使用Keras進行深度學習:(一)Keras 入門
Keras是Python中以CNTK、Tensorflow或者Theano為計算後臺的一個深度學習建模環境。相對於其他深度學習的計算軟體,如:Tensorflow、Theano、Caffe等,Keras在實際應用中有一些顯著的優點,其中最主要的優點就是Keras已經高度模組化了,支援現有的常見模型(CNN、RNN等),更重要的是建模過程相當方便快速,加快了開發速度。
筆者使用的是基於Tensorflow為計算後臺。接下來將介紹一些建模過程的常用層、搭建模型和訓練過程,而Keras中的文字、序列和影象資料預處理,我們將在相應的實踐專案中進行講解。
1.核心層(各層函式只介紹一些常用引數,詳細引數介紹可查閱Keras文件)
1.1全連線層:神經網路中最常用到的,實現對神經網路裡的神經元啟用。
Dense(units, activation=’relu’, use_bias=True)
引數說明:
units: 全連線層輸出的維度,即下一層神經元的個數。
activation:啟用函式,預設使用Relu。
use_bias:是否使用bias偏置項。
1.2啟用層:對上一層的輸出應用啟用函式。
Activation(activation)
引數說明:
Activation:想要使用的啟用函式,如:’relu’、’tanh’、‘sigmoid’等。
1.3Dropout層:對上一層的神經元隨機選取一定比例的失活,不更新,但是權重仍然保留,防止過擬合。
Dropout(rate)
引數說明:
rate:失活的比例,0-1的浮點數。
1.4Flatten層:將一個維度大於或等於3的高維矩陣,“壓扁”為一個二維矩陣。即保留第一個維度(如:batch的個數),然後將剩下維度的值相乘作為“壓扁”矩陣的第二個維度。
Flatten()
1.5Reshape層:該層的作用和reshape一樣,就是將輸入的維度重構成特定的shape。
Reshape(target_shape)
引數說明:
target_shape:目標矩陣的維度,不包含batch樣本數。
如我們想要一個9個元素的輸入向量重構成一個(None, 3, 3)的二維矩陣:
Reshape((3,3), input_length=(16, ))
1.6卷積層:卷積操作分為一維、二維、三維,分別為Conv1D、Conv2D、Conv3D。一維卷積主要應用於以時間序列資料或文字資料,二維卷積通常應用於影象資料。由於這三種的使用和引數都基本相同,所以主要以處理影象資料的Conv2D進行說明。
Conv2D(filters, kernel_size, strides=(1, 1), padding=’valid’)
引數說明:
filters:卷積核的個數。
kernel_size:卷積核的大小。
strdes:步長,二維中預設為(1, 1),一維預設為1。
Padding:補“0”策略,’valid‘指卷積後的大小與原來的大小可以不同,’same‘則卷積後大小與原來大小一致。
1.7池化層:與卷積層一樣,最大統計量池化和平均統計量池化也有三種,分別為MaxPooling1D、MaxPooling2D、MaxPooling3D和AveragePooling1D、AveragePooling2D、AveragePooling3D,由於使用和引數基本相同,所以主要以MaxPooling2D進行說明。
MaxPooling(pool_size=(2,2), strides=None, padding=’valid’)
引數說明:
pool_size:長度為2的整數tuple,表示在橫向和縱向的下采樣樣子,一維則為縱向的下采樣因子。
padding:和卷積層的padding一樣。
1.8迴圈層:迴圈神經網路中的RNN、LSTM和GRU都繼承本層,所以該父類的引數同樣使用於對應的子類SimpleRNN、LSTM和GRU。
Recurrent(return_sequences=False)
return_sequences:控制返回的型別,“False”返回輸出序列的最後一個輸出,“True”則返回整個序列。當我們要搭建多層神經網路(如深層LSTM)時,若不是最後一層,則需要將該引數設為True。
1.9嵌入層:該層只能用在模型的第一層,是將所有索引標號的稀疏矩陣對映到緻密的低維矩陣。如我們對文字資料進行處理時,我們對每個詞編號後,我們希望將詞編號變成詞向量就可以使用嵌入層。
Embedding(input_dim, output_dim, input_length)
引數說明:
Input_dim:大於或等於0的整數,字典的長度即輸入資料的個數。
output_dim:輸出的維度,如詞向量的維度。
input_length:當輸入序列的長度為固定時為該長度,然後要在該層後加上Flatten層,然後再加上Dense層,則必須指定該引數,否則Dense層無法自動推斷輸出的維度。
該層可能有點費解,舉個例子,當我們有一個文字,該文字有100句話,我們已經通過一系列操作,使得文字變成一個(100,32)矩陣,每行代表一句話,每個元素代表一個詞,我們希望將該詞變為64維的詞向量:
Embedding(100, 64, input_length=32)
則輸出的矩陣的shape變為(100, 32, 64):即每個詞已經變成一個64維的詞向量。
2.Keras模型搭建
講完了一些常用層的語法後,通過模型搭建來說明Keras的方便性。Keras中設定了兩類深度學習的模型,一類是序列模型(Sequential類);一類是通用模型(Model類),接下來我們通過搭建下圖模型進行講解。
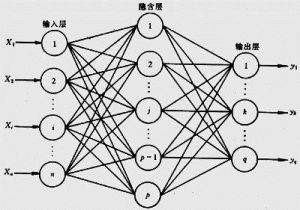
假設我們有一個兩層神經網路,其中輸入層為784個神經元,隱藏層為32個神經元,輸出層為10個神經元,隱藏層使用relu啟用函式,輸出層使用softmax啟用函式。分別使用序列模型和通用模型實現如下:


使用序列模型,首先我們要例項化Sequential類,之後就是使用該類的add函式加入我們想要的每一層,從而實現我們的模型。

使用通用模型,首先要使用Input函式將輸入轉化為一個tensor,然後將每一層用變數儲存後,作為下一層的引數,最後使用Model類將輸入和輸出作為引數即可搭建模型。
從以上兩類模型的簡單搭建,都可以發現Keras在搭建模型比起Tensorflow等簡單太多了,如Tensorflow需要定義每一層的權重矩陣,輸入用佔位符等,這些在Keras中都不需要,我們只要在第一層定義輸入維度,其他層定義輸出維度就可以搭建起模型,通俗易懂,方便高效,這是Keras的一個顯著的優勢。
3.模型優化和訓練
3.1compile(optimizer, loss, metrics=None)
引數說明:
optimizer:優化器,如:’SGD‘,’Adam‘等。
loss:定義模型的損失函式,如:’mse’,’mae‘等。
metric:模型的評價指標,如:’accuracy‘等。
3.2fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, validation_split=0.0)
引數說明:
x:輸入資料。
y:標籤。
batch_size:梯度下降時每個batch包含的樣本數。
epochs:整數,所有樣本的訓練次數。
verbose:日誌顯示,0為不顯示,1為顯示進度條記錄,2為每個epochs輸出一行記錄。
validation_split:0-1的浮點數,切割輸入資料的一定比例作為驗證集。

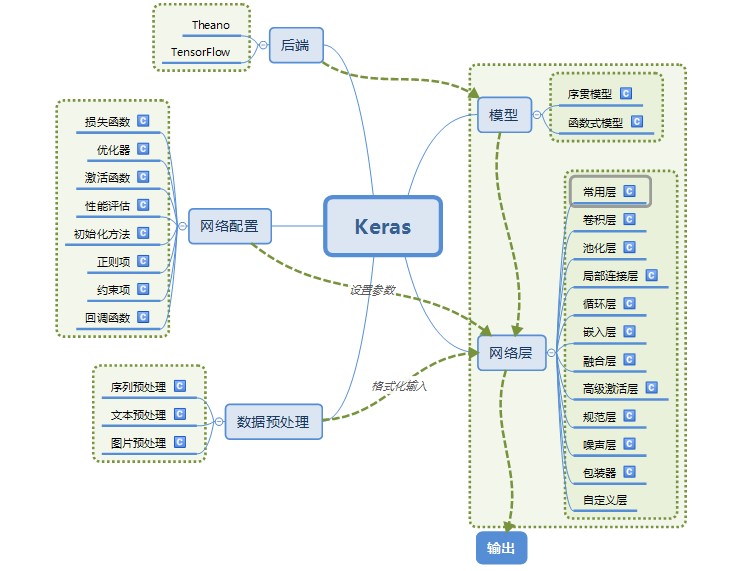
最後用以下圖片總結keras的模組,下一篇文章我們將會使用keras來進行專案實踐,從而更好的體會Keras的魅力。