
如何實現基於內容和使用者畫像的個性化推薦
阿新 • • 發佈:2019-01-07
基於內容和使用者畫像的個性化推薦,有兩個實體:內容和使用者。需要有一個聯絡這兩者的東西,即為標籤。內容轉換為標籤即為內容特徵化,使用者則稱為使用者特徵化。

因此,對於此種推薦,主要分為以下幾個關鍵部分:
- 標籤庫
- 內容特徵化
- 使用者特徵化
- 隱語義推薦
綜合上面講述的各個部分即可實現一個基於內容和使用者畫像的個性化推薦系統。如下圖所示:
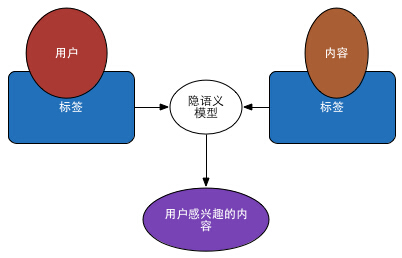
標籤庫
標籤是聯絡使用者與物品、內容以及物品、內容之間的紐帶,也是反應使用者興趣的重要資料來源。標籤庫的最終用途在於對使用者進行行為、屬性標記。是將其他實體轉換為計算機可以理解的語言關鍵的一步。
標籤庫則是對標籤進行聚合的系統,包括對標籤的管理、更新等。
一般來說,標籤是以層級的形式組織的。可以有一級維度、二級維度等。
標籤的來源主要有:
- 已有內容的標籤
- 網路抓取流行標籤
- 對運營的內容進行關鍵詞提取
對於內容的關鍵詞提取,使用結巴分詞 + TFIDF即可。此外,也可以使用TextRank來提取內容關鍵詞。
內容特徵化
內容特徵化即給內容打標籤。目前有兩種方式:
- 人工打標籤
- 機器自動打標籤
針對機器自動打標籤,需要採取機器學習的相關演算法來實現,即針對一系列給定的標籤,給內容選取其中匹配度最高的幾個標籤。這不同於通常的分類和聚類演算法。可以採取使用分詞 + Word2Vec來實現,過程如下:
-
將文字語料進行分詞,以空格,tab隔開都可以,使用結巴分詞。
- 使用word2vec訓練詞的相似度模型。
- 使用tfidf提取內容的關鍵詞A,B,C。
- 遍歷每一個標籤,計算關鍵詞與此標籤的相似度之和。
- 取出TopN相似度最高的標籤即為此內容的標籤。(N這裡取3)
使用者特徵化
使用者特徵化即為使用者打標籤。通過使用者的行為日誌和一定的模型演算法得到使用者的每個標籤的權重。
- 使用者對內容的行為:點選、不敢興趣、瀏覽
- 對內容發生的行為可以認為對此內容所帶的標籤的行為
- 使用者的興趣是時間衰減的,即離當前時間越遠的興趣比重越低。時間衰減函式使用1/[log(t)+1], t為事件發生的時間距離當前時間的大小
- 要考慮到熱門內容會干預使用者的標籤,需要對熱門內容進行降權。使用click/pv來降低熱門內容的權重
隱語義推薦
有了內容特徵和使用者特徵,可以使用隱語義模型進行推薦。這裡可以使用其簡化形式,以達到實時計算的目的。
使用者對於某一個內容的興趣度(可以認為是CTR):

其中i=1…N是內容具有的標籤,m(ci)指的內容c和標籤i的關聯度(目前都為1),n(ui)指的是使用者u的標籤i的權重值,q©指的是內容c的質量,暫時使用點選率表示。