
前端網頁入門之瞭解網頁中的元素鞏固版(三)
阿新 • • 發佈:2019-01-06
繼昨天學習在本地擷取網頁資訊之後,決心做個小練習鞏固一下自己,在練習的過程中不但回顧了一下昨天所學知識,並且發現一些小小的新知識點記錄下來~
萌新一枚,如有不對,大神們輕噴!!!
正文開始~
今日練習目標:沿襲昨天使用BeautifulSoup的套路,對這個網頁的圖片,標題,價格,評論數,星級進行獲取
難點發現:對於星星顆數的獲取(就是自動識別點亮了幾個星星)

因每顆星星都對應著一行程式碼,圖片中的五顆星星就對應了五行程式碼,
為了讓其通過一行程式碼就顯示,觀察網頁,多取幾顆星星的selector發現規律:
從父節點開始取,此處保留:nth-of-type(2)
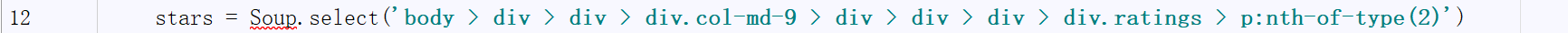
接下來就是今天疑惑的難點,對於星星數量的獲取
此處使用find all() 方法來解決

由此再加上昨天的學習內容
解析本地網頁,獲取圖片地址,價格,商品標題,評分量,評分星級這些內容
就so easy啦~
原始碼如下:
from bs4 import BeautifulSoup with open('D:/Study/Data Analysis/week1/1_2/1_2answer_of_homework/1_2_homework_required/index.html','r')as wb_data: Soup = BeautifulSoup(wb_data,'lxml') #print(Soup) # address = Soup.select('body > div:nth-of-type(3) > div > div.col-md-9 > div:nth-of-type(3) > div:nth-of-type(3) > div > img') address = Soup.select('body > div > div > div.col-md-9 > div > div > div > img') price = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4.pull-right') title = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4 > a') amount = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p.pull-right') stars = Soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p:nth-of-type(2)') # print(address,price,title,amount,star,sep='\n-------------\n') #現在是第三步篩選出標籤中需要的資訊,使用for迴圈取元素,並且對元素使用方法 # for address in address: # print(address.get('src')) # # for price in price: # print(price.get_text()) #優化後如下 #放入字典中方便查詢 #使用zip對所有元素進行字典迴圈並且對所有元素進行字典構造 for address,price,title,amount,stars in zip(address,price,title,amount,stars): data = { 'address':address.get('src'), 'price':price.get_text(), 'title':title.get_text(), 'amount':list(amount.stripped_strings), 'stars': len(stars.find_all("span", class_='glyphicon glyphicon-star')) } print(data)
效果圖如下(可以看到最後的星星是自動識別出來有幾顆了)

做完本地網頁的元素的鞏固練習之後,
下一篇是一定要開始在真實網頁中爬爬資料闖一闖了!