
情感分析之詞袋模型TF-IDF演算法(三)
在這篇文章中,主要介紹的內容有:
1、將單詞轉換為特徵向量
2、TF-IDF計算單詞關聯度
在之前的文章中,我們已經介紹過一些文字的預處理和分詞。這篇文章中,主要介紹如何將單詞等分類資料轉成為數值格式,以方便我們後面使用機器學習來訓練模型。
一、將單詞轉換為特徵向量
詞袋模型(bag-of-words model):將文字以數值特徵向量的形式來表示。主要通過兩個步驟來實現詞袋模型:
1、為整個文件集(包含了許多的文件)上的每個單詞建立一個唯一的標記。
2、為每個文件構建一個特徵向量,主要包含每個單詞在文件上的出現次數。
注意:由於每個文件中出現的單詞數量只是整個文件集中很少的一部分,因此會有很多的單詞沒有出現過,就會被標記為0。所以,特徵向量中大多數的元素就會為0,就會產生稀疏矩陣。
下面通過sklearn的CountVectorizer來實現一個詞袋模型,將文件轉換成為特徵向量
import numpy as np from sklearn.feature_extraction.text import CountVectorizer if __name__ == "__main__": count = CountVectorizer() #定義一個文件陣列 docs = np.array([ "The sun is shining", "The weather is sweet", "The sun is shining and the weather is sweet" ]) #建立詞袋模型的詞彙庫 bag = count.fit_transform(docs) #檢視詞彙的位置,詞彙是以字典的形式儲存 print(count.vocabulary_) #{'the': 5, 'sun': 3, 'is': 1, 'shining': 2, 'weather': 6, 'sweet': 4, 'and': 0} print(bag.toarray()) ''' [[0 1 1 1 0 1 0] [0 1 0 0 1 1 1] [1 2 1 1 1 2 1]] '''
通過count.vocabulary_我們可以看出每個單詞所對應的索引位置,每一個句子都是由一個6維的特徵向量所組成。其中,第一列的索引為0,對應單詞"and","and"在第一和二條句子中沒有出現過,所以為0,在第三條句子中出現過一些,所以為1。特徵向量中的值也被稱為原始詞頻(raw term frequency)簡寫為tf(t,d),表示在文件d中詞彙t的出現次數。
注意:在上面詞袋模型中,我們是使用單個的單詞來構建詞向量,這樣的序列被稱為1元組(1-gram)或單元組(unigram)模型。除了一元組以外,我們還可以構建n元組(n-gram)。n元組模型中的n取值與特定的應用場景有關,如在反垃圾郵件中,n的值為3或4的n元組可以獲得比較好的效果。下面舉例說明一下n元組,如在"the weather is sweet"這句話中,
1元組:"the"、"weather"、"is"、"sweet"。
2元組:"the weather"、"weather is"、"is sweet"。
在sklearn中,可以設定CountVecorizer中的ngram_range引數來構建不同的n元組模型,預設ngram_range=(1,1)。
sklearn通過CountVecorizer構建2元組
count = CountVectorizer(ngram_range=(2,2))
二、TF-IDF計算單詞關聯度
在使用上面的方法來構建詞向量的時候可能會遇到一個問題:一個單詞在不同型別的文件中都出現,這種型別的單詞其實是不具備文件型別的區分能力。我們通過TF-IDF演算法來構建詞向量,從而來克服這個問題。
詞頻-逆文件頻率(TF-IDF,term frequency-inverse document frequency):tf-idf可以定義為詞頻×逆文件頻率
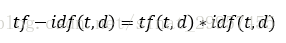
其中tf(t,d)表示單詞t在文件d中的出現次數,idf(t,d)為逆文件頻率,計算公式如下
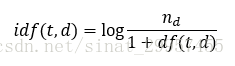
其中,nd表示文件的總數,df(t,d)表示包含單詞t的文件d的數量。分母中加入常數1,是為了防止df(t,d)=0的情況,導致分母為0。取log的目的是保證當df(t,d)很小的時候,不會導致idf(t,d)過大。
通過sklearn的TfidfTransformer和CountVectorizer來計算tf-idf
from sklearn.feature_extraction.text import TfidfTransformer
tfidf = TfidfTransformer()
#設定小數點的位數為2
np.set_printoptions(2)
#輸出tf-idf
print(tfidf.fit_transform(bag).toarray())

可以發現"is"(第二列)和"the"(第六列),它們在三個句子中都出現過,它們對於文件的分類所提供的資訊並不會很多,所以它們的tf-idf的值相對來說都是比較小的。
注意:sklearn中的TfidfTransformer的TF-IDF的計算與我們上面所定義TF-IDF的公式有所不同,sklearn的TF-IDF計算公式
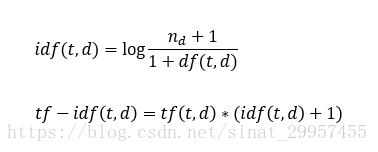
通常在計算TF-IDF之前,會對原始詞頻tf(t,d)做歸一化處理,TfidfTransformer是直接對tf-idf做歸一化。TfidfTransformer預設使用L2歸一化,它通過與一個未歸一化特徵向量L2範數的比值,使得返回向量的長度為1,計算公式如下:
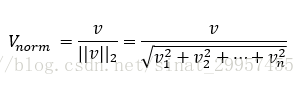
下面通過一個例子來說明sklearn中的TfidfTransformer的tf-idf的計算過程,以上面的第一句話"The sun is shining"為例子
a、單詞所對應的下標
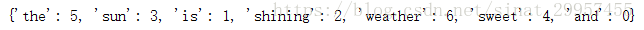
b、計算第三句話的原始詞頻tf(t,d)
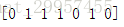
c、計算逆文件頻率idf(t,d)
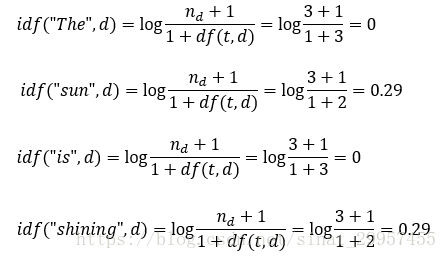
注意:其他的詞在計算tf-idf都是0,因為原始詞頻為0,所以就不需要計算idf了,log是以自然數e為底。
d、計算tf-idf
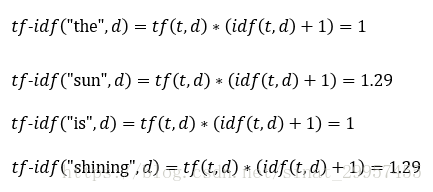
所以,第一個句子的tf-idf特徵向量為[0,1,1.29,1.29,0,1,0]
e、tf-idf的L2歸一化
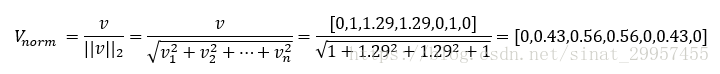
在下一篇文章中將介紹如何使用這些特徵向量來構建一個模型進行情感分類。