
後端分散式系列:分散式儲存-HDFS 與 GFS 的設計差異
「後端分散式系列」前面關於 HDFS 的一些文章介紹了它的整體架構和一些關鍵部件的設計實現要點。
我們知道 HDFS 最早是根據 GFS(Google File System)的論文概念模型來設計實現的。
然後呢,我就去把 GFS 的原始論文找出來仔細看了遍,GFS 的整體架構圖如下:
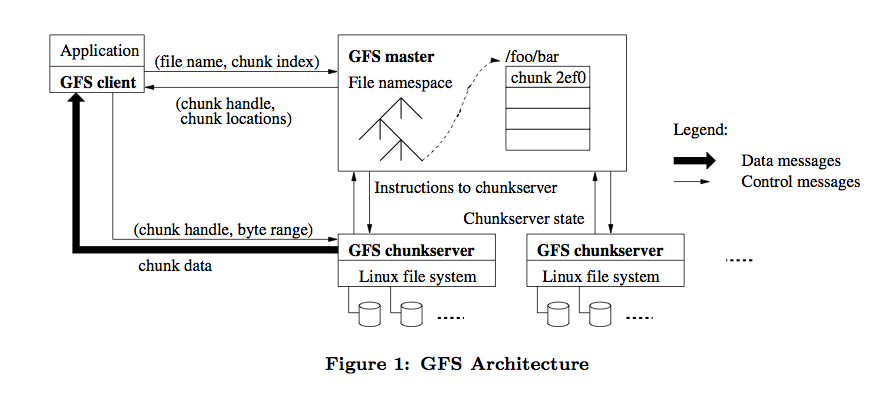
HDFS 參照了它所以大部分架構設計概念是類似的,比如 HDFS NameNode 相當於 GFS Master,HDFS DataNode 相當於 GFS chunkserver。
但還有些細節不同的地方,所以本文主要分析下不同的地方。
寫入模型
HDFS 在考慮寫入模型時做了一個簡化,就是同一時刻只允許一個寫入者或追加者。
在這個模型下同一個檔案同一個時刻只允許一個客戶端寫入或追加。
而 GFS 則允許同一時刻多個客戶端併發寫入或追加同一檔案。
允許併發寫入帶來了更復雜的一致性問題。
多個客戶端併發寫入時,它們之間的順序是無法保證的,同一個客戶端連續追加成功的多個記錄也可能被打斷。
這意味著一個客戶端在連續寫入檔案資料時,它的資料最終在檔案中的分佈可能是不連續的。
所謂一致性就是,對同一個檔案,所有的客戶端看到的資料是一致的,不管它們是從哪個副本讀取的。
如果允許多個客戶端同時寫一個檔案,怎麼保證寫入資料在多個副本間一致?
我們前面講 HDFS 時它只允許一個寫入者按流水線方式寫入多個副本,寫入順序一致,寫入完成後資料將保持最終一致。
而對多個客戶端而言,就必須讓所有同時寫入的客戶端按同一種流水線方式去寫入,才可能保證寫入順序一致。
這個寫入流程我們下一節詳細分析。
寫入流程
GFS 使用租約機制來保障在跨多個副本的資料寫入中保持順序一致性。
GFS Master 將 chunk 租約發放給其中一個副本,這個副本我們就稱為主副本,其他副本稱為次副本。
由主副本來確定一個針對該 chunk 的寫入順序,次副本則遵守這個順序,這樣就保障了全域性順序一致性。
chunk 租約機制的設計主要是為了減輕 Master 的負擔,由主副本所在的 chunkserver 來承擔流水線順序的安排。
如下圖,我們詳細描述下這個過程。
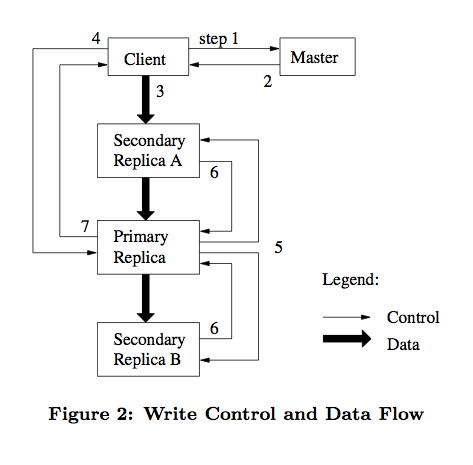
- 客戶端請求 Master 詢問哪個 chunkserver 持有租約以及其他副本的位置。
如果沒有 chunkserver 持有租約,說明該 chunk 最近沒有寫操作。
Master 則選擇將租約授權給其中一臺 chunkserver。 - Master 返回客戶端主副本和次副本的位置資訊。
客戶端快取這些資訊以備將來使用。
客戶端以後不再需要聯絡 Master,除非主副本所在 chunkserver 不可用或返回租約過期了。 - 客戶端選擇最優的網路順序推送資料,chunkserver 將資料先快取在內部的 LRU 快取中。
GFS 中採用資料流和控制流分離的方法,從而能夠基於網路拓撲結構更好地排程資料流的傳輸。 - 一旦所有的副本確認收到了資料,客戶端將傳送一個寫請求控制命令到主副本。
由主副本分配連續的序列號來確定最終的寫入順序。 - 主副本轉發寫請求到所有次副本,次副本按主副本安排的順序執行寫入操作。
- 次副本寫完後向主副本應答確認操作完成。
- 最後主副本應答客戶端,若任意副本寫入過程中出現錯誤,將報告給客戶端,由客戶端發起重試。
GFS 和 HDFS 的寫入流程都採用了流水線方式,但 HDFS 沒有分離資料流和控制流。
HDFS 的資料流水線寫入在網路上的傳輸順序與最終寫入檔案的順序一致。
而 GFS 資料在網路上的傳輸順序與最終寫入檔案的順序可能不一致。
GFS 在支援併發寫入和優化網路資料傳輸方面做出了最佳的折衷。
總結
GFS 的論文發表於 2003 年,後來大部分的分散式檔案系統設計實現或多或少都參考了 GFS 的設計思路。
而 HDFS 算是開源分散式檔案系統中最完整實現了 GFS 論文中的概念模型。
但 HDFS 依然簡化了 GFS 中關於併發寫的思路,本文就兩者的寫入模型和過程做了一些對比說明,並希望引發一些思考。
參考
下面是我的微信公眾號 [瞬息之間],除了寫技術的文章、還有產品的、行業和人生的思考,希望能和更多走在這條路上同行者交流,有興趣可關注一下,謝謝。
