
文字特徵選擇——TF-IDF演算法(Python3實現)
1、TF-IDF演算法介紹
TF-IDF(term frequency–inverse document frequency,詞頻-逆向檔案頻率)是一種用於資訊檢索(information retrieval)與文字挖掘(text mining)的常用加權技術。
TF-IDF是一種統計方法,用以評估一字詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度。字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。
TF-IDF的主要思想是:如果某個單詞在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。
(1)TF是詞頻(Term Frequency)
詞頻(TF)表示詞條(關鍵字)在文字中出現的頻率。
這個數字通常會被歸一化(一般是詞頻除以文章總詞數), 以防止它偏向長的檔案。
公式: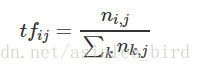

其中 ni,j 是該詞在檔案 dj 中出現的次數,分母則是檔案 dj 中所有詞彙出現的次數總和;
(2) IDF是逆向檔案頻率(Inverse Document Frequency)
逆向檔案頻率 (IDF) :某一特定詞語的IDF,可以由總檔案數目除以包含該詞語的檔案的數目,再將得到的商取對數得到
如果包含詞條t的文件越少, IDF越大,則說明詞條具有很好的類別區分能力。
公式: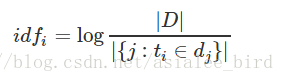
其中,|D| 是語料庫中的檔案總數。 |{j:ti∈dj}| 表示包含詞語 ti 的檔案數目(即 ni,j≠0 的檔案數目)。如果該詞語不在語料庫中,就會導致分母為零,因此一般情況下使用 1+|{j:ti∈dj}|
即:

(3)TF-IDF實際上是:TF * IDF
某一特定檔案內的高詞語頻率,以及該詞語在整個檔案集合中的低檔案頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。
公式:
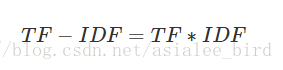
注: TF-IDF演算法非常容易理解,並且很容易實現,但是其簡單結構並沒有考慮詞語的語義資訊,無法處理一詞多義與一義多詞的情況。
2、TF-IDF應用
(1)搜尋引擎;(2)關鍵詞提取;(3)文字相似性;(4)文字摘要
3、Python3實現TF-IDF演算法
# -*- coding: utf-8 -*-
from collections import defaultdict
import math
import operator
"""
函式說明:建立資料樣本
Returns:
dataset - 實驗樣本切分的詞條
classVec - 類別標籤向量
"""
def loadDataSet():
dataset = [ ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的詞條
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid'] ]
classVec = [0, 1, 0, 1, 0, 1] # 類別標籤向量,1代表好,0代表不好
return dataset, classVec
"""
函式說明:特徵選擇TF-IDF演算法
Parameters:
list_words:詞列表
Returns:
dict_feature_select:特徵選擇詞字典
"""
def feature_select(list_words):
#總詞頻統計
doc_frequency=defaultdict(int)
for word_list in list_words:
for i in word_list:
doc_frequency[i]+=1
#計算每個詞的TF值
word_tf={} #儲存沒個詞的tf值
for i in doc_frequency:
word_tf[i]=doc_frequency[i]/sum(doc_frequency.values())
#計算每個詞的IDF值
doc_num=len(list_words)
word_idf={} #儲存每個詞的idf值
word_doc=defaultdict(int) #儲存包含該詞的文件數
for i in doc_frequency:
for j in list_words:
if i in j:
word_doc[i]+=1
for i in doc_frequency:
word_idf[i]=math.log(doc_num/(word_doc[i]+1))
#計算每個詞的TF*IDF的值
word_tf_idf={}
for i in doc_frequency:
word_tf_idf[i]=word_tf[i]*word_idf[i]
# 對字典按值由大到小排序
dict_feature_select=sorted(word_tf_idf.items(),key=operator.itemgetter(1),reverse=True)
return dict_feature_select
if __name__=='__main__':
data_list,label_list=loadDataSet() #載入資料
features=feature_select(data_list) #所有詞的TF-IDF值
print(features)
print(len(features))
執行結果:

相關推薦
文字特徵選擇——TF-IDF演算法(Python3實現)
1、TF-IDF演算法介紹 TF-IDF(term frequency–inverse document frequency,詞頻-逆向檔案頻率)是一種用於資訊檢索(information retrieval)與文字挖掘(text mining)的常用加權技術
情感分析之詞袋模型TF-IDF演算法(三)
在這篇文章中,主要介紹的內容有:1、將單詞轉換為特徵向量2、TF-IDF計算單詞關聯度在之前的文章中,我們已經介紹過一些文字的預處理和分詞。這篇文章中,主要介紹如何將單詞等分類資料轉成為數值格式,以方便我們後面使用機器學習來訓練模型。一、將單詞轉換為特徵向量詞袋模型(bag-
文字特徵選擇的關鍵演算法總結
一、特徵詞選擇與特徵詞權重關係 開始學文字分類的時候經常要搞暈特徵詞選擇和特徵詞權重 這兩個東西,因為兩者都要進行量化,很容易認為特徵詞選擇就是計算權重,因此我認為有必要先搞清楚這兩個概念。 兩者的區別 :特徵詞選擇是為了降低文字表示的維度,而特徵詞權重是為
演算法題5:Excel表列序號(python3實現)
給定一個Excel表格中的列名稱,返回其相應的列序號。 例如, A -> 1 B -> 2 C -> 3 ... Z -> 26 AA -> 27 AB -> 28 ... 示例 1:
演算法題4:迴文數(python3實現)
判斷一個整數是否是迴文數。迴文數是指正序(從左向右)和倒序(從右向左)讀都是一樣的整數。 示例 1: 輸入: 121 輸出: true 示例 2: 輸入: -121 輸出: false 解釋: 從左向右讀, 為 -121 。 從右向左讀, 為 121- 。因此它不是一個迴
演算法題3:兩數之和(python3實現)
給定一個整數陣列和一個目標值,找出陣列中和為目標值的兩個數。 你可以假設每個輸入只對應一種答案,且同樣的元素不能被重複利用。 示例: 給定 nums = [2, 7, 11, 15], target = 9 因為 nums[0] + nums[1] = 2 + 7 = 9 所以返回 [
演算法題2:最長公共字首(python3實現)
編寫一個函式來查詢字串陣列中的最長公共字首。 如果不存在公共字首,返回空字串 ""。 示例 1: 輸入: ["flower","flow","flight"] 輸出: "fl" 示例 2: 輸入: ["dog","racecar","car"] 輸
演算法題1:反轉整數 (python3實現)
給定一個 32 位有符號整數,將整數中的數字進行反轉。 示例 1: 輸入: 123 輸出: 321 示例 2: 輸入: -123 輸出: -321 示例 3: 輸入: 120 輸出: 21 注意: 假設我們的環境只能儲存 32 位有符號整數
特徵選擇——Matrix Projection演算法研究與實現
內容提要 引言 MP特徵選擇思想 MP特徵選擇演算法 MP特徵選擇分析 實驗結果 分析總結 引言 一般選擇文字的片語作為分類器輸入向量的特徵語義單元,而作為單詞或詞語的片語,在任何一種語言中都有數萬或數十萬個。另外
TF-IDF演算法及其程式設計實現
我們很容易發現,如果一個關鍵詞只在很少的網頁中出現,我們通過它就容易鎖定搜尋目標,它的權重也就應該大。反之如果一個詞在大量網頁中出現,我們看到它仍然不很清楚要找什麼內容,因此它應該小。概括地講,假定一個關鍵詞 w 在 Dw 個網頁中出現過,那麼 Dw 越大,w的權重越小,反之亦然。在資訊檢索中,使用最多的
決策樹演算法——熵與資訊增益(Python3實現)
1、熵、條件熵與資訊增益 (1)熵(entropy) (2)條件熵(conditional entropy) (3)資訊增益(information gain) 2、資訊增益演算法實現流程 2、資料集以及每個特徵資訊增益的計算
select默認選中項顏色為灰色,選擇後變為黑色(js實現)
pre var select ted col item first round fin <script> var unSelected = "#999"; var selected = "#333"; $(function () {
機器學習實戰筆記(python3實現)01--概述
apriori 一個 python 系列 k-均值聚類 思路 機器學習實戰 st算法 apr 寫在前面:這一個多月都在學習python,從python3基礎、python爬蟲、python數據挖掘與數據分析都有接觸,最近看到一本機器學習的書(主要是學習相關算法) 於是就打算
對稱矩陣與壓縮儲存演算法(java實現)
一、問題描述 實現一個對稱矩陣的壓縮儲存 二、演算法分析 對稱矩陣的特點:a[i][j] = a[j][i].即所有元素關於對角線對稱 所以可以將對稱矩陣的下三角儲存在一個數組物件SA中,儲存方式是, SA[0] = a[0][0] SA[1] = a[1][0]
一種較為高效的TreeList生成演算法(Delphi實現)
記得不久前曾寫過篇關於TreeList生成的文章。雖然那個演算法裡,我已經有對葉節點做判斷,避免無用的Filter操作。但是非葉節點的Filter操作依然是無可避免的。而Filter又是影響整個生成的最重要因素,因此當帶子節點的節點很多時,速度還是要被拖下去的。 後來我看到了一種覺得不錯的思路,
二叉樹的遍歷演算法(js實現)
之前我的部落格中講到了如何通過js去實現一顆二叉樹,有興趣的可以去我的部落格中看下。今天我們來一起實現下二叉樹的遍歷演算法。歡迎大家幫忙指出不當之處,或者進行深入的挖掘。大家一起進步。二叉樹吶,有三種遍歷演算法,1:中序遍歷,2:先序遍歷,3:後序遍歷。在我們看具體實現之前,我們想下為什麼要這樣做?二叉樹廣泛
LeetCode加一演算法(JS實現)
給定一個由整陣列成的非空陣列所表示的非負整數,在該數的基礎上加一。 最高位數字存放在陣列的首位, 陣列中每個元素只儲存一個數字。 你可以假設除了整數 0 之外,這個整數不會以零開頭。 示例 1: 輸入: [1,2,3] 輸出: [1,2,4] 解釋: 輸入陣列表示數字 1
通過手動新增id從雲音樂介面一鍵下載音樂(Python3實現)
首先,談論下思路和準備工作。 思路是,先去網易雲音樂平臺試試水,看看各大音樂庫是否“有機可乘”。當然這過程是用谷歌Network監控瀏覽器與伺服器互動請求,如下圖: 結果發現,果然是大廠,竟然把相關的有歌曲重要資訊的json都給遮蔽了。 可以看到裡面
實現奇偶數排序演算法(JAVA實現)
給定一個整數陣列,請調整陣列的順序,使得所有奇數位於陣列前半部分,所有偶數位於陣列後半部分,時間複雜度越小越好。 package com.sort; import java.util.Arrays; public class TestSort { /** * 測試方法 * @par