
阿里移動推薦演算法大賽總結
一、 賽題說明
1. 競賽題目
在真實的業務場景下,我們往往需要對所有商品的一個子集構建個性化推薦模型。在完成這件任務的過程中,我們不僅需要利用使用者在這個商品子集上的行為資料,往往還需要利用更豐富的使用者行為資料。定義如下的符號:
- U:使用者集合
- I :商品全集
- P:商品子集,P ⊆ I
- D:使用者對商品全集的行為資料集合
那麼我們的目標是利用D來構造U中使用者對P中商品的推薦模型。
2. 資料說明
資料主要包含兩個部分。第一部分是1000萬用戶在商品全集上的移動端行為資料(D),包含如下欄位:
| 欄位 | 欄位說明 | 提取說明 |
|---|---|---|
| user_id | 使用者標識 | 抽樣&欄位脫敏 |
| item_id | 商品標識 | 欄位脫敏 |
| behavior_type | 使用者對商品的行為型別 | 包括瀏覽、收藏、加購物車、購買,對應取值分別為1,2,3,4 |
| user_geohash | 使用者位置的空間標識,可以為空 | 由經緯度通過保密的演算法生成 |
| item_category | 商品分類標識 | 欄位脫敏 |
| time | 行為時間 | 精確到小時級別 |
例項如:
141278390,282725298,1,95jnuqm,5027,2014-11-18 08
這些欄位中behavior_type欄位和time欄位包含的資訊量最大,user_geohash欄位由於缺失值太多,基本沒法使用。
第二個部分是商品子集(P),包含如下欄位:
| 欄位 | 欄位說明 | 提取說明 |
|---|---|---|
| item_id | 商品標識 | 抽樣&欄位脫敏 |
| item_geohash | 商品位置的空間資訊,可以為空 | 由經緯度通過保密演算法生成 |
| item_category | 商品分類標識 | 欄位脫敏 |
例項如:
117151719,96ulbnj,7350
訓練資料包含了抽樣出來的一定量使用者在一個月時間(11.18~12.18)之內的移動端行為資料(D),評分資料是這些使用者在這個一個月之後的一天(12.19)對商品子集(P)的購買資料。參賽者要使用訓練資料建立推薦模型,並輸出使用者在接下來一天對商品子集購買行為的預測結果。
3. 評估指標
比賽採用經典的精確度(precision)、召回率(recall)和F1值作為評估指標。具體計算公式如下:

其中PredictionSet為演算法預測的購買資料集合,每條記錄包含使用者id和商品id兩個欄位,即表示預測某使用者會在12月19日購買某商品;ReferenceSet為真實的答案購買資料集合。
二、 資料集分割
1. 日期分割
我們總共獲得了1000萬用戶在一個月的行為資料(11.18~12.18),需要預測的是在12月19日使用者的購買情況,因而我們採用滑窗的形式來構造訓練集和預測集。

線下
Train Feature Span :11.18~12.15
Train Target Span: 12.16
測試:12.17 —> 從11.18~12.16提取特徵
驗證:12.18 —> 從11.18~12.17提取特徵線上
Train Feature Span:11.18~12.17
Train Target Span: 12.18
預測:12.19 —> 從11.18~12.18提取特徵
對於線下模擬,我們用從11月18日到12月15日行為資料作為知識集,用來提取相關特徵,然後利用12月16日真實的情況來給特徵集打上label,如對於某個使用者商品對,如果使用者在12月16日真實購買了該商品,則在特徵表的該UI對最後一個欄位賦值1,這樣我們就得到了一個訓練集。然後我們再從11月18日到12月16日的行為資料中提取相關特徵,得到一個12月17日的測試集。為了保證訓練的模型具有穩定性,我們還需要一個驗證集作對比,即從11月18日到12月17日提取特徵,得到一個12月18日的驗證集。如果用12月16日訓練集得到模型,在測試集和驗證集上得到的F1值差不多(相差在0.02%左右),則說明這個模型是可靠的,同時也表明這些特徵構建也是有效的。然後我們可以利用11月18日到12月17日的資料來構建特徵,以12月18日的真實購買情況來打上label,得到一個線上的訓練集,用該訓練集訓練出來的模型來預測12月19日的購買情況(以11.18~12.18作知識集提取特徵)。
從比賽的實際情況來看,資料集的劃分對結果是有較大影響的。我們一開始一直以12月16日這天的真實情況作為訓練集,然後用訓練集的模型直接去預測17號、18號、19號三天的情況,在特徵維度只有200的時候,其結果並沒有太大的影響。但當後面我們加到300維特徵時,用12月16日訓練的模型去預測17、18、19號這三天的情況則產生了明顯的偏差,最優與最差的F1值能相差0.2%,直接影響到我們最後的成績。後面分析原因,極有可能是特徵提取的時間跨度不同,而後面增加的特徵又受時間跨度的影響較大,比如統計使用者的總瀏覽數,我們訓練集統計的是11月18日到12月15日共28天的資料,而預測17、18、19號的該特徵提取的時間跨度為29、30、31天,因而用12月16日訓練出來的模型去預測明顯是有偏差的。即我們的模型是基於28天的真實情況訓練出來的,而我們後面預測時知識集跨度卻是大於28天的,且隨著時間的推移偏差越來越大,以致模型並不能做出合理的預測。
2. 全集與子集
全集由於包含的資料量很大,對於訓練模型發現使用者的購物規律很有幫助,同時也能更準確的評價使用者的購物能力。但是用全集去訓練對<使用者,商品子集>這個層面的幫助是否還有那麼大意義?本次的主題是淘寶移動推薦,其商品主要是服務類商品,特點在於線上購買線下消費(O2O),這與平時意義的網上購物還是有一定的區別的,這一類的消費是否有其區別於其他消費的特點?因而訓練集有可以分為以下兩種情況:
- 直接用商品全集訓練
- 直接用商品子集訓練
在給定1000萬用戶的行為資料情況,全集每天發生購買的UI對在20萬條左右,而子集則在3萬條左右。從實際情況對比來看,用全集訓練的結果還是要明顯好於子集訓練,訓練結果相差在1%左右,原因就在於子集中的正例太少,雖然子集訓練也許更有針對性,但是由於資料量太小,並不能充分利用大資料量發現統計規律。
三、 特徵構建
關於特徵的構建,我們必須要明確一點:我們需要預測什麼?只有清楚的明白預測的主體,我們才能去構建合適的特徵。官方需要我們給出的是所有<使用者,子集商品>的購買情況,我們可以從任意一天的<使用者,子集商品>對的購買情況看出,其中絕大部分購買是使用者當天互動當天購買(一般有2/3左右),這些使用者商品對沒有任何歷史情況。對於這部分購買,我們實際上直接選擇了放棄預測,即只考慮預測這一個月中有歷史記錄的使用者商品對,這主要是基於以下兩個原因:
- 不能確定使用者是否會購買該商品
- 不能確定使用者會在什麼時候購買
我們沒法通過學習歷史資料去評估這兩個因素的影響,因而直接憑空預測的代價太高,會嚴重影響整體預測的準確度,這也決定了我們召回率的極限。所以,我們的預測主體是有互動歷史使用者商品對,預測的內容是使用者是否會購買該商品、使用者是否會在預測日當天購買。因此,我將特徵歸為以下四類:
1. 使用者特徵
使用者特徵就只是針對使用者來說的,反映的是使用者整個購物習慣與購物規律,而與具體哪件商品無關,比如使用者是不是喜歡瀏覽購物網站、使用者的購物頻率等。

此外還包括以下:
- 使用者評分(結合時間)
- 最大購買量距離預測日時長
- 使用者購買量與瀏覽量的比值
- 使用者發生二次購買商品數佔總購買商品數的比值
- 瀏覽過的商品中發生購買的比值
- 收藏商品中發生購買的比值
- 加購商品中發生購買的比值
- 雙12期間的瀏覽量、購買量以及其佔用戶總瀏覽、總購買的比值
- 雙12期間的活躍小時數佔總購買的比值
- 使用者近三天四種行為加權
2. 商品特徵
商品特徵反映的是商品本身的品質或者受歡迎程度如何,而與具體哪一個使用者沒有關係,同時商品特徵也體現了商品的活動規律,即被使用者購買的頻率、最後有人購買的時間等。

此外還包括以下:
- 商品評分
- 商品購買人數佔總瀏覽人數的比值
- 收藏商品的人中最後發生購買的比例
- 加購商品的人中最後發生購買的比例
- 購買商品的人中發生二次購買的比例
- 商品最大購買量距離預測日時長
- 商品雙12期間的瀏覽量、購買佔總瀏覽量、購買量的比值
- 該商品的互動量佔該類商品的互動量比值
- 該商品的購買量佔該類商品購買量的比值
3. 協同特徵
協同特徵則是以<使用者,商品>作為統計物件,是用來表現某個使用者對某件商品的喜愛程度或是購買的可能性,這一部分特徵直接與測試集資料對接,對預測結果起著決定性的作用。
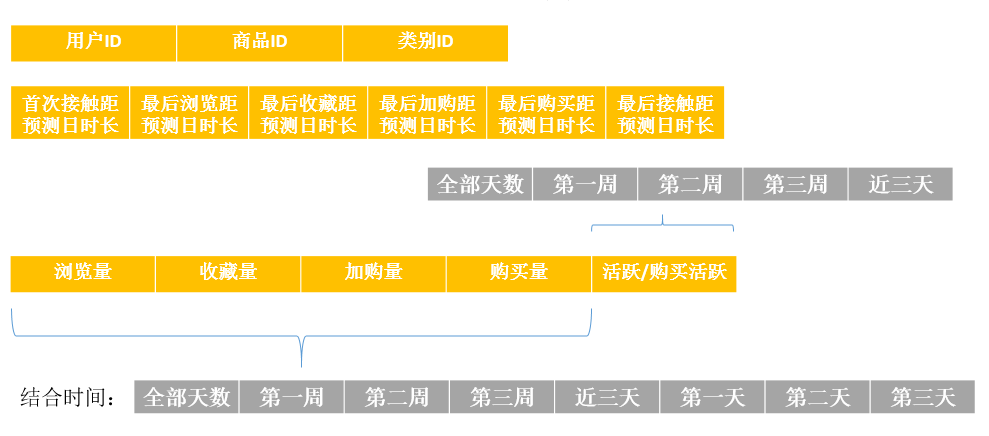
此外還包括:
- 使用者商品對評分
- 最大互動量距離預測日時長
- 使用者對該商品的瀏覽量佔用戶總瀏覽量的比值
- 使用者對該商品的購買量佔總購買量的比值
- 使用者對該商品的活躍小時數佔用戶總活躍小時數的比值
- 使用者雙12期間對該商品的活躍量、購買量佔總活躍量、購買量比值
4. 類別特徵
類別特徵對預測的影響主要體現在兩個方面:第一,通過對使用者對某一類商品的瀏覽、收藏、加購、購買情況可以看出使用者是否有可能購買該商品(不是誤點),以及使用者對這一類商品的偏愛程度;第二,主要是體現在物品競爭上,當我們需要判斷使用者是否會購買某個商品,可以看使用者在看該商品是還關注了多少同類商品,並藉此來評判使用者購買該商品的可能性。
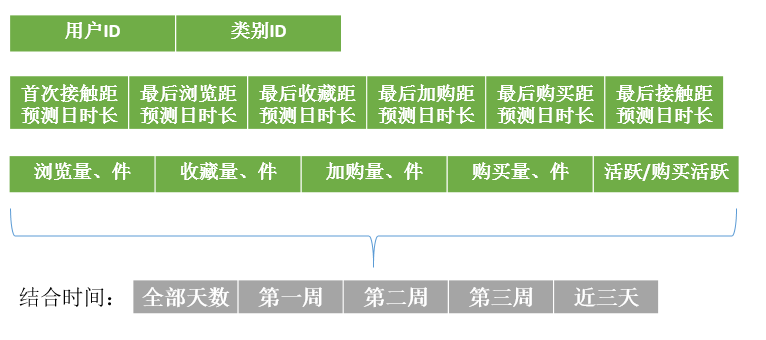
此外還包括:
- 對該類別的互動量佔用戶總互動量的比值
- 對該類別的購買量佔用戶總購買量的比值
- 使用者對該類商品的最大互動量距離預測日時長
- 對某一UI對,使用者最後接觸該商品的當天瀏覽、收藏、加購、購買了多少同類商品
- 使用者雙12期間對該類商品的互動量、活躍量、購買量佔總互動量、活躍量、購買量的比值
特徵的構建對於模型預測是至關重要的,它決定著我們成績的上限。在比賽的時候我們過早的進入了模型調參階段,花費了大量的時間和計算資源(被阿里警告),然而不管怎麼調整,其F1值的提升最多都不過0.2%(峰值在6.8%左右),原因就在於我們前期構造的特徵過於簡單,能夠給模型提供的資訊量有限,因此這也決定了模型預測的極限。同時我們對於時間的處理也不夠合理,前期我們對時間直接是做的截斷處理,直接丟棄了日期的小時欄位,只關注使用者行為發生在哪一天,這就影響了到了相關特徵的準確性(如使用者對商品的最後接觸時間)。在師兄的提醒下我們把相關特徵換成小時後,F1直接提升了0.5%。之後我們又新增了將近100維的新特徵,線下測試F1的峰值到了8.3%,由此可見特徵對於整個預測的重要性。
四、 資料預處理
1. 異常點剔除
我們在得到完整的特徵表後,發現裡面有一些使用者的瀏覽量的值特別大(最大超過200萬),已經超出了合理水平,我們分析其原因可能是,這些使用者是爬蟲使用者,因此這些使用者對商品的行為並不能作為預測使用者購買商品的依據。同時,我們預測的是所有歷史記錄中出現過的使用者商品對,這些使用者的存在無疑會增大我們的預測量,同時也會對我們正常模型訓練產生干擾,因而我們選擇將這些使用者過濾掉,過濾規則如下:
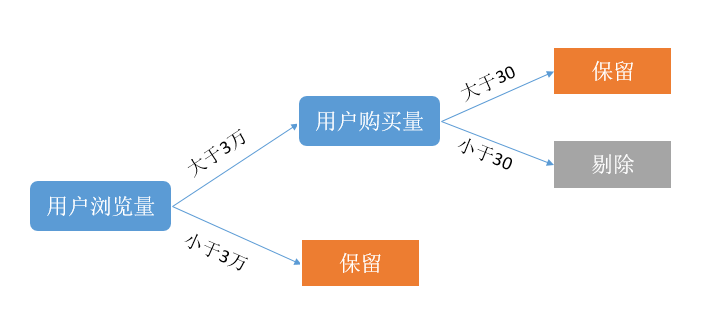
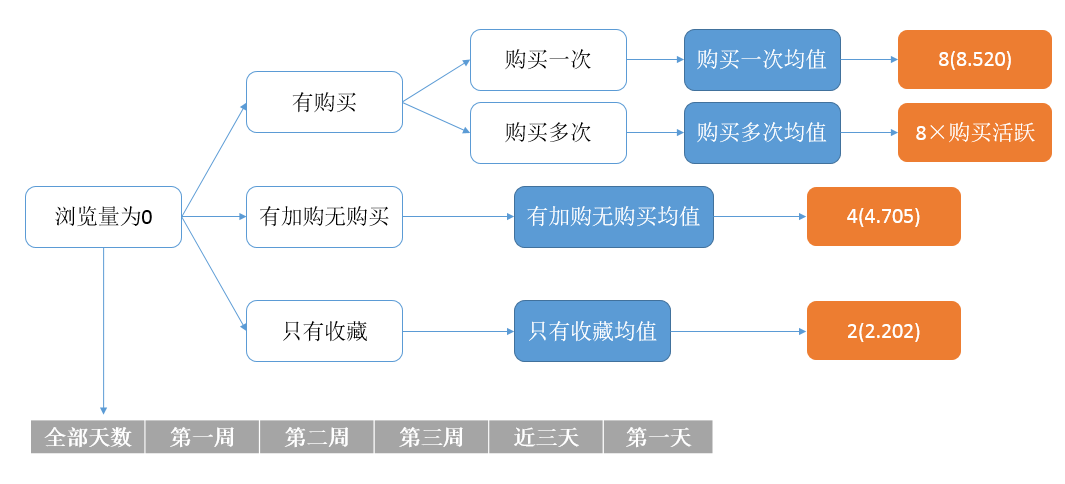
2. 缺失值填充
由於系統只能記錄使用者的發生點選的行為,這就可能造成使用者對於某商品瀏覽量為0,而收藏、加購、購買量不為0的情況。然而現實卻是無論你對商品進行收藏、加購、購買哪種行為,你必定會先瀏覽它們,因此我們對於瀏覽量為0的UI對進行了補值操作,具體補值規則如下:
對於整個資料預處理,由於沒有做對比,我不能清楚的知道我所做的這些操作是有利於提升預測的準確率,還是會因為破壞了資料的真實性而對預測產生干擾。而且嚴格意義上來講,我對資料的預處理都是在已獲取的特徵表上進行操作,而不是對官方提供的原始資料進行預處理。
五、 模型與調參
1. 模型選擇
隨機森林(Random Forest)
隨機森林,顧名思義,是用隨機的方式建立一個森林,森林裡面有很多的決策樹組成,隨機森林的每一棵決策樹之間是沒有關聯的。在得到森林之後,當有一個新的輸入樣本進入的時候,就讓森林中的每一棵決策樹分別進行一下判斷,看看這個樣本應該屬於哪一類(對於分類演算法),然後看看哪一類被選擇最多,就預測這個樣本為那一類。
在建立每一棵決策樹的過程中,有兩點需要注意:取樣與完全分裂。首先是兩個隨機取樣的過程,random forest對輸入的資料要進行、列的取樣。對於行取樣,採用有放回的方式,也就是在取樣得到的樣本集合中,可能有重複的樣本。假設輸入樣本為N個,那麼取樣的樣本也為N個。這樣使得在訓練的時候,每一棵樹的輸入樣本都不是全部的樣本,使得相對不容易出現over-fitting。然後進行列取樣,從M個feature中,選擇m個(m << M)。之後就是對取樣之後的資料使用完全分裂的方式建立出決策樹,這樣決策樹的某一個葉子節點要麼是無法繼續分裂的,要麼裡面的所有樣本的都是指向的同一個分類。
GBDT(Gradient Boosting Decision Tree)
迭代決策樹在我理解更像是一種資料的序列處理,對於每一個訓練樣本,一棵決策樹在進行處理後將其交給下一個決策樹,其核心就在於每一棵樹學的是之前所有樹的結論和的殘差,這個殘差就是一個加預測值後能得真實值的累加量。以預測年齡為例,A的真實年齡是18歲,但第一棵樹的預測年齡是12歲,差了6歲,即殘差為6歲。那麼在第二棵樹裡我們把A的年齡設為6歲去學習,如果第二棵樹真的能把A分到6歲的葉子節點,那累加兩棵樹的結論就是A的真實年齡;如果第二棵樹的結論是5歲,則A仍然存在1歲的殘差,第三棵樹裡A的年齡就變成1歲,繼續學。
兩種演算法其實都是對決策樹進行組合,RF採用的是Bagging的思想,即每棵樹共同投票決定,類似於一種並行決策機制;GBDT採用的是boosting的思想,每棵樹的決策都是基於上一棵樹的結果,類似於一種序列決策機制。從我們的實際經驗來看,在使用相同特徵的情況下,我們使用RF模型的F1峰值在(7.0%),而GBDT的峰值在8.3%。當然這裡面也有我們沒有將RF調整到最優的原因,而GBDT在選擇相對較大引數的情況與最優效能差異不大,可以理解為該特徵集在該模型下的預測極限。
2. 引數調整
對這兩個模型的引數調整必須要對模型有充分的瞭解,並非簡單的理解其基本的原理即可。我們在比賽的時候,正是由於不理解每個引數對預測的影響以及每個引數之間的相互作用,花了費許多不必要的時間去遍歷這些引數,其主要需要考慮的引數如下:
- 屬性度量選擇(資訊增益、增益率、基尼指數)
- 每個節點使用的特徵數量
- 每棵樹的訓練樣本量(越多越好,但訓練時間是個問題)
- 樹的深度
- 葉子節點最小記錄數(與訓練樣本量有關)
- 最小葉子節點數目(跟樹的深度、屬性度量以及葉子節點最小記錄數都有關)
- 迭代速率(GBDT)
屬性度量選擇實際上決定著你採用哪種決策樹演算法,因此對ID3、C4.5、Cart演算法都需要有所瞭解,同時一定要注意你的特徵是連續的還是離散的,這可能會導致較大的訓練偏差;每個節點使用的特徵數量我們選擇的是總特徵數開平方,當然如果特徵維度特別大也可以取總特徵數的對數;對決策樹而言如果訓練樣本的數量越多,預測的穩定性就越強,這很好理解,樣本資料越大越接近真實分佈,但是過多的訓練樣本可能需要很長的訓練時間,同時隨機森林和GBDT對訓練量的變化也有不同,GBDT訓練量的增加對預測結果的提升要比隨機森林明顯,這或許是迭代的強大之處吧。
至於樹的深度、葉子節點的最小記錄數、最小葉子節點數目這些引數實際上是對樹的前剪枝,避免出現過擬合,一般來說GBDT樹的深度要偏小一些,RF的深度相對要大一些,葉子節點數同樣會限制樹的生長,至於葉子節點最小記錄數則與訓練資料量有關,都需要憑經驗來設定。迭代速率類僅GBDT包含,設的過大一般容易越過最優值,太小的又可能學習過慢,個人感覺一般設定在0.05~0.1之間都是可以的。
由於要調整的引數很多,我們按照如下的思路去一步步優化尋找最優的F1值:
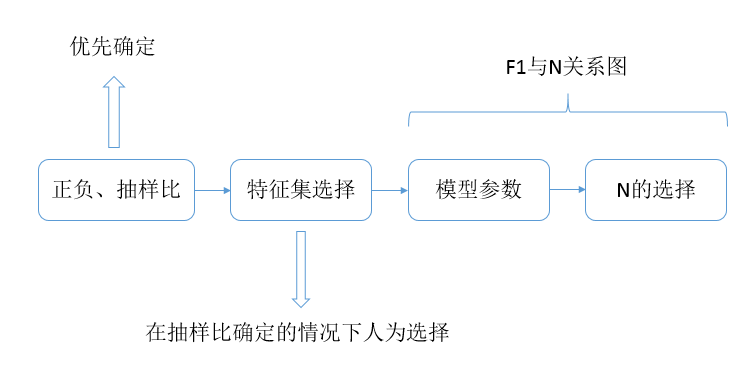
六、 自己的嘗試
1. 分類訓練
不同的使用者商品互動情況對於預測內容是不同的,如使用者購買過該商品,那麼通過使用者特徵、商品特徵去評價使用者是否會購買該商品就沒什麼太大意義了,我們預測的重點就變成了使用者會不會二次購買以及什麼時候發生二次購買。因此,我們可以將原始的二分類問題轉換為基於使用者歷史行為的多分類問題,具體分類如下:
- 使用者只瀏覽過該商品
- 使用者只收藏過該商品(有記錄就一定有瀏覽)
- 使用者只加購過該商品(收藏也併入加購)
- 使用者購買過該商品
考慮這四種情況的分類實際體現的使用者的一個行為轉移,即使用者看了就買、使用者看了然後收藏再購買、使用者加購再購買、使用者買過再購買。我在小資料集上以1216為樣本進行相關的資料統計,結果如下:
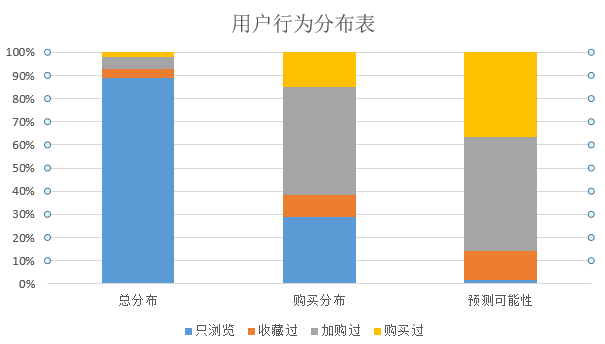
從統計結果可以看出,要預測的使用者商品對中,絕大部分是隻瀏覽過,而在1216日當天,發生購買的使用者商品對中有歷史加購行為的最多,其次是隻瀏覽的(畢竟基數比較大)。但是從預測難度角度來看(發生購買與要預測的比值),預測只瀏覽過的使用者商品對的難度最高,其發生購買的概率不到萬分之一,而預測有購買和加購行為的難度較低,都在千分之一以內。
將二分類問題轉換為多分類問題,一方面模型更加專一,有利於提升預測的準確性;另一方面特徵的維度也能降低,因為四種模型所需特徵都不盡相同。因此,接下來我們需要做的工作就是:
- 對於不同模型提取不同特徵
- 將不同模型的輸出進行合理的組合
關於特徵提取,我是直接基於使用者、商品、使用者商品對、使用者類別構建四張通用的特徵表,四種模型從這張總表中選取各自所需的特徵,如果模型還需要一些特有的特徵,再進行單獨提取。
對四個模型輸出的組合,我考慮的是單獨去評估每個模型,看每個模型的預測代價的最小值,即最少預測多少個使用者商品對就能預測準確一個,然後根據這個預測代價來進行預測資料融合。如果某一模型的代價特別大,如使用者只瀏覽過該商品,我們是否應該選擇放棄這部分呢?我的想法是再弄一個全特徵的模型,然後將其輸出與使用者只瀏覽的模型取交集,大致流程如下:
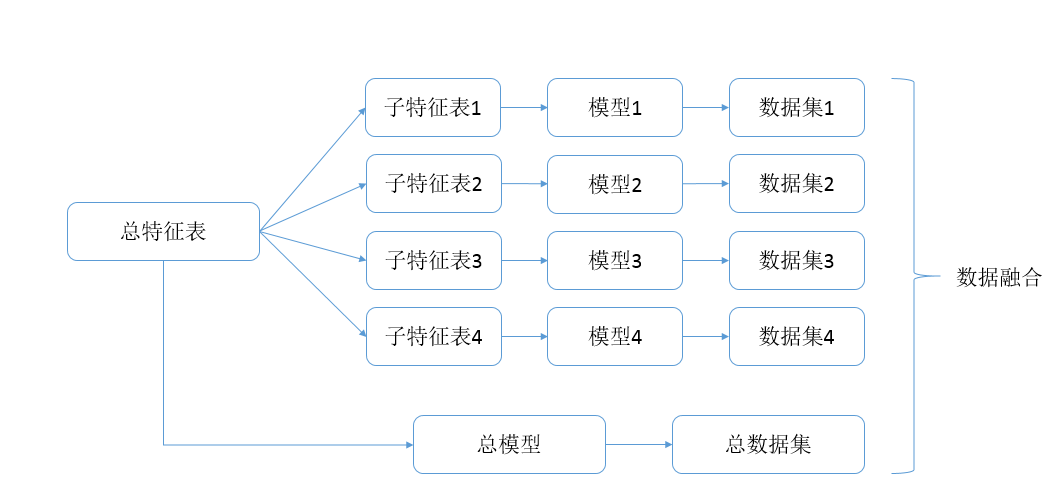
不知道是不是我執行的問題還是怎麼回事,最終得到的效果很差,花了很長時間去嘗試結果很不理想還是挺讓人懊惱的。後來師兄給了我一個我覺得相對合理的解釋,我所做的這種預分類其實意義不是很大,因為決策樹最大的優點就在於幫我們找到最合理的分割,我這種分割UI對的方式不一定利於模型的預測,更何況後續的融合方式問題也很大,分割後每個集合正負樣本比例如何確定、訓練量如何確定等都值得商榷。
2. 模型融合
由於我們只使用了RF和GBDT兩個模型,因此我們將RF和GBDT輸出的label為1的概率值結合起來作為一個特徵向量,以真實的UI對label作為該特徵向量的label,然後利用LR模型對兩個模型的輸出進行融合,這實際是在利用LR來決定兩個模型輸出的權重,由於我們的GBDT跑出來的效果要比RF好太多,融合之後實際上與原GBDT的輸出差別並不大,但提交到線上確實能夠提升一點點,可以說還是相對提升了整個模型的穩定性吧。
七、 總結
由於是第一次參加資料探勘的比賽,抱著一種半學習半競賽的態度,因此能做到這樣自己還是挺滿足了,畢竟學習不是一蹴而就的事情,雖然最後被擠出前50還是挺讓人不爽的。通過這次比賽,我對整個資料探勘的流程更加明瞭,對我所使用過的模型也有了深一步的理解,同時也有如下體會:
- 資料探勘需要極大的耐心和細心,資料預處理、特徵提取連線、線下訓練預測、線上提交任何一步出問題都可能導致意想不到的結果,這一方面需要我們提前確定好一個框架,做到有條不紊,另一方面也需要我們對一個步驟都做到認真細緻
- 不要過早的陷入到模型引數的調整,更不要盲目調參,要去理解模型的學習和預測,不然不停的試引數只是浪費時間和精力;要多在特徵上做文章,這決定著你成績的理論上界,模型調參的過程只是幫助你逼近這個上界
- 在構建特徵時一定要主要保證訓練集和預測集上的特徵分佈一致,不然可能會造成線上線下偏差很大
- 要多跟人溝通,一個人很容易跳進坑裡,可能最後比賽完了你都還沒從坑裡爬出來,集思廣益才能有所提升