
多層感知機-印第安人糖尿病診斷-基於keras的python學習筆記(一)
阿新 • • 發佈:2019-01-14
版權宣告:本文為博主原創文章,未經博主允許不得轉載。https://blog.csdn.net/weixin_44474718/article/details/86219792
函式解釋
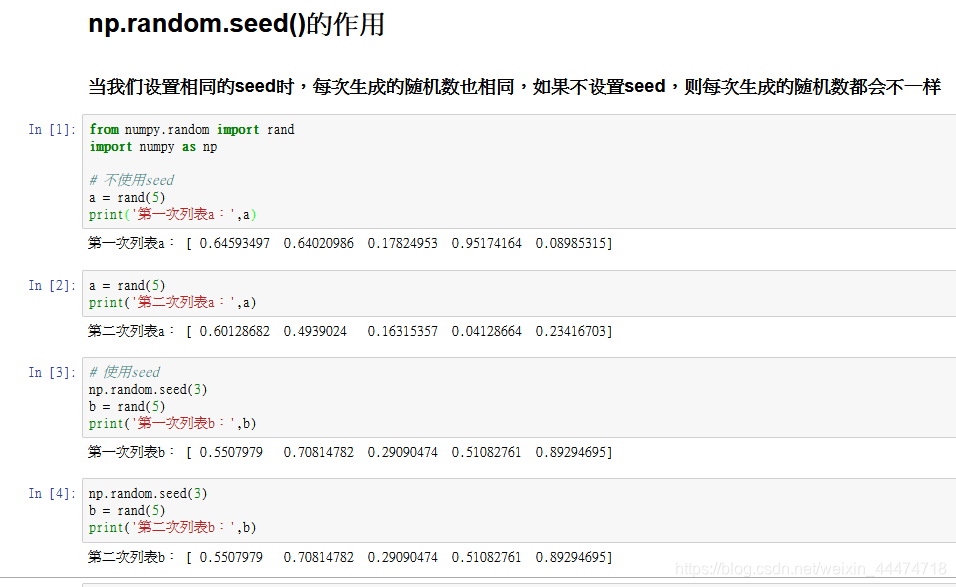
np.random.seed()函式,每次執行程式碼時設定相同的seed,則每次生成的隨機數也相同,如果不設定seed,則每次生成的隨機數都會不一樣。例如:
本例子:
資料集為8個屬性和輸出結果一共9列,為二分類問題(糖尿病為1或非糖尿病為0)
輸出層(1個輸出)
隱藏層(8個神經元)
隱藏層(12個神經元)
可視層(8個輸入)
from keras.models import Sequential
from 啟用函式:
sigmoid: 一般用於二分類
sgn: 單層神經網路
relu:多層神經網路,更容易收斂,預測效果好