
Caffe學習系列(1): 繪製網路模型
1、安裝必要的庫。
$ sudo apt-get install GraphViz
$ sudo pip install pydot
2、繪製網路
引數說明:
draw_net.py執行的時候帶三個引數
第一個引數:網路模型的prototxt檔案
第二個引數:儲存的圖片路徑及名字
第二個引數:–rankdir=x , x 有四種選項,分別是LR, RL, TB, BT 。用來表示網路的方向,分別是從左到右,從右到左,從上到小,從下到上。預設為LR。
例子:
$sudo python python/draw_net.py examples/mnist/lenet_train_test.prototxt net.png --rankdir=BT
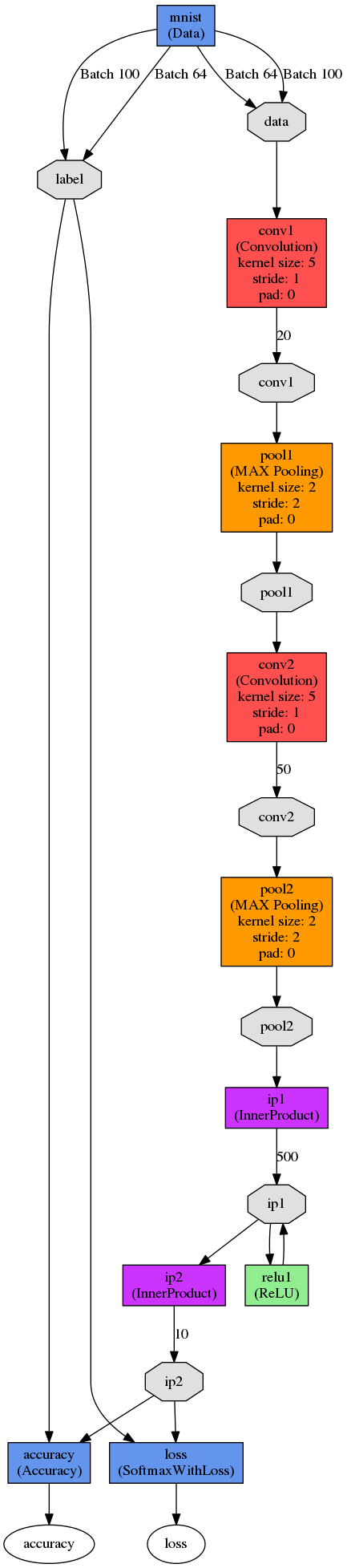
3、繪製自己的網路模型
未完待續。。。
相關推薦
Caffe學習系列(1): 繪製網路模型
1、安裝必要的庫。 $ sudo apt-get install GraphViz $ sudo pip install pydot 2、繪製網路 引數說明: draw_net.py執行的時候帶三個引數 第一個引數:網路模型的prototxt
Caffe學習系列(1):安裝配置ubuntu14.04+cuda7.5+caffe+cudnn
一、版本 linux系統:Ubuntu 14.04 (64位) 顯示卡:Nvidia K20c cuda: cuda_7.5.18_linux.run cudnn: cudnn-7.0-linux-x64-v4.0-rc 二、下載 Ubuntu 14.04下載地址:http://www.ubunt
Caffe學習系列——工具篇:神經網路模型結構視覺化
在Caffe中,目前有兩種視覺化prototxt格式網路結構的方法: 使用Netscope線上視覺化 使用Caffe提供的draw_net.py 本文將就這兩種方法加以介紹 1. Netscope:支援Caf
Caffe學習筆記1:linux下建立自己的資料庫訓練和測試caffe中已有網路
本文是基於薛開宇 《學習筆記3:基於自己的資料訓練和測試“caffeNet”》基礎上,從頭到尾把實驗跑了一遍~對該文中不清楚的地方做了更正和說明。 主要工作如下: 1、下載圖片建立資料庫 2、將圖片轉化為256*256的lmdb格式 3、計算影象均值 4、定義網路修改部分引
Caffe學習系列:模型各層資料和引數視覺化
從輸入的結果和圖示來看,最大的概率是7.17785358e-01,屬於第5類(標號從0開始)。與cifar10中的10種類型名稱進行對比: airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck 根據測試結果,判斷為dog。 測試無誤!
caffe之繪製網路模型
在Caffe中,目前有兩種視覺化prototxt格式網路結構的方法: 1. 使用Netscope線上視覺化 2. 使用Caffe提供的draw_net.py 1. 使用Netscope線上視覺化 使用方法:首先開啟這個地址:http://ethereon.github.io/netscope/#/e
Mybatis學習系列(1) –– 入門簡介
connector ring cti 行操作 底層 數據庫連接 lean lose style MyBatis簡介 Mybatis是Apache的一個Java開開源項目,是一個支持動態Sql語句的持久層框架。Mybatis可以將Sql語句配置在XML文件中,避免將Sql語
Jmeter學習系列----1 環境搭建
注:在安裝Jmeter之前,請先檢查下電腦有沒有裝JDK:開始->執行->然後輸入cmd->進入命令列介面,輸入java -version , 出現以下資訊就是此電腦已安裝了JDK。 下載Jmeter 下載地址:http://jmeter.apache.org/download_jm
Git學習系列1 安裝
一 Git是什麼? Git是目前世界上最先進的分散式版本控制系統。 二 安裝 1 Linux 如果你想在 Linux 上用二進位制安裝程式來安裝 Git,可以使用發行版包含的基礎軟體包管理工具來安裝。 Git官網地址 2 Mac 最簡單的方法是在Xc
【14】Caffe學習系列:計算圖片資料的均值
圖片減去均值後,再進行訓練和測試,會提高速度和精度。因此,一般在各種模型中都會有這個操作。 那麼這個均值怎麼來的呢,實際上就是計算所有訓練樣本的平均值,計算出來後,儲存為一個均值檔案,在以後的測試中,就可以直接使用這個均值來相減,而不需要對測試圖片重新計算。 一、二進位制格式的均值計算
【13】Caffe學習系列:資料視覺化環境(python介面)配置
caffe程式是由c++語言寫的,本身是不帶資料視覺化功能的。只能藉助其它的庫或介面,如opencv, python或matlab。更多人會使用python介面來進行視覺化,因為python出了個比較強大的東西:ipython notebook, 現在的最新版本改名叫jupyter notebook
【12】Caffe學習系列:訓練和測試自己的圖片
一、準備資料 有條件的同學,可以去imagenet的官網http://www.image-net.org/download-images,下載imagenet圖片來訓練。驗證碼始終出不來需要翻牆(是google網站的驗證碼)。但是我沒有下載,原因是資料太大了。。。 我去網上找了一些其它的圖片
【11】Caffe學習系列:影象資料轉換成db(leveldb/lmdb)檔案
在深度學習的實際應用中,我們經常用到的原始資料是圖片檔案,如jpg,jpeg,png,tif等格式的,而且有可能圖片的大小還不一致。而在caffe中經常使用的資料型別是lmdb或leveldb,因此就產生了這樣的一個問題:如何從原始圖片檔案轉換成caffe中能夠執行的db(leveldb/lmdb)
【10】Caffe學習系列:命令列解析
caffe的執行提供三種介面:c++介面(命令列)、python介面和matlab介面。本文先對命令列進行解析,後續會依次介紹其它兩個介面。其實大部分情況下我們會使用python介面進行呼叫,當然caffe提供了C++命令列介面,還是有必要了解一下。命令列引數有個優點是支援多GPU執行。 caf
【9】Caffe學習系列:執行caffe自帶的兩個簡單例子
為了程式的簡潔,在caffe中是不帶練習資料的,因此需要自己去下載。但在caffe根目錄下的data資料夾裡,作者已經為我們編寫好了下載資料的指令碼檔案,我們只需要聯網,執行這些指令碼檔案就行了。 注意:在caffe中執行所有程式,都必須在根目錄下進行,即/caffe,否則會出錯,因為指令碼檔案
【8】Caffe學習系列:solver優化方法
上文提到,到目前為止,caffe總共提供了六種優化方法: Stochastic Gradient Descent (type: "SGD"), AdaDelta (type: "AdaDelta"), Adaptive Gradient (type: "AdaGrad"),
【7】Caffe學習系列:solver及其配置
solver算是caffe的核心的核心,它協調著整個模型的運作。caffe程式執行必帶的一個引數就是solver配置檔案。執行程式碼一般為 $ caffe train --solver=*_slover.prototxt 在Deep Learning中,往往loss function是非凸的
【6】Caffe學習系列:Blob,Layer and Net以及對應配置檔案的編寫
深度網路(net)是一個組合模型,它由許多相互連線的層(layers)組合而成。Caffe就是組建深度網路的這樣一種工具,它按照一定的策略,一層一層的搭建出自己的模型。它將所有的資訊資料定義為blobs,從而進行便利的操作和通訊。Blob是caffe框架中一種標準的陣列,一種統一的記憶體介面,它詳細
【5】Caffe學習系列:其它常用層及引數
本文講解一些其它的常用層,包括:softmax_loss層,Inner Product層,accuracy層,reshape層和dropout層及其它們的引數配置。 1、softmax-loss softmax-loss層和softmax層計算大致是相同的。softmax是一個分類器,計算的
【4】Caffe學習系列:啟用層(Activiation Layers)及引數
在啟用層中,對輸入資料進行啟用操作(實際上就是一種函式變換),是逐元素進行運算的。從bottom得到一個blob資料輸入,運算後,從top輸入一個blob資料。在運算過程中,沒有改變資料的大小,即輸入和輸出的資料大小是相等的。 輸入:n*c*h*w 輸出:n*c*h*w 常用的啟用函式有