
避免過擬合的手段:L1&L2 regularization/Data Augmentation/Dropout/Early Stoping
面試機器學習或者深度學習的崗位有很大機率會問到這個問題,現在來總結一下如何避免過擬合問題:
1、L1&L2 regularization
1.1 L1 regularization
正則化項:
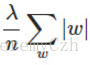
原始函式加上一個正則化項:
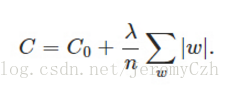
計算導數:
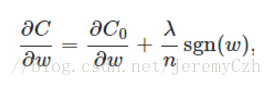
更新權重w:

對L1正則化的直觀理解是當w為正時,更新後的w變小;當w為負時,更新後的w變大,使得w能夠接近0,相當於對w懲罰,降低w對結果的影響。當w=0的時候,規定sgn(0)=0。
1.2 L2 regularization
正則化項:
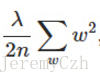
原函式加上正則化項:
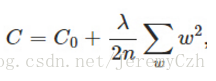
計算導數:
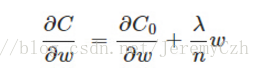
更新權重w:

非常直觀,由於η、λ、n均大於等於0,
L1與L2正則化都是以衰減權重w,以降低網路複雜程度,使得網路的擬合能力下降,達到防止過擬合。
1.3 L1與L2區別
L1優點是能夠獲得稀疏模型,對於large-scale的問題來說這一點很重要,因為可以減少儲存空間。
L2優點是實現簡單,能夠起到正則化的作用。缺點是無法獲得稀疏模型。
2、Data Augmentation
這是解決過擬合最根本也是最有效的方法。
實現手段:
1、從資料來源頭獲得更多資料。
2、使用映象、平移、新增噪聲、變換尺度、裁剪、調整曝光度、調整飽和度等手段對影象資料進行修改擴充

3、Dropout
Dropout的原理很簡單,就是隨機刪除網路內部隱藏單元。例如設定每個隱藏單元有50%的機率被刪除,最後得到的網路將會因為隱藏單元的減少而大大簡化。防止過擬合不就是要簡化模型,弱化模型的表達能力麼?

4、Early Stoping
這個更好理解了。提前終止就是在模型發生過擬合之前停止訓練。通常訓練的誤差會隨著訓練的輪次增加先減少再增加,訓練時間過長會將一些本不應該學習到的東西也學習進去。
5、選擇合適的模型
過擬合本質就是資料太少,而模型的表達能力太強,也就是模型太複雜。合理選擇模型有助於減少過擬合。