
spark高階資料分析系列之第三章音樂推薦和 Audioscrobbler 資料集
3.1資料集和整體思路
資料集
本章實現的是歌曲推薦,使用的是ALS演算法,ALS是spark.mllib中唯一的推薦演算法,因為只有ALS演算法可以進行並行運算。
使用資料集在這裡,裡面包含該三個檔案:表一:user_artist_data.txt 包含該的是(使用者ID、歌曲ID、使用者聽的次數)
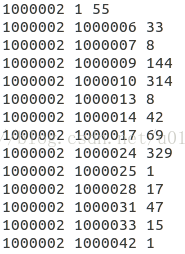
表二:artist_data.txt 這個檔案包含的是(歌曲ID,歌曲名字)
表三:artist_alias.txt 輸入錯誤,或者不同某種原因,同一首歌曲可能具有不同ID,這個是歌曲勘誤表(bad_id, good_id)

程式結構
第一步:對資料進行資料清理
ALS要求輸入的資料格式是(使用者、產品、值),在本實驗中就是(使用者ID、歌曲ID、播放次數),也就是第一個檔案user_artist_data.txt中的資料,但由於輸入錯誤或者別的原因同一首歌曲有多個ID號,需要把一首歌曲的不同ID合併成一個ID(通過第三個檔案artist_alias.txt)。表三artist_alias.txt檔案中第一列是歌曲錯誤的ID,第二列是真正的ID,所以在把表一的歌曲ID通過表三來修正。同時表一中存在資料缺失,需要進行缺失處理。最後把資料結構化為(使用者ID、歌曲ID、播放次數)
第二步:把資料傳給ALS進行訓練,並進行預測
ALS接收到的資料(使用者ID、歌曲ID、播放次數)轉換為表格形式:
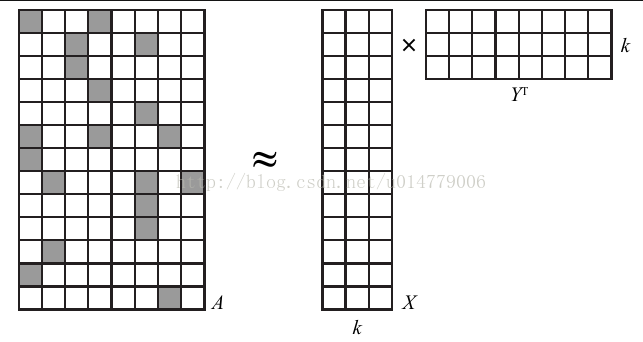
每一行代表一個使用者,每一列代表代表一首歌曲,表格資料是使用者播放次數。由於一個使用者所聽的歌曲很有限,所以該表格是一個稀疏矩陣。ALS的做法是,把該矩陣轉化為兩個矩陣的相乘
X矩陣是(使用者ID-特徵)矩陣,k值可以自己給定。Y矩陣是(歌曲ID-特徵)矩陣,k值可以自己給定。這樣處理就可以把稀疏矩陣轉換為兩個矩陣,k代表著特徵個數,本節使用的是10。
現在的問題是如何得到這兩個矩陣X和Y,使用的是交替最小二乘推薦演算法。基本思想是:要同時確定XY很難,但如果確定一個X,求Y是很簡單的。所以就隨機給定一個Y,求得最佳X,再反過來求最佳Y,不斷重複。隨機確定矩陣Y之後,就可以在給定 A 和 Y 的條件下求出 X 的最優解。
實際上 X 的每一行可以分開計算,所以我們可以將其並行化,而並行化是大規模計算的一大優點。
要想兩邊精確相等是不可能的,因此實際的目標是最小化,但實際中是不會求矩陣的逆,是通過QR分解之類的方法求得。


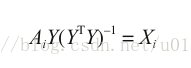
3.2程式走讀
準備資料
為了保證記憶體充足,在啟動 spark-shell 時需求指定引數 --driver-memory 6g。
讀取資料
val rawUserArtistData =sc.textFile("/home/sam/下載/profiledata_06-May-2005/user_artist_data.txt") val rawArtistData =sc.textFile("/home/sam/下載/profiledata_06-May-2005/artist_data.txt") val rawArtistAlias =sc.textFile("/home/sam/下載/profiledata_06-May-2005/artist_alias.txt")ALS 演算法實現有一個小缺點:它要求使用者和產品的 ID 必須是數值型,並且是 32 位非負整數,需要對資料進行範圍檢查,得到最大值是 2443548 和 10794401,滿足要求
rawUserArtistData.map(_.split(' ')(0).toDouble).stats() //stats方法會返回每一列的最大值,最小值,均值、方差、總數等 rawUserArtistData.map(_.split(' ')(1).toDouble).stats()資料的缺失值處理,把空值和異常值用None代替
val artistByID = rawArtistData.flatMap { line => val (id, name) = line.span(_ != '\t') if (name.isEmpty) { None } else { try { Some((id.toInt, name.trim)) } catch { case e: NumberFormatException => None } } }把空值用None代替,同事把字串型別轉為int
val artistAlias = rawArtistAlias.flatMap{ line => val tokens = line.split('\t') if (tokens(0).isEmpty) { None } else { Some((tokens(0).toInt, tokens(1).toInt)) } }.collectAsMap()構建模型
把相關的依賴包匯入
把表三的(bad_id,good_id)作為廣播變數,廣播變數會緩衝到每臺機器中,而不是每個任務中(每臺機器中有多個任務)。因為每個任務都需要訪問artistAlias,如果直接就傳遞過去,每個任務中都儲存一份副本,會增加儲存容量。Spark還使用高效的廣播演算法來分發變數,進而減少通訊的開銷。
然後把表一資料轉換為ALS模型需要的rating型別資料,同時把歌曲ID和表三對照更改歌曲ID。
import org.apache.spark.mllib.recommendation._ val bArtistAlias = sc.broadcast(artistAlias) //整合訓練資料 val trainData = rawUserArtistData.map { line => val Array(userID, artistID, count) = line.split(' ').map(_.toInt) val finalArtistID = bArtistAlias.value.getOrElse(artistID, artistID) //把bad_id替換成good_id Rating(userID, finalArtistID, count) }.cache()
搭建模型模型的引數含義val model = ALS.trainImplicit(trainData, 10, 5, 0.01, 1.0)• rank = 10
模型的潛在因素的個數k,即“使用者 - 特徵”和“產品 - 特徵”矩陣的列數;一般來說,它也是矩陣的階。
• iterations = 5
矩陣分解迭代的次數;迭代的次數越多,花費的時間越長,但分解的結果可能會更好。
• lambda = 0.01
標準的過擬合引數;值越大越不容易產生過擬合,但值太大會降低分解的準確度。
• alpha = 1.0
控制矩陣分解時,被觀察到的“使用者 - 產品”互動相對沒被觀察到的互動的權重。
檢視結果
首先檢視使用者2093760所聽過的歌曲
val rawArtistsForUser = rawUserArtistData.map(_.split(' ')). filter { case Array(user,_,_) => user.toInt == 2093760 } //找出ID為2093760的資料 val existingProducts =rawArtistsForUser.map { //把歌曲的ID號轉為int型 case Array(_,artist,_) => artist.toInt }.collect().toSet artistByID.filter { case (id, name) => //根據表二列印歌曲名 existingProducts.contains(id) }.values.collect().foreach(println)利用剛剛訓練好的模型給2093760使用者推薦5首歌曲
val recommendations = model.recommendProducts(2093760, 5)
輸出結果是Rating(2093760,1300642,0.02833118412903932)
Rating(2093760,2814,0.027832682960168387)
Rating(2093760,1037970,0.02726611004625264)
Rating(2093760,1001819,0.02716011293509426)
Rating(2093760,4605,0.027118271894797333)
結果中最後的得分並不是概率,分數越高代表使用者越喜歡。然後把歌曲ID轉為所對應的歌曲名並列印
artistByID.filter { case (id, name) => recommendedProductIDs.contains(id) }.values.collect().foreach(println)
輸出結果是Green Day
Linkin Park
Metallica
My Chemical Romance
System of a Down
模型的評估
模型的評估主要是通過AUC曲線來反映,AUC的具體內容這裡就不介紹了。
先把資料集劃分為訓練資料和測試資料
訓練模型val Array(trainData, cvData) = allData.randomSplit(Array(0.9, 0.1))評估模型val allItemIDs = allData.map(_.product).distinct().collect() val bAllItemIDs = sc.broadcast(allItemIDs) val model = ALS.trainImplicit(trainData, 10, 5, 0.01, 1.0)val auc = areaUnderCurve(cvData, bAllItemIDs, model.predict) //該函式附錄中給出附錄:
def areaUnderCurve( positiveData: DataFrame, bAllArtistIDs: Broadcast[Array[Int]], predictFunction: (DataFrame => DataFrame)): Double = { // What this actually computes is AUC, per user. The result is actually something // that might be called "mean AUC". // Take held-out data as the "positive". // Make predictions for each of them, including a numeric score val positivePredictions = predictFunction(positiveData.select("user", "artist")). withColumnRenamed("prediction", "positivePrediction") // BinaryClassificationMetrics.areaUnderROC is not used here since there are really lots of // small AUC problems, and it would be inefficient, when a direct computation is available. // Create a set of "negative" products for each user. These are randomly chosen // from among all of the other artists, excluding those that are "positive" for the user. val negativeData = positiveData.select("user", "artist").as[(Int,Int)]. groupByKey { case (user, _) => user }. flatMapGroups { case (userID, userIDAndPosArtistIDs) => val random = new Random() val posItemIDSet = userIDAndPosArtistIDs.map { case (_, artist) => artist }.toSet val negative = new ArrayBuffer[Int]() val allArtistIDs = bAllArtistIDs.value var i = 0 // Make at most one pass over all artists to avoid an infinite loop. // Also stop when number of negative equals positive set size while (i < allArtistIDs.length && negative.size < posItemIDSet.size) { val artistID = allArtistIDs(random.nextInt(allArtistIDs.length)) // Only add new distinct IDs if (!posItemIDSet.contains(artistID)) { negative += artistID } i += 1 } // Return the set with user ID added back negative.map(artistID => (userID, artistID)) }.toDF("user", "artist") // Make predictions on the rest: val negativePredictions = predictFunction(negativeData). withColumnRenamed("prediction", "negativePrediction") // Join positive predictions to negative predictions by user, only. // This will result in a row for every possible pairing of positive and negative // predictions within each user. val joinedPredictions = positivePredictions.join(negativePredictions, "user"). select("user", "positivePrediction", "negativePrediction").cache() // Count the number of pairs per user val allCounts = joinedPredictions. groupBy("user").agg(count(lit("1")).as("total")). select("user", "total") // Count the number of correctly ordered pairs per user val correctCounts = joinedPredictions. filter($"positivePrediction" > $"negativePrediction"). groupBy("user").agg(count("user").as("correct")). select("user", "correct") // Combine these, compute their ratio, and average over all users val meanAUC = allCounts.join(correctCounts, "user"). select($"user", ($"correct" / $"total").as("auc")). agg(mean("auc")). as[Double].first() joinedPredictions.unpersist() meanAUC }