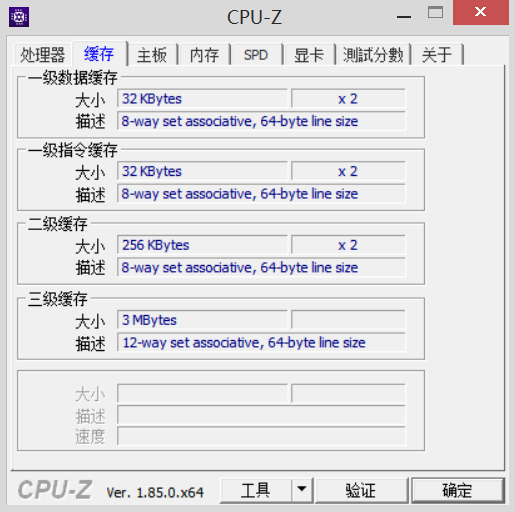
圖中顯示了cpu有3級快取,其中一級快取分為資料快取和指令快取其餘的只有資料快取(至於為什麼只有一級快取有指令快取本人暫不清楚),每級的快取大小也不同並且資料快取級別越高空間越小。快取行大小(即line-size)都是64byte,組關聯(即way-set associative)數量也不同。現圍繞這些內容進行討論。
1、cpu在訪問記憶體資料時需將資料先載入到快取中,然後從快取中讀取,快取行是記憶體與快取進行資料交換的基本單位,在本人電腦中為64位元組。
2、當cpu讀取資料時如何知道在哪個cache line中呢(注意這裡說的資料先當成1個位元組算,而不要當作short、int、long等型別,後面會說明這個問題),有以下方法:
(1)將記憶體按照cache line 大小即64byte為一個數據塊,對於4Gb的記憶體可以分為![]() 個數據塊,對於每個cache line而言會額外記錄當前訪問資料所屬資料塊的地址(暫時命名為tag欄位,長度為26bit)。遍歷所有的cache line,然後將資料地址/64並與tag欄位進行驗證是否相等,如果相等表示當前資料在該cache line 中,再對64取模就能讀取需訪問的資料。這種方法又叫全關聯對映很明顯在查詢時比較耗時,但是由於cache line只要有空閒就能填滿因此空間利用率較高;
個數據塊,對於每個cache line而言會額外記錄當前訪問資料所屬資料塊的地址(暫時命名為tag欄位,長度為26bit)。遍歷所有的cache line,然後將資料地址/64並與tag欄位進行驗證是否相等,如果相等表示當前資料在該cache line 中,再對64取模就能讀取需訪問的資料。這種方法又叫全關聯對映很明顯在查詢時比較耗時,但是由於cache line只要有空閒就能填滿因此空間利用率較高;
(2)將記憶體按照快取大小進行分塊,比如按照一級資料快取大小32kb進行劃分,4Gb的記憶體可以分為![]() 個塊,然後每個塊再按照cache line的大小64byte劃分成
個塊,然後每個塊再按照cache line的大小64byte劃分成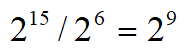 個快取行,與全關聯不同,該方法中每個記憶體資料所在的資料塊與快取中的快取行是一一對應的,不能像全關聯一樣,當有快取行衝突的時候只要發現某個快取行空閒就可以把記憶體中的資料載入過去,也就是說該方法即使有快取行空閒著也不能用。與全關聯一樣每個快取行需要額外的空間來記錄記憶體地址所屬的塊號和快取行的行號,該方法又叫直接對映;
個快取行,與全關聯不同,該方法中每個記憶體資料所在的資料塊與快取中的快取行是一一對應的,不能像全關聯一樣,當有快取行衝突的時候只要發現某個快取行空閒就可以把記憶體中的資料載入過去,也就是說該方法即使有快取行空閒著也不能用。與全關聯一樣每個快取行需要額外的空間來記錄記憶體地址所屬的塊號和快取行的行號,該方法又叫直接對映;
(3)將快取分成8份則每份4kb,將記憶體按照4kb進行分塊,4Gb的記憶體可以分為![]()
個快取行,該方法與直接對映法很像只是沒按照整個快取大小進行劃分,因此同樣會出現快取行衝突的問題,不同的是當發現第1份中的某個快取行被佔用時,會將資料載入到第2份中同一個快取行行號中,如果第2份也被佔用會依此類推到第3份中。這種方法又叫組關聯對映法實際上是前兩種方法的整合。該方法也就是目前cpu使用的最廣泛的方法。
3、由組關聯法可知,當第8份也被佔用的時候就需要從1-8份裡替換一個cache line了,替換的策略有隨機替換法、先進先出替換法、最近最少被使用(簡稱LRU,通過記錄每個cache line訪問的時間將長時間沒被訪問的替換掉,考慮的是時間區域性性)、最不經常使用(簡稱LFU,通過記錄每個cache line被訪問的次數,將次數最