
用scrapy爬取ttlsa博文相關數據存儲至mysql
這段時間我就通過scrapy來收集下此博客內文章的相關數據,供以後需要從中提取我認為值得看的文章作為數據依據.
今天,要做的事就是把數據先抓取出來,後期再將其數據存儲起來.
首先通過命令
scrapy genspider ttlsa www.ttlsa.com創建一個蜘蛛程序應用名為ttlsa
其次在ttlsa.py下編寫如下代碼.
# -*- coding: utf-8 -*- import re from urllib import parse from datetime import datetime import scrapy from scrapy.http import Request from ScrapyProject.utils.common import get_object_id ‘‘‘ 獲取ttlsa文章相關數據 ‘‘‘ class TtlsaSpider(scrapy.Spider): name = ‘ttlsa‘ allowed_domains = [‘www.ttlsa.com‘] start_urls = [‘http://www.ttlsa.com/‘] def parse(self, response): post_nodes = response.css("article") for node in post_nodes: front_img_url = node.css("figure:nth-child(1) > a:nth-child(1) > img:nth-child(1)::attr(src)").extract_first("") #create_time = node.css("div:nth-child(3) > span:nth-child(3) > span:nth-child(1)::text").extract_first("") url = node.css("figure:nth-child(1) > a:nth-child(1)::attr(href)").extract_first("") url = parse.urljoin(response.url,url) if url != "http://www.ttlsa.com/": yield Request(url=url,meta={"front_img_url": front_img_url}, callback=self.parse_detail) next_page = response.css(".next ::attr(href)").extract_first("") if next_page: yield Request(url=parse.urljoin(response.url,next_page),callback=self.parse) def parse_detail(self,response): front_img_url = response.meta.get("front_img_url", "") try: create_time = response.css(".spostinfo ::text").extract()[3] pattern = ".*?(\d+/\d+/\d+)" m = re.match(pattern, create_time) create_time = datetime.strptime(m[1], "%d/%m/%Y").date() except IndexError: create_time = datetime.now().date() title = response.css(".entry-title::text").extract_first("") #評論數 comment_nums = response.css("div.entry-content li.comment a::text").extract_first("0") comment_nums=comment_nums.replace("發表評論", "0") #點贊數 praise_nums = response.css("a.dingzan .count::text").extract_first("0").strip() #tags tags = ",".join(response.css("ul.wow li a::text").extract()) content = response.css(".single-content").extract() from ScrapyProject.items import TtlsaItem ttlsa_item = TtlsaItem() ttlsa_item["title"] = title ttlsa_item["comment_nums"] = comment_nums ttlsa_item["praise_nums"] = praise_nums ttlsa_item["tags"] = tags ttlsa_item["content"] = content ttlsa_item["create_time"] = create_time ttlsa_item["front_img_url"] = [front_img_url] ttlsa_item["url"] = response.url ttlsa_item["url_object_id"] = get_object_id(response.url) #使用yield,將會跳轉到pipelines裏執行相關類中,需要在settings.py中開啟並且設置正確的ITEM_PIPELINES yield ttlsa_item
items.py
class TtlsaItem(scrapy.Item): title = scrapy.Field() comment_nums = scrapy.Field() praise_nums = scrapy.Field() tags = scrapy.Field() content = scrapy.Field() create_time = scrapy.Field() front_img_url = scrapy.Field() #記錄下載的圖片本地路徑 front_img_path = scrapy.Field() url=scrapy.Field() #因為url是固定長度,所以我們希望能獲取一個固定長度的url對象值,供以後重復收集數據以判定是添加還是更新 url_object_id=scrapy.Field()
pipeline.py
class TtlsaPipeline(object):
def process_item(self,item,spider):
return item
settings.py
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
‘ScrapyProject.pipelines.TtlsaPipeline‘: 300, #註意這裏的數字,越小越優先執行
}
通過代碼調試功能,便可以看到我們已經獲取到我們想要的數據了.
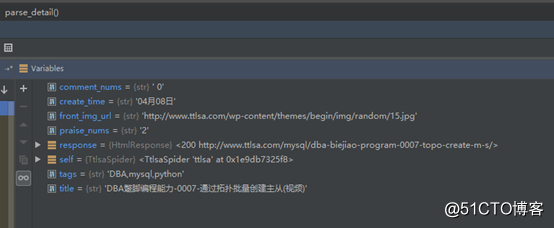
並且在pipeline內打上斷點,也能從pipeline中獲取到數據了.
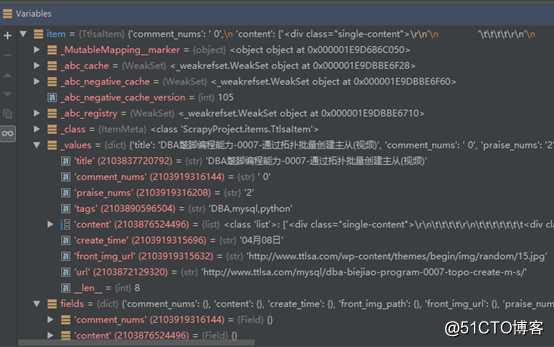
使用scrapy自帶的pipeline下載圖片,並且將其下載到本地,並且將圖片路徑保存到item中
1.重寫pipeline
from scrapy.pipelines.images import ImagesPipeline,DropItem
class TtlsaImagesPipeline(ImagesPipeline):
def item_completed(self, results, item, info):
image_paths = [x[‘path‘] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item[‘ front_img_path ‘] = image_paths
return item
2.設置settings.py
ITEM_PIPELINES = {
‘ ScrapyProject.pipelines. TtlsaImagesPipeline ‘: 1,
}
IMAGES_URLS_FIELD = "front_img_url"
project_dir=os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir,"images")3.在項目錄下新建一個images目錄,如圖:
這樣,我在抓取網站圖片後,就可以將其下載到項目的images目錄下了.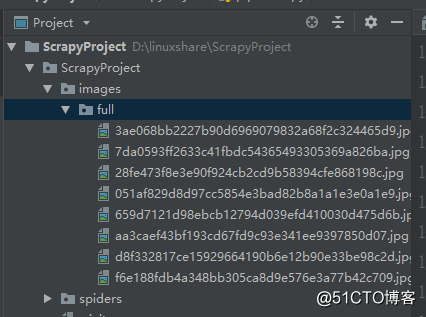
並且可以看到我們下載的圖片路徑存儲到item[‘front_img_url’]中了.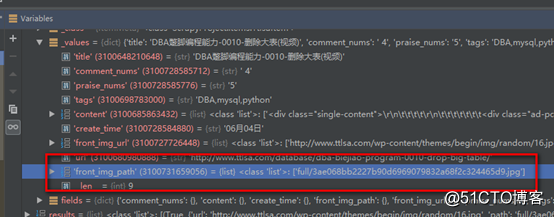
對與此字段url_object_id=scrapy.Field()我們可以使用hashlib庫來實現.
utils/common.py
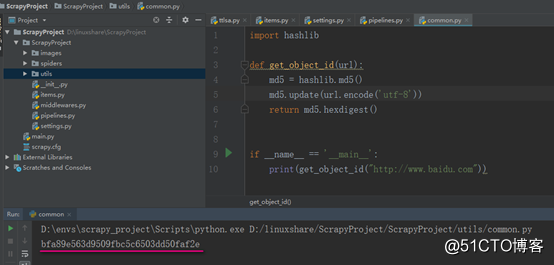
import hashlib
def get_object_id(url):
md5 = hashlib.md5()
md5.update(url.encode(‘utf-8‘))
return md5.hexdigest()
if __name__ == ‘__main__‘:
print(get_object_id("http://www.baidu.com"))
這時候我們在ttlsa.py中這樣改寫.
from ScrapyProject.utils.common import get_object_id
ttlsa_item["url_object_id"] = get_object_id(response.url)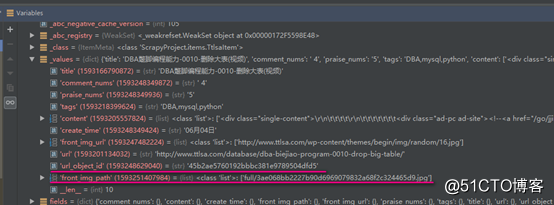
好了,該獲取的數據都已經獲取了,下面我們將其數據存儲起來,供以後分析.
存儲這塊,我考略將其分2部分,第一部分存儲到文件,另一部分存儲到mysql
1.存儲到文件
1.1修改pipelines.py
class JsonWithEncodingPipeline(object):
#自定義json文件的導出
def __init__(self):
self.file = codecs.open(‘ttlsa.json‘, ‘w‘, encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
1.2 修改settings.py
ITEM_PIPELINES = {
‘ScrapyProject.pipelines.TtlsaImagesPipeline‘: 1,
‘ScrapyProject.pipelines.JsonWithEncodingPipeline‘:2,
}
這樣我們就可以將數據存儲到ttlsa.json文件中了.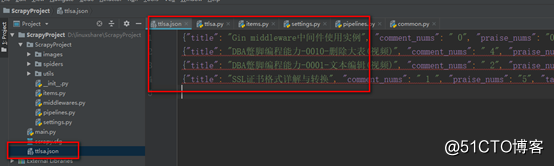
2.存儲到mysql中
2.1設計存儲mysql庫ttlsa_spider表article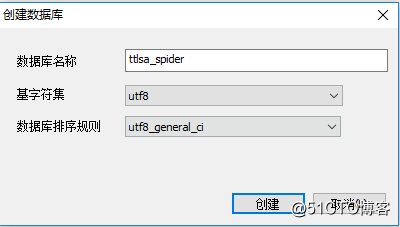
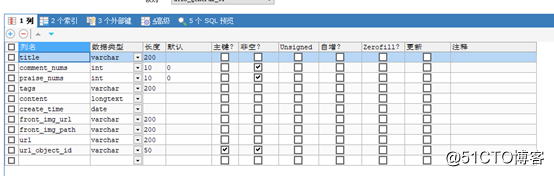
讓我們編寫一個MysqlPipeline,讓其抓取的數據存儲到mysql中吧.
import MySQLdb
class MysqlPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(‘localhost‘, ‘root‘, ‘root‘, ‘ttlsa_spider‘, charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
insert_sql = """
insert into article(title,url,url_object_id,comment_nums,praise_nums,tags,content,create_time,
front_img_url,front_img_path)
values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
self.cursor.execute(insert_sql,(item["title"], item["url"], item["url_object_id"], int(item["comment_nums"]),
int(item["praise_nums"]), item["tags"], item["content"], item["create_time"],
item["front_img_url"], item["front_img_path"]))
self.conn.commit()
註意:我們將評論數,占贊數強制轉換成int類型了.
修改settings.py
ITEM_PIPELINES = {
‘ScrapyProject.pipelines.TtlsaImagesPipeline‘: 1,
#‘ScrapyProject.pipelines.JsonWithEncodingPipeline‘: 2,
‘ScrapyProject.pipelines.MysqlPipeline‘: 3,
}
Debug跑下看看可有什麽問題.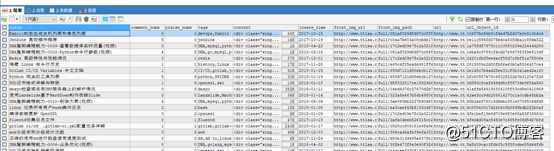
通過不斷按F8,數據源源不斷的流進數據庫了,哈哈。
但是有一個問題,那就是當我們的數據量很大,大量的向數據庫寫入的時候,可能會導致數據庫出現異常,這時我們應該使用異步的方式向數據庫插入數據.下面我將使用異步插入的方式來重寫pipeline.
首先們將數據庫的配置文件寫入到settings.py中.
#MYSQL
MYSQL_HOST="127.0.0.1"
MYSQL_USER="root"
MYSQL_PWD="4rfv%TGB^"
MYSQL_DB="ttlsa_spider"
後面我們如果想使用settings.py文件裏定義的變量,可以在pipeline.py文件中的定義的類中使用from_settings(cls,settings)這個方法來獲取.
from twisted.enterprise import adbapi
class MysqlTwsitedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = {
‘host‘: settings["MYSQL_HOST"],
‘db‘: settings["MYSQL_DB"],
‘user‘: settings["MYSQL_USER"],
‘passwd‘: settings["MYSQL_PWD"],
‘charset‘: ‘utf8‘,
‘use_unicode‘: True
}
dbpool=adbapi.ConnectionPool("MySQLdb", cp_min=10, cp_max=20, **dbparms)
return cls(dbpool)
def process_item(self,item,spider):
"""
使用twisted將mysql插入變成異步執行
"""
query = self.dbpool.runInteraction(self.doInsert,item)
query.addErrback(self.handle_error,item,spider) #處理異步寫入錯誤
def handle_error(self,failurer,item,spider):
if failurer:
print(failurer)
def doInsert(self,cursor,item):
insert_sql = """
insert into article(title,url,url_object_id,comment_nums,praise_nums,tags,content,create_time,
front_img_url,front_img_path)
values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
cursor.execute(insert_sql, (item["title"], item["url"], item["url_object_id"], int(item["comment_nums"]),
int(item["praise_nums"]), item["tags"], item["content"], item["create_time"],
item["front_img_url"], item["front_img_path"]))
再將MysqlTwsitedPipeline類寫入到settings.py文件中.
ITEM_PIPELINES = {
‘ScrapyProject.pipelines.TtlsaImagesPipeline‘: 1,
#‘ScrapyProject.pipelines.JsonWithEncodingPipeline‘: 2,
‘ScrapyProject.pipelines.MysqlTwsitedPipeline‘: 3,
}
調試代碼.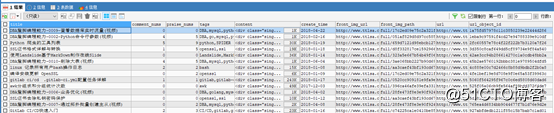
好了,數據又源源不斷的寫到數據庫中了.
再看下與數據庫連接的數目: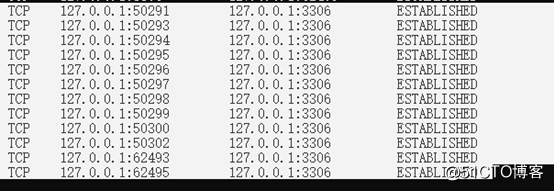
數了一下,有12個。也就是在連接池中的數量是由cp_min=10,cp_max=20定義的.
到此,數據便存儲到mysql中了.
如果想了解更多,請關註我們的公眾號
公眾號ID:opdevos
掃碼關註
用scrapy爬取ttlsa博文相關數據存儲至mysql