
移動推薦演算法(四):基於LR, RF, GBDT等模型的預測
移動推薦演算法是阿里天池賽2015年賽題之一,題目以移動電商平臺的真實使用者-商品行為資料為基礎來構建商品推薦模型。該題現已成為新人入門的經典演練物件,博主也希望基於該題場景,加深對機器學習相關知識的理解,積累實踐經驗。關於題目回顧與資料初探,可參考:天池離線賽 - 移動推薦演算法(一):題目與資料解析,本文討論如何基於模型來進行預測,測試的模型包括邏輯迴歸(LR)、隨機森林(RF)、梯度迭代提升樹(GBDT)。
基於模型的預測
面向模型的資料預處理
經過天池離線賽 - 移動推薦演算法(三):特徵構建之後,在對特徵資料樣本套用模型進行分類預測之前,還需要根據具體所採用的模型對資料進行二次預處理,下面討論其中重要的幾點:
正負樣本失衡問題
經過特徵構建所得的資料集正負樣本比例約為 1:1200,資料嚴重失衡,易導致模型訓練失效。在這裡,我們可通過下采樣和基於 f1_score 的評價標準來應對此問題。
若考慮對訓練集中的負樣本進行下采樣。為避免隨機取樣的特徵空間覆蓋性不足,先對負樣本進行k-means聚類(參考Sergey Feldman所提方法(2)),然後在每個聚類上採用subsample來獲得全面的負樣本取樣,最後與正樣本組成較為平衡的訓練集。
缺失值問題
在所構建的特徵中,一些特徵存在缺失值(如xx_diff_hours),這裡,採用移除缺失值特徵的資料集進行LR模型的訓練,採用將缺失值賦值為-1的訓練集進行RF/GBDT模型的訓練。
歸一化問題
在進行k-means和LR時,需要對不同度量尺度的特徵進行歸一化處理,這裡我們採用
sklearn.preprocessing.StandardScaler()實現。
邏輯迴歸
邏輯迴歸(logistic regression,簡稱LR)是一種線性迴歸模型,另一種貼切的名稱是“對數機率迴歸”,該模型採用對數機率函式逼近預測結果。這裡採用sklearn.linear_model.LogisticRegression來訓練模型。
由於LR模型對正負樣本平衡十分敏感,所以在k-means的基礎上採用下采樣,通過引數調節選取最優的正負樣本比(N/P_ratio),下圖是LR訓練時的 f1_score 隨
N/P_ratio 變化示意圖:

從圖中看出,由於採用的是 f1 值進行評價,LR 模型在一定的 N/P_ratio 下的結果好一些,下面分別取 N/P_ratio = 35 和 N/P_ratio = 55,以預測的Sigmoid函式閾值引數 cut_off 為變數,觀察模型在驗證集上的表現:

由上圖看出,當 N/P_ratio 取值不同時,cut_off 的最優取值也不同,當 N/P_ratio 較小時,正例的特徵空間相對較大,故而 cut_off 取值需要大一些,以壓縮正樣本預測空間,減小偏差;反之 cut_off 取值小一些。
將兩種 [N/P_ratio, cut_off] 引數下的模型預測結果上傳,評分如下所示:

可見,由於直接採用LR初始模型,結果不令人滿意(比前面基於規則的預測效果要差)。在過程中我們發現,由於資料隨機性、非線性等因素,採用 LR 這樣的線性模型許難以實現更好的效果,所以重新考慮採用RF、GBDT等整合模型來實現。
隨機森林
隨機森林(Random Forest,簡稱RF)是一種基於決策樹基模型的整合學習方法,其核心思想是通過特徵取樣來降低訓練方差,提高整合泛化能力。這裡我們採用sklearn.ensemble.RandomForestClassifier來隨機森林的訓練與預測任務。
在RF(或GBDT)的訓練過程中,引數調節(parameter tuning)十分重要,一般地,將整合學習模型的引數分為兩大類:過程引數和基學習器引數,一般地,先除錯過程引數(如RF的基學習器個數n_estimators等),然後再除錯基學習器引數(如決策樹的最大深度max_depth等)。
下面討論幾個重要引數:
N/P_ratio(負正樣本比例)
其實對於隨機森林模型和下面的GBDT模型來說。其基學習器(決策樹)採用“entropy”、“gini“等作為建樹依據,對不同類別的劃分具有強制作用。這類的模型對於類別失衡不敏感。但是過量冗餘的負樣本會嚴重加大訓練消耗,所以也可以考慮在不影響模型訓練的前提下對資料進行取樣。
n_estimators(森林規模)
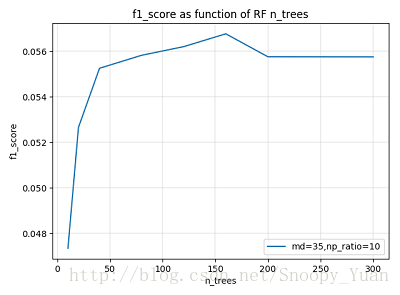
n_estimators 代表隨機森林中基學習器(決策樹)的個數,對應著“森林”的大小。一般地,森林規模越大,整合的方差越小,模型泛化能力越強,但規模越大導致計算開銷越大,所以在保證泛化能力前提下取較合適的 n_estimators 值即可。
下圖示是在某次引數調節中驗證集 f1_score 隨 n_estimators 的變化曲線,可以看到當 n_estimators 達到一定大小以後,繼續增大無助於模型效能的提升。
max_depth(樹深度)
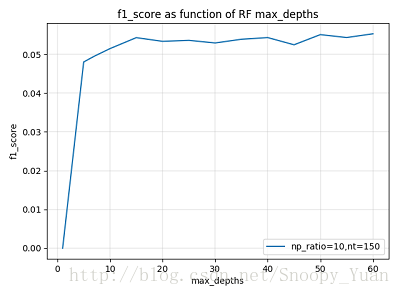
max_depth 屬於基學習器引數,它控制著每個決策樹的深度,一般來說,決策樹越深,模型擬合的偏差越小,但同時擬合的開銷也越大。一般地,需要保證足夠的樹深度,但也不宜過大。
下圖示為某次引數調節過程中驗證集 f1_score 隨 max_depth 的變化曲線,可以看到當 max_depth 達到一定大小以後,繼續增大無助於模型效能的提升。
min_samples_split(劃分樣本數)/min_samples_leaf(葉最小樣本數)
這兩個引數控制著分支粒度,防止著過擬合,效果相似。在RF中單個基學習器關注偏差,其葉節點粒度應該很小,所以這兩個引數應設定得比較小。
cut_off(預測概率閾值)
模型在對樣本進行二分類預測時,首先得出的是樣本所屬類別的概率,然後通過閾值(如取cut_off = 0.5)劃分得出結果。比如說:大於閾值判為正例,小於閾值的判為反例。該閾值反應了我們對於預測把握的估計,閾值越大的,要求的預測似然越大,對應的預測類別特徵空間相應的收縮。
下圖示為某次引數調節過程中驗證集 f1_score 隨 cut_off 的變化曲線,可以看到,此時的閾值應取大一些。

此外,還有許多的引數需要在模型訓練時予以考慮。總的來說,引數調節是為了找到最適合於當前資料分佈下的模型,由於引數眾多,要找到這樣一個全域性最優的引數組合在實踐中往往做不到,一個合理的方法是採用貪心的思路,先過程引數再基學習器引數,粗調與細調相結合,爭取找到區域性最優的引數組合,多次迭代此過程,使得區域性最優的引數組合滿足任務要求。
下面是兩套引數組合下的預測結果評分,可以看到,基於此隨機森林模型的預測結果明顯優於之前的結果:

GBDT
GBDT(梯度迭代決策樹)是一種基於決策迴歸樹的Boosting模型,其核心思想是將提升過程建立在對“之前殘差的負梯度表示”的迴歸擬合上,通過不斷的迭代實現降低偏差的目的。這裡我們採用sklearn.ensemble.GradientBoostingClassifier來實現GBDT分類器。
同隨機森林一樣,GBDT在訓練時也需要進行大量的引數調節工作,以期獲得適合於當前資料任務的模型。這裡依然將GBDT的引數分為過程引數和基學習器引數兩類,首先調節過程引數(學習率、基學習器個數等),然後調節基學習器引數(樹深度、葉子分裂樣本數等),推薦採用啟發貪心式的引數調節方法,反覆調節以期得到較好的引數組合。GBDT具體的調參物件與隨機森林類似,但要注意二者整合本質的區別,下面是對一些重要引數的討論:
N/P_ratio(負正樣本比例)
和隨機森林一樣。考慮到過量冗餘的負樣本會嚴重加大訓練消耗,考慮在不影響樣本資訊充分性的前提下對資料進行取樣。
learning_rate(學習率)/n_estimators(基學習器數目)
這裡,learning_rate 和 n_estimators 分別控制迭代的步長和最大迭代次數,所以,這兩個引數應當一起除錯,尋找最優的組合。GBDT設定大量基學習器的目的是為了整合來降低偏差,所以 n_estimators 一般會設定得大一些。
下圖示為某次引數調節過程中驗證集 f1_score 在不同 learning_rate 取值下隨 n_estimators 的變化曲線。從圖中可以看出,過大學習率導致擬合效果很差甚至出現發散,過小的學習率導致擬合太慢;另外我們可以看出,當迭代達到一定次數時,繼續迭代對模型提升效果不大,據此可選擇出一個合適的
n_estimators取值。max_depth(樹深度)
對於GBDT模型來說,其每個基學習器是一個弱學習器,決策樹的深度一般設定得比較小,以此來降低方差,之後在經過殘差逼近迭代來降低偏差,從而形成強學習器。所以不同於隨機森林模型,這裡的 max_depth 引數值應設定得比較小,
下圖示為某次引數調節過程中驗證集 f1_score 隨 max_depth 的變化曲線。
min_samples_split(劃分樣本數)/min_samples_leaf(葉最小樣本數)
在GBDT中,單個基學習器側重於降低方差,其葉節點粒度應該比較粗,所以這兩個引數應設定得較大,但同時要考慮到資料失衡的情況,所以又不能設定得過大。
下圖示為某次引數調節過程中驗證集 f1_score 隨 min_samples_leaf 的變化曲線。
cut_off(預測概率閾值)
同隨機森林中該項引數一致,cut_off 控制著我們對結果的置信程度。下圖示為某次引數調節過程中驗證集 f1_score 隨 cut_off 的變化曲線,可以看出,當前引數設定下的訓練器,取 cut_off ~ [0.4,0.6]比較合適,(p.s.cut_off分佈較對稱且矮胖得出來的結果比較穩定)。




除了上述引數之外,在一般調參的過程中還需要考慮的引數有:參考隨機森林引入特徵隨機性的引數 max_features ,控制葉節點分裂粒度的引數 min_samples_split、min_samples_leaf 等。
下面是兩套引數組合下的預測結果評分,可以看到,基於此GBDT模型的預測結果:

(p.s.藉助GBDT的強大力量再次rank到了第2名….2/5000)
結果總結
1. 過程回顧
任務被確立為基於模型的二分類,總體任務明確為是:分類模型套用 + 引數調節。
採用最簡單的邏輯斯蒂迴歸(LR)進行了訓練與預測,效果很差,進一步驗證了資料隨機性強、非線性的問題。
採用兩種主流的整合學習方法隨機森林(RF)和梯度提升樹(GBDT)進行了訓練與預測,效果提升明顯,說明這種樹整合的模型對工程實踐中的隨機性、非線性強,特徵規約困難的資料適應性好。
2. 關於引數調節
在採用整合學習模型RF和GBDT時,引數優化對模型效果的提升十分明顯,但是最優引數的獲取往往是一個NP難題,故而採用啟發式的貪婪搜尋是一個相對好的選擇。
對於整合模型,我們將其引數分為過程引數和基學習器引數兩種,根據其對模型效能影響大小的經驗判斷來依次對其進行優化,不斷的迭代往復進行直到獲得一個滿足要求的引數組合(一般是區域性最優)。注意在整個過程中對擬合程度的把握,防止欠擬合/過擬合,擬合程度可根據訓練過程中的訓練損失(Train loss)、袋外估計(OOB),驗證過程中的f1分數變化曲線等資訊結合經驗判斷。
3. 其他
考慮到模型訓練的效率以及對資料資訊的學習能力,下一步擬採用XGBoost以期更好地實現當前任務。
參考資料
下面列出本文涉及的重要參考來源: