
影象資料到網格資料-1——MarchingCubes演算法
概述
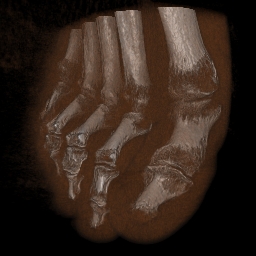
之前的博文已經完整的介紹了三維影象資料和三角形網格資料。在實際應用中,利用遙感硬體或者各種探測儀器,可以獲得表徵現實世界中物體的三維影象。比如利用CT機掃描人體得到人體斷層掃描影象,就是一個表徵人體內部組織器官形狀的一個三維影象。其中的感興趣的組織器官通過體素的顏色和背景加以區別。如下圖的人體足骨掃描影象。醫生通過觀察這樣的影象可以分析病人足骨的特徵,從而對症下藥。
這類應用在計算機領域叫做科學視覺化。由於本文主要不是討論視覺化這個大的命題,所以只是簡要的講述一下三維視覺化的兩大類實現方式,以及介紹一下用於面繪製方式的經典MarchingCubes演算法,通過自己的理解來簡單的實現這一演算法,如果想詳細的瞭解更多的內容,可以參考維基百科關於Scientific visualization的詞條。
三維視覺化的兩種方式
簡單點說,三維視覺化的目的就是讓人們從螢幕上看到三維影象中有什麼東西。眾所周知,二維影象的顯示是容易的,但是三維影象卻不一樣。過去由於技術的限制,得到了三維影象的資料,只能把它以二維影象的切片的形式展示給人看,這樣顯然不夠直觀。隨著電腦科學的發展,使用計算機圖形學技術為三維物體建模並實時渲染,實現場景漫遊變成顯示三維物體的主流方法,而過去切片顯示的方式則逐漸被邊緣化。
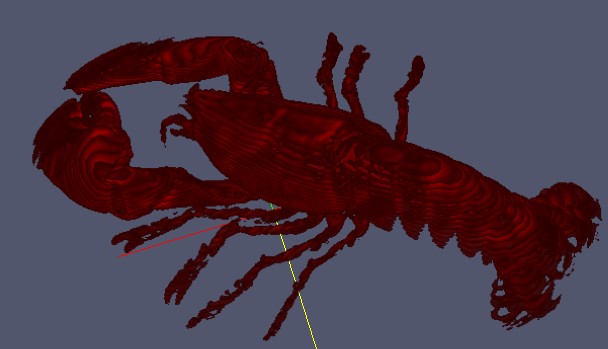
由計算機圖形學的知識我們可以知道,想顯示三維影象中的內容,可以對這個“內容”的表面建立一個三角形網格模型。一旦得到了這個三角網格,那麼渲染它就能夠在螢幕上看到想要的內容,同時可以調節視角進行全方位的觀察。所以第一類三維視覺化方法就是基於這種思想:首先建立網格模型,之後渲染網格。這種方式被稱為面繪製。下圖就是對一個體資料中的蝦建立表面模型之後的形態。

還有一種叫做體繪製的方式,是直接將三維影象的體素點通過一定的透明度疊加計算後直接對螢幕上的畫素點著色。這種方式的特點是能更加清楚的表現體資料內部細節,但是這種演算法一般對計算機的壓力也會比較大。下圖就是使用專門的體繪製軟體來顯示同一個資料中的蝦的形態。
本文主要針對第一種演算法,使用經典MarchingCubes演算法(簡稱MC演算法)的核心思想進行簡要介紹,注意本文實現MC演算法的方式與最初的WE Lorensen在1987年發表的論文裡的實現的方式有所區別。本文會在後面談及這一區別。
從影象到網格-MarchingCubes演算法
從影象到網格的演算法並非只有MC演算法,但是MC演算法相比其他的演算法,具有生成網格的質量好,同時具有很高的可並行性的優點。所以在眾多的行業應用中,MC演算法以及各種型別的基於其思想的改進演算法的使用頻率是非常高的。
首先基於MC的一系列演算法需要明確一個“體元(Cell)”的概念。體元是在三維影象中由相鄰的八個體素點組成的正方體方格,MarchingCubes演算法的Cube的語義也可以指這個體元。注意區別體元和體素,體元是8個體素構成的方格,而每個體素(除了邊界上的之外)都為8個體元所共享。
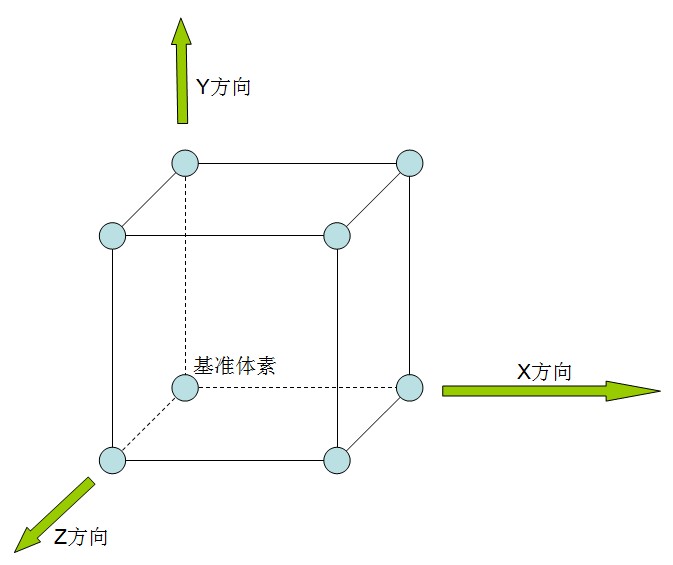
一個寬高層數分別為width、height、depth的三維影象,其體素的對應的x,y,z方向的索引範圍分別0~width-1、0~height-1、0~depth-1。容易想像出,這個體可以劃分出(width-1)*(height-1)*(depth-1)個體元。為了給每個體元定位,對於一個特定的體元,使用這個體元x、y、z方向上座標都是最小的那個體素(見上圖)作為基準體素,以它的x、y、z索引作為這個體元的x、y、z索引。這樣我們可以把這個Cube中的體素進行編號如下表所示:
| 體素位置 | 索引編號 | 體素代號 | 體素偏移(相對基準體素) | 位標記 |
| 上層,左側,靠前 | 0 | VULF | (0,1,1) | 1<<0=1 |
| 上層,左側,靠後 | 1 | VULB | (0,1,0) | 1<<1=2 |
| 下層,左側,靠後 | 2 | VLLB | (0,0,0) | 1<<2=4 |
| 下層,左側,靠前 | 3 | VLLF | (0,0,1) | 1<<3=8 |
| 上層,右側,靠前 | 4 | VURF | (1,1,1) | 1<<4=16 |
| 上層,右側,靠後 | 5 | VURB | (1,1,0) | 1<<5=32 |
| 下層,右側,靠後 | 6 | VLRB | (1,0,0) | 1<<6=64 |
| 下層,右側,靠前 | 7 | VLRF | (1,0,1) | 1<<7=128 |
示意圖如下所示:

這樣就可以為整個三維影象的體元和體素定位,同時為MC演算法的實現做準備。同時根據下文的MC演算法需要,用相同的思路為體元的邊也進行編號定位:
| 圖示 | 表說明 | ||||||||||||||||||||||||||
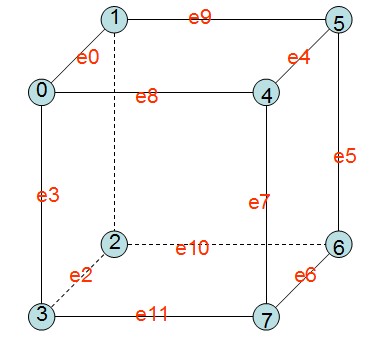 |
|
MC演算法的主要思路是以體元為單位來尋找三維影象中內容部分與背景部分的邊界,在體元抽取三角片來擬合這個邊界。為了簡單起見,我們將包含體資料內容的體素點稱為實點,而其外的背景體素點都稱作虛點。這樣一個三維影象就是由各種實點和虛點組成的點陣。從單個體元的角度出發,體元的8個體素點每個都可能是實點或虛點,那麼一個體元一共有2的8次方即256種可能的情況。MC演算法的核心思想就是利用這256種可以列舉的情況來進行體元內的等值三角面片抽取。
一個體元的體素分佈有256種,下文中使用“體素配置”和“體元配置”這兩個詞來指代這種分佈情況。由於計算機內的位0,1位元組位(bit)可以用來對應表示一個體素點是否是實點,這樣可以正好使用一個位元組中的8個位來分別對應一個體元中八個體素的分佈情況。上文中的表已經把每個體素點所對應的位元組位的位置表述清楚了,編號0~7的體素點的虛實情況分別對應一個位元組中從右往左第1~8個位。比如一個位元組二進位制為01110111,則可以用來表示0,1,2,4,5,6號體素為實點,3,7,8號體素為虛點的體素配置。
總的來說,一個三維影象中任何一個體元都一定有一個位元組對應著他的體素配置。這樣,我們就可以順序訪問一個三維影象中的所有體元,為每個體元找出其配置。對於一般的三維影象來說,一個體元有很大概率8個體素全是虛的,或者全是實的,我們把這些體元叫做虛體元和實體元;而第三種情況是這個演算法最為關心的,就是一個體元中既有實點也有虛點,這樣的體元我們稱其為邊界體元。
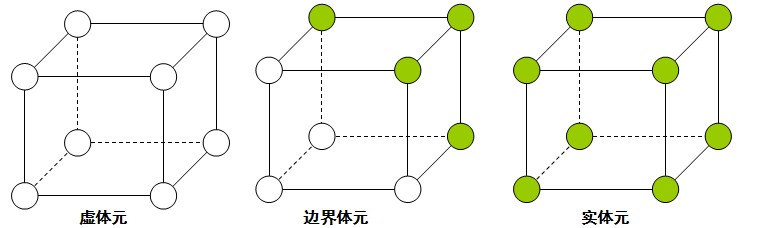
邊界體元之所以重要,是因為其中必然包含了所謂的“等值面”。所謂等值面是指空間中的一個曲面,在該曲面上函式F(x, y, z)的值等於某一給定值Ft,即等值面是由所有點S = {(x, y, z):F(x, y, z) = Ft}組成的一個曲面。這個等值面能夠表徵影象虛實部分的邊界。下圖使用二維圖片的等值線來說明:
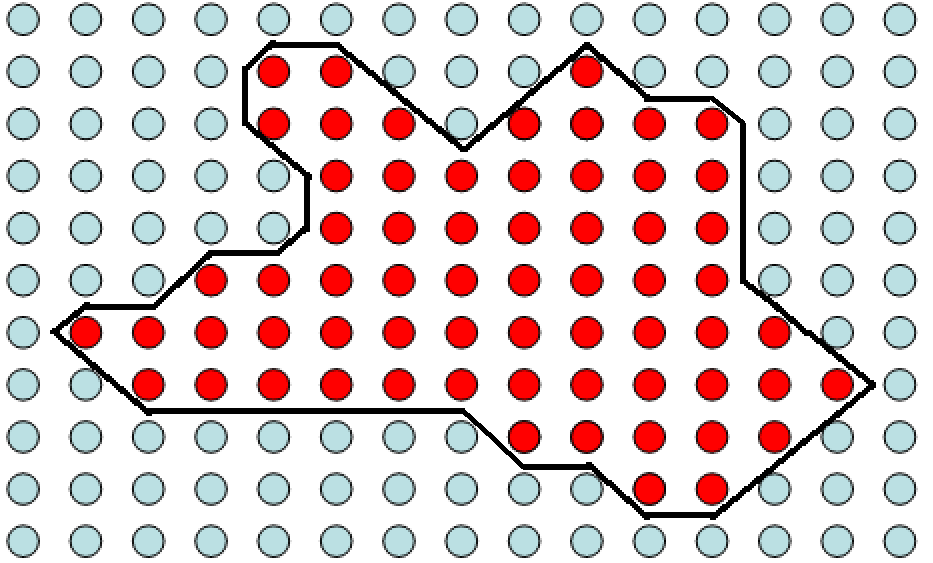
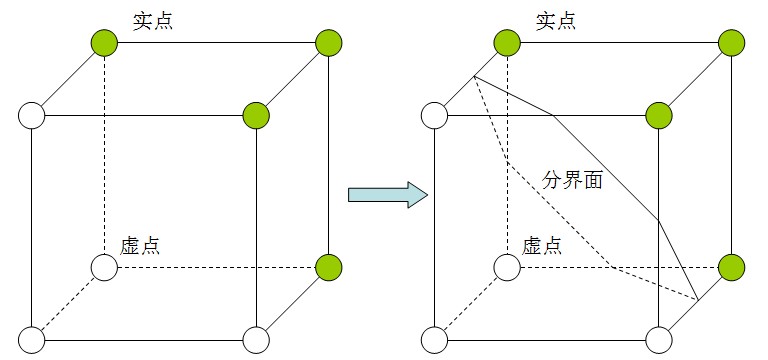
假設上圖中紅點表示畫素值為250的畫素,綠點表畫素值為0的點。結合等高線的思想,可以將250的區域想象成一片海拔為250的高原,而0的區域是海拔為0的平原。則等值線為128的線就必然處在每個紅點和綠點之間。相當於在一個由0過渡到250的坡上。實際上,值為1~249的等值線也都基本處在紅點和綠點之間的位置。那麼只要求出這些值中其中一個值的等值線,相當於就獲得了250畫素與0畫素在幾何意義上的邊界。那麼同樣的道理,在三維影象中想求出介於實點和虛點之間的表面,就要在他們的邊界,也就是邊界體元內做文章,設法求出虛實體素之間的等值面。MC演算法的另外一大思想就是使用三角片去擬合等值面。因為一個體元相對於影象是一個極小的區域性,所以穿過該體元等值面就可以近似由小三角形片來擬合。例如下面的體元配置,我們就可以認為等值面的一部分就是以這樣的方式穿過體元。
通過對256種體元(其中254種邊界體元)配置的分析可以得知,256種體元配置中生成的等值三角片形式都能夠被歸納為如下15種構型:
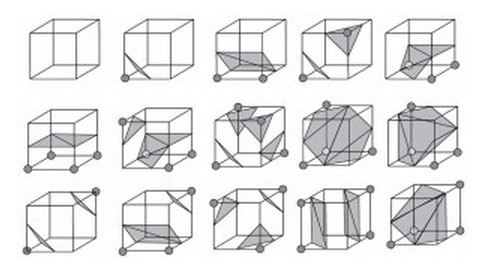
所有的256種配置都是這15種基本構型由旋轉,對稱變換等操作轉變而成。每一種體元配置中等值面都是由若干個三角形片構成。這樣針對這些有限的三角片分佈情況,可以製作一個表來表示所有256種配置的三角形情況,這個表一共有256行,每行能表示該體元配置下三角形的情況。從圖中可以看出,組成等值面的三角形的三個頂點一定是穿過體元的邊的,所以可以用三條邊的索引來表示一個三角形。如下圖的體元配置:
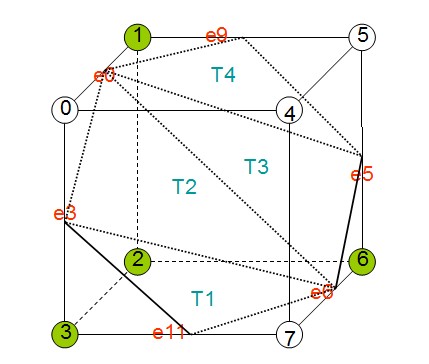
其實點為1,2,3,6,則其位元組形式來表示8個體素的虛實情況為01001110,轉為十進位制為78。其等值面由4個三角形T1、T2、T3、T4組成這四個三角形的頂點分別所在邊如下表所示:
| 三角形 | 頂點所在邊 |
| T1 | e3,e11,e6 |
| T2 | e0,e3,e6 |
| T3 | e0,e6,e5 |
| T4 | e0,e5,e9 |
那麼對於78這個體元配置,我們在表中就可有如下的記錄(注意該表完整應該有256行而這裡只寫了78這一行):
| 體元配置 | 二進位制形式 | 實點 | 三角形集合 |
| .... | .... | ... | ... |
| 78 | 01001110 | 1,2,3,6 | (3,11,6),(0,3,6),(0,6,5),(0,5,9) |
| .... | .... | ... | ... |
實際上,MC演算法的三角形表就是將這樣的方式簡化後轉化成二維陣列來組織的,下面的程式碼就是MC的三角形表,具體是來源於網路流傳,這張表應該不是計算機生成的,應該是在較早的時候有人手動統計的,他考察了所有256種情況的體元配置並畫出其中的三角形,然後寫在表裡,這個活兒工作量不小,之後網上很多版本的MC演算法都用到了和這個表一模一樣的表,只是可能用了不同的語言去表達。所以我們應該抱著對演算法先輩們的萬分感激之情去使用這張寶貴的三角形表。

public static int[,] TriTable = new int[256, 16] { {-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {0, 8, 3, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {0, 1, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {1, 8, 3, 9, 8, 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {1, 2, 10, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {0, 8, 3, 1, 2, 10, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {9, 2, 10, 0, 2, 9, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {2, 8, 3, 2, 10, 8, 10, 9, 8, -1, -1, -1, -1, -1, -1, -1}, {3, 11, 2, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {0, 11, 2, 8, 11, 0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {1, 9, 0, 2, 3, 11, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {1, 11, 2, 1, 9, 11, 9, 8, 11, -1, -1, -1, -1, -1, -1, -1}, {3, 10, 1, 11, 10, 3, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {0, 10, 1, 0, 8, 10, 8, 11, 10, -1, -1, -1, -1, -1, -1, -1}, {3, 9, 0, 3, 11, 9, 11, 10, 9, -1, -1, -1, -1, -1, -1, -1}, {9, 8, 10, 10, 8, 11, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {4, 7, 8, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {4, 3, 0, 7, 3, 4, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {0, 1, 9, 8, 4, 7, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1}, {4, 1, 9, 4, 7, 1, 7, 3, 1, -1, -1, -相關推薦
影象資料到網格資料-1——MarchingCubes演算法
概述 之前的博文已經完整的介紹了三維影象資料和三角形網格資料。在實際應用中,利用遙感硬體或者各種探測儀器,可以獲得表徵現實世界中物體的三維影象。比如利用CT機掃描人體得到人體斷層掃描影象,就是一個表徵人體內部組織器官形狀的一個三維影象。其中的感興趣的組織器官
神經網路演算法學習---影象資料預處理1
以卷積神經網路進行影象識別為例,常用的輸入影象預處理 Step1:Resize Step2:去均值。此處應注意,是對所有訓練樣本影象求均值,然後將每個樣本圖片減去該均值。測試圖片在進行預處理時,也減去該均值(注意不是減測試圖片的均值,而是減去所有訓練樣本影象的均值) 歸
大話資料結構讀書筆記艾提拉總結 查詢演算法 和排序演算法比較好 第1章資料結構緒論 1 第2章演算法 17 第3章線性表 41 第4章棧與佇列 87 第5章串 123 第6章樹 149 第7章圖 21
大話資料結構讀書筆記艾提拉總結 查詢演算法 和排序演算法比較好 第1章資料結構緒論 1 第2章演算法 17 第3章線性表 41 第4章棧與佇列 87 第5章串 123 第6章樹 149 第7章圖 211
資料探勘十大演算法之決策樹詳解(1)
在2006年12月召開的 IEEE 資料探勘國際會議上(ICDM, International Conference on Data Mining),與會的各位專家選出了當時的十大資料探勘演算法( top 10 data mining algorithms ),
Matlab影象處理常用語句(1)--批量讀取資料夾內影象
程式設計過程中發現有好多語句都比較常用,然而有時候會突然忘記怎麼用,所以還是要記下來,如有何不妥,還請多多指教。 批量讀取資料夾內影象 單個資料夾讀取 % 選擇資料夾 fo
2015年大二上-資料結構-圖-1-(1)圖基本演算法庫
圖的儲存結構主要包括鄰接矩陣和鄰接表,本演算法庫提供儲存結構的定義,以及用於構造圖儲存結構、不同結構的轉換及顯示的程式碼。演算法庫採用程式的多檔案組織形式,包括兩個檔案: 1.標頭檔案:Graph.h,包含定義圖資料結構的程式碼、巨集定義、要實現演算法的函式的宣
學習資料整理2018-1-21
tools .com tool gpo pos body ati ops html web安全資料https://github.com/CHYbeta/Web-Security-Learning Mimikatz 非官方指南和命令參考_Part1 http://www.an
大資料基礎(1)zookeeper原始碼解析
五 原始碼解析 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING;}zookeeper伺服器狀態:剛啟動LOOKING,follower是FOLLOWING,leader是LEADING,observer是
【資料結構】—— 1、不要小瞧陣列
2-1、 使用Java中的陣列 2-2 二次封裝屬於我們自己的陣列 2-3 向陣列中新增元素 2-4 陣列中查詢元素和修改元素 2-5 包含,搜尋和刪除 2-6 使用泛型 2-7 動態陣列 2-8 簡單的複雜度分析 2-9 均攤複雜度和防止複雜度的震盪
[資料集]遙感影象建築/道路資料集
在看論文時發現了這個資料集,記錄在這裡,希望可以幫助到廣大的胖友們 傳送門 : https://www.cs.toronto.edu/~vmnih/data/ 爬的了一下建築的資料(道路部分的資料,由於資料太大,無法上傳到百度雲上 ),我放在了網盤 連結:https://pan.ba
資料結構作業1-資料結構基本概念
1-1 抽象資料型別中基本操作的定義與具體實現有關。 (1分) [ ] T [x] F 1-2 若用連結串列來表示一個線性表,則表中元素的地址一定是連續的。 (1分) [ ] T [x] F 2-1 在決定選取何種儲存結構時,一般不考慮()。 (2分) [ ] A.
嚴蔚敏老師版《資料結構》筆記之演算法
1. 什麼是演算法? 是對特定問題求解的步驟 2. 演算法的5個重要特性: 有窮性、確定性(讀者閱讀時不會產生二義性)、可行性、輸入(至少0個)、輸出(至少1個) 3. 演算法設計的要求: 正確性(程式碼無誤、幾組輸入能夠得到滿足要求的結果、對
【資料倉庫】1.資料模型
0x00 前言 翻出來之前零零散散寫的資料倉庫的內容,重新修正整理成一個系列,此為第一篇《資料模型》。 資料倉庫包含的內容很多,比如系統架構、建模和方法論。對應到具體工作中的話,它可以包含下面的這些內容: 以Hadoop、Spark、Hive等元件為中心的資料架構體系
C#入門——C#語法(資料結構)1
C#語言是一種面向物件的語言。C#程式結構大體可由註釋、名稱空間、類、Main方法和語句構成的。 一.註釋 註釋是什麼:為對某行或某段程式碼的解釋說明或忽略程式碼。 註釋的作用:方便自己閱讀與維護或讓他人能夠更好地理解自己的程式。 註釋分兩種:行註釋與塊註釋 1.行註釋 static voi
深入淺出“跨檢視資料粒度計算”--1、理解資料的粒度
此文已由作者王文開授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 跨檢視資料粒度計算(Cross-Granularity Calculation)是網易有數推出的新功能,CGC的優點是您可以獨立於當前檢視用的維度來執行此計算。CGC計算表示式一共有三種,分別是:FIXED,INCL
資料結構——3.1樹與樹的表示
一、引言 層次結構舉例 家譜、城市(鄉鎮),檔案管理系統等 為什麼用層次結構呢? 分層次組織在管理上具有更高的效率 查詢 靜態查詢:對查詢的集合沒有插入和刪除操作,只有查詢 動態查詢:對查詢的集合除查詢外,還可能發生插入和刪除 二分查詢的啟示 例如11個元素的二
資料結構——4.1 二叉搜尋樹
一、二叉搜尋樹 一棵二叉樹,可以為空;如果不為空,滿足以下性質: 1)非空左子樹的所有鍵值小於其根結點的鍵值 2)非空右子樹的所有鍵值大於其根結點的鍵值 3)左右子樹都是二叉搜尋樹 二、二叉搜尋樹操作的特別函式 1、查詢 1)Find ① 查詢從根結點開始,如果樹
分散式系統之資料分片前言1
轉載:https://www.cnblogs.com/xybaby/p/7076731.html 目錄 寫在前面 帶著問題出發 資料分片 資料冗餘 其他 總結: 正文 很長一段時間,對分散式系統都比較感興趣,也
SAP Cloud for Customer客戶主資料的重複檢查-Levenshtein演算法
SAP C4C的客戶主資料建立時的重複檢查,基於底層HANA資料庫的模糊查詢功能,根據掃描資料庫中已有的資料檢測出當前正在建立的客戶主資料是否和資料庫中記錄有重複。 在系統裡開啟重複檢查的配置: 在此處配置主資料模型上每個欄位對重複性檢查結果共享的權值: 要理解權值的作用,就必須先理解C4C
解決使用GPU處理影象時提示資料不能是gpuArray的問題
【時間】2018.10.11 【題目】解決使用GPU處理影象時提示資料不能是gpuArray的問題 【問題描述】今天我在MATLAB中,用GPU進行影象處理,最後想用imwrite儲存下來,但出現了以下錯誤:錯誤使用 imwrite 需要的 DATA 應為以下型