
python 爬蟲教程
爬蟲入門初級篇
IDE 選擇: PyCharm(推薦)、SublimeText3、VS2015、wingIDE
裝python2還是python3 ?
python社群需要很多年才能將現有的模組移植到支援python3. django web.py flask等還不支援python3。所以推薦安裝python2 最新版。
Windows 平臺
從 http://python.org/download/ 上安裝Python 2.7。您需要修改 PATH 環境變數,將Python的可執行程式及額外的指令碼新增到系統路徑中。將以下路徑新增到 PATH 中:
C:\Python2.7\;C:\Python2.7\Scripts\; 。從 http://sourceforge.net/projects/pywin32/ 安裝 pywin32。 請確認下載符合您系統的版本(win32或者amd64)
Linux Ubuntu 平臺
安裝Python : sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
學習需求:抓取的某個網站或者某個應用的內容,提取有用的價值
實現手段:模擬使用者在瀏覽器或者應用(app)上的操作,實現自動化的程式爬蟲應用場景(利用爬蟲能做什麼?)
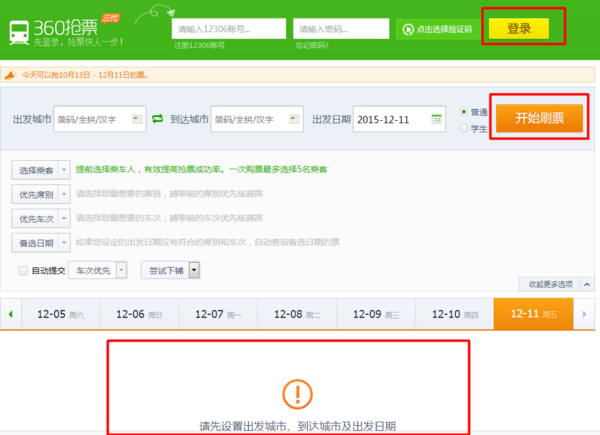
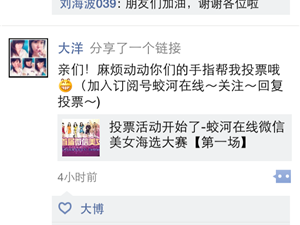
大家最熟悉的應用場景:搶票神器(360搶票器)、投票神器(微信朋友圈投票)
企業應用場景
1、各種熱門公司招聘中的職位數及月薪分佈

2、對某個App的下載量跟蹤

3、 飲食地圖
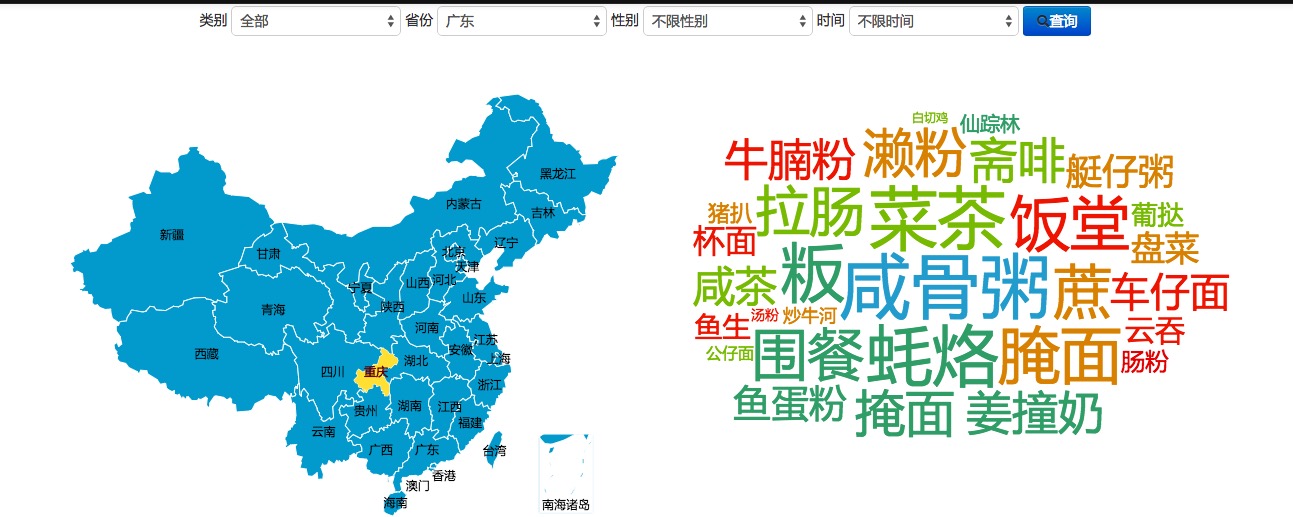
還可以把男的排除掉,只看女的:

4、 票房預測

爬蟲是什麼?
專業術語: 網路爬蟲(又被稱為網頁蜘蛛,網路機器人)網路爬蟲,是一種按照一定的規則,自動的抓取全球資訊網資訊的程式或者指令碼。
爬蟲起源(產生背景)
隨著網路的迅速發展,全球資訊網成為大量資訊的載體,如何有效地提取並利用這些資訊成為一個巨大的挑戰;搜尋引擎有Yahoo,Google,百度等,作為一個輔助人們檢索資訊的工具成為使用者訪問全球資訊網的入口和指南。網路爬蟲是搜尋引擎系統中十分重要的組成部分,它負責從網際網路中搜集網頁,採集資訊,這些網頁資訊用於建立索引從而為搜尋 引擎提供支援,它決定著整個引擎系統的內容是否豐富,資訊是否即時,因此其效能的優劣直接影響著搜尋引擎的效果。
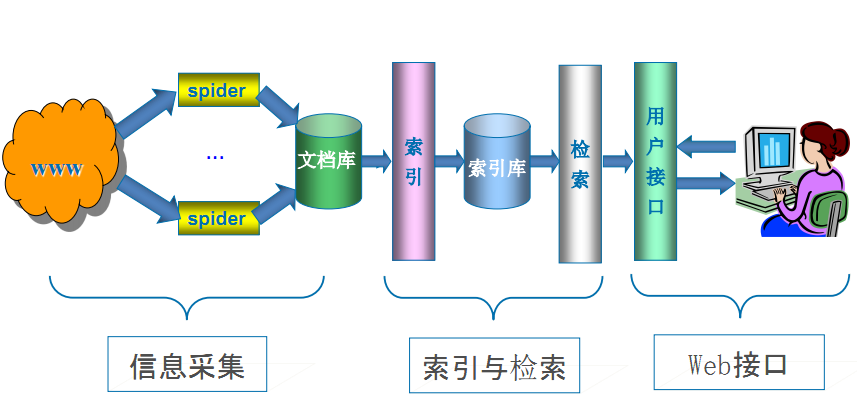
網路爬蟲程式的優劣,很大程度上反映了一個搜尋引擎的好差。
不信,你可以隨便拿一個網站去查詢一下各家搜尋對它的網頁收錄情況,爬蟲強大程度跟搜尋引擎好壞基本成正比。
搜尋引擎工作原理
第一步:抓取網頁(爬蟲)
搜尋引擎是通過一種特定規律的軟體跟蹤網頁的連結,從一個連結爬到另外一個連結,像蜘蛛在蜘蛛網上爬行一樣,所以被稱為“蜘蛛”也被稱為“機器人”。搜尋引擎蜘蛛的爬行是被輸入了一定的規則的,它需要遵從一些命令或檔案的內容。 Robots協議(也稱為爬蟲協議、機器人協議等)的全稱是“網路爬蟲排除標準”(Robots Exclusion Protocol),網站通過Robots協議告訴搜尋引擎哪些頁面可以抓取,哪些頁面不能抓取
https://www.taobao.com/robots.txt
http://www.qq.com/robots.txt
https://www.taobao.com/robots.txt
示例 CSDN robot.txt ( https://blog.csdn.net/robots.txt )檔案中 Sitemap:
# -*- coding: UTF-8 -*-
import re
import requests
def download(url, user_agent=r'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', num_retries=3):
print 'Downloading : ', url
headers = {'user-agent':user_agent}
try:
#r = requests.get(url, head=headers) #get中引數head錯誤,可以看到引發異常
r = requests.get(url, headers=headers)
html = None
if r.status_code == 200:
print 'status_code : {0}'.format(r.status_code)
html = r.content
else:
print 'status_code : {0}'.format(r.status_code)
except BaseException as ex:
print 'Download error : ', ex
html = None
if num_retries > 0:
print 'Download fail and retry...'
return download(url, user_agent, num_retries-1)
pass
return html
if __name__ == "__main__":
url = r'https://blog.csdn.net/s/sitemap/pcsitemapindex.xml'
sitemap = download(url)
links = re.findall(r'<loc>(.*?)</loc>', sitemap)
for link in links:
print link
pass第二步:資料儲存
搜尋引擎是通過蜘蛛跟蹤連結爬行到網頁,並將爬行的資料存入原始頁面資料庫。其中的頁面資料與使用者瀏覽器得到的HTML是完全一樣的。搜尋引擎蜘蛛在抓取頁面時,也做一定的重複內容檢測,一旦遇到權重很低的網站上有大量抄襲、採集或者複製的內容,很可能就不再爬行。
第三步:預處理
搜尋引擎將蜘蛛抓取回來的頁面,進行各種步驟的預處理。
⒈提取文字 ⒉中文分詞 ⒊去停止詞 ⒋消除噪音(搜尋引擎需要識別並消除這些噪聲,比如版權宣告文字、導航條、廣告等……) 5.正向索引 6.倒排索引 7.連結關係計算 8.特殊檔案處理。 除了HTML檔案外,搜尋引擎通常還能抓取和索引以文字為基礎的多種檔案型別,如 PDF、Word、WPS、XLS、PPT、TXT 檔案等。我們在搜尋結果中也經常會看到這些檔案型別。但搜尋引擎還不能處理圖片、視訊、Flash 這類非文字內容,也不能執行指令碼和程式。
第四步:排名,提供檢索服務
但是,這些通用性搜尋引擎也存在著一定的侷限性,如:
(1)不同領域、不同背景的使用者往往具有不同的檢索目的和需求,通用搜索引擎所返回的結果包含大量使用者不關心的網頁。
(2)通用搜索引擎的目標是儘可能大的網路覆蓋率,有限的搜尋引擎伺服器資源與無限的網路資料資源之間的矛盾將進一步加深。
(3)全球資訊網資料形式的豐富和網路技術的不斷髮展,圖片、資料庫、音訊、視訊多媒體等不同資料大量出現,通用搜索引擎往往對這些資訊含量密集且具有一定結構的資料無能為力,不能很好地發現和獲取。
(4)通用搜索引擎大多提供基於關鍵字的檢索,難以支援根據語義資訊提出的查詢。
為了解決上述問題,定向抓取相關網頁資源的聚焦爬蟲應運而生。 聚焦爬蟲是一個自動下載網頁的程式,它根據既定的抓取目標,有選擇的訪問全球資訊網上的網頁與相關的連結,獲取所需要的資訊。
與通用爬蟲(general purpose web crawler)不同,聚焦爬蟲並不追求大的覆蓋,而將目標定為抓取與某一特定主題內容相關的網頁,為面向主題的使用者查詢準備資料資源。
聚焦爬蟲工作原理以及關鍵技術概述
網路爬蟲是一個自動提取網頁的程式,它為搜尋引擎從全球資訊網上下載網頁,是搜尋引擎的重要組成。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入佇列,直到滿足系統的一定停止條件。聚焦爬蟲的工作流程較為複雜,需要根據一定的網頁分析演算法過濾與主題無關的連結,保留有用的連結並將其放入等待抓取的URL佇列。然後,它將根據一定的搜尋策略從佇列中選擇下一步要抓取的網頁URL,並重覆上述過程,直到達到系統的某一條件時停止。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,並建立索引,以便之後的查詢和檢索;對於聚焦爬蟲來說,這一過程所得到的分析結果還可能對以後的抓取過程給出反饋和指導。
相對於通用網路爬蟲,聚焦爬蟲還需要解決三個主要問題:
(1) 對抓取目標的描述或定義;
(2) 對網頁或資料的分析與過濾;
(3) 對URL的搜尋策略。
抓取目標的描述和定義是決定網頁分析演算法與URL搜尋策略如何制訂的基礎。而網頁分析演算法和候選URL排序演算法是決定搜尋引擎所提供的服務形式和爬蟲網頁抓取行為的關鍵所在。這兩個部分的演算法又是緊密相關的。
網路爬蟲的發展趨勢
隨著AJAX/Web2.0的流行,如何抓取AJAX等動態頁面成了搜尋引擎急需解決的問題,如果搜尋引擎依舊採用“爬”的機制,是無法抓取到AJAX頁面的有效資料的。 對於AJAX這樣的技術,所需要的爬蟲引擎必須是基於驅動的。而如果想要實現事件驅動,首先需要解決以下問題:
第一:JavaScript的互動分析和解釋;
第二:DOM事件的處理和解釋分發;
第三:動態DOM內容語義的抽取。
爬蟲發展的幾個階段(博士論文copy)
第一個階段可以說是早期爬蟲,斯坦福的幾位同學完成的抓取,當時的網際網路基本都是完全開放的,人類流量是主流;
第二個階段是分散式爬蟲,但是爬蟲面對新的問題是資料量越來越大,傳統爬蟲已經解決不了把資料都抓全的問題,需要更多的爬蟲,於是排程問題就出現了;
第三階段是暗網爬蟲。此時面對新的問題是資料之間的link越來越少,比如淘寶,點評這類資料,彼此link很少,那麼抓全這些資料就很難;還有一些資料是需要提交查詢詞才能獲取,比如機票查詢,那麼需要尋找一些手段“發現”更多,更完整的不是明面上的資料。
第四階段智慧爬蟲,這主要是爬蟲又開始面對新的問題:社交網路資料的抓取。
社交網路對爬蟲帶來的新的挑戰包括
有一條賬號護城河
我們通常稱UGC(User Generated Content)指使用者原創內容。為web2.0,即資料從單向傳達,到雙向互動,人民群眾可以與網站產生互動,因此產生了賬號,每個人都通過賬號來標識身份,提交資料,這樣一來社交網路就可以通過封賬號來提高資料抓取的難度,通過賬號來發現非人類流量。之前沒有賬號只能通過cookie和ip。cookie又是易變,易揮發的,很難長期標識一個使用者。
網路走向封閉
新浪微博在2012年以前都是基本不封的,隨便寫一個程式怎麼抓都不封,但是很快,越來越多的站點都開始防止競爭對手,防止爬蟲來抓取,資料逐漸走向封閉,越來越多的人難以獲得資料。甚至都出現了專業的爬蟲公司,這在2010年以前是不可想象的。。
反爬手段,封殺手法千差萬別
寫一個通用的框架抓取成百上千萬的網站已經成為歷史,或者說已經是一個技術相對成熟的工作,也就是已經有相對成熟的框架來”盜“成百上千的墓,但是極個別的墓則需要特殊手段了,目前市場上比較難以抓取的資料包括,微信公共賬號,微博,facebook,ins,淘寶等等。具體原因各異,但基本無法用一個統一框架來完成,太特殊了。如果有一個通用的框架能解決我說的這幾個網站的抓取,這一定是一個非常震撼的產品,如果有,一定要告訴我,那我公開出來,然後就改行了。
當面對以上三個挑戰的時候,就需要智慧爬蟲。智慧爬蟲是讓爬蟲的行為儘可能模仿人類行為,讓反爬策略失效,只有”混在老百姓隊伍裡面,才是安全的“,因此這就需要琢磨瀏覽器了,很多人把爬蟲寫在了瀏覽器外掛裡面,把爬蟲寫在了手機裡面,寫在了路由器裡面(春節搶票王)。再有一個傳統的爬蟲都是隻有讀操作的,沒有寫操作,這個很容易被判是爬蟲,智慧的爬蟲需要有一些自動化互動的行為,這都是一些抵禦反爬策略的方法。+
從商業價值上,是一個能夠抽象千百萬網站抓取框架的爬蟲工程師值錢,還是一個能抓特定難抓網站的爬蟲工程師值錢?
能花錢來買,被市場認可的資料,都是那些特別難抓的,抓取成本異常高的資料。
目前市場上主流的爬蟲工程師,都是能夠抓成百上千網站的資料,但如果想有價值,還是得有能力抓特別難抓的資料,才能估上好價錢。
爬蟲基本原理
爬蟲是 模擬使用者在瀏覽器或者某個應用上的操作,把操作的過程、實現自動化的程式
當我們在瀏覽器中輸入一個url後回車,後臺會發生什麼?比如說你輸入http://www.sina.com.cn/
簡單來說這段過程發生了以下四個步驟:
1.查詢域名對應的IP地址。
2.向IP對應的伺服器傳送請求。
3.伺服器響應請求,發回網頁內容。
4.瀏覽器解析網頁內容。
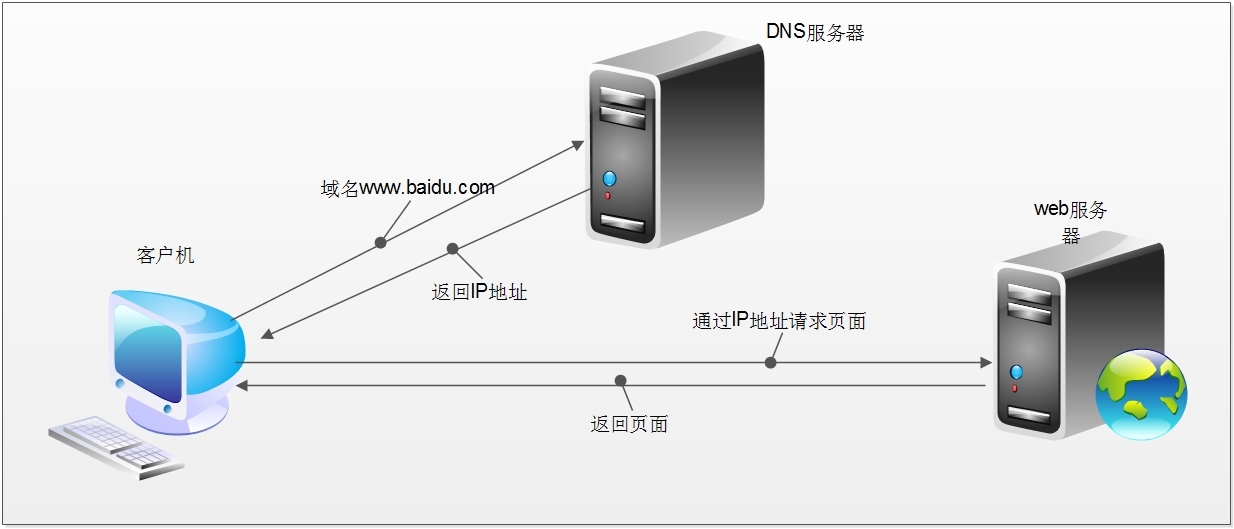
網路爬蟲本質:本質就是瀏覽器http請求。
瀏覽器和網路爬蟲是兩種不同的網路客戶端,都以相同的方式來獲取網頁:
網路爬蟲要做的,簡單來說,就是實現瀏覽器的功能。通過指定url,直接返回給使用者所需要的資料, 而不需要一步步人工去操縱瀏覽器獲取。
瀏覽器是如何傳送和接收這個資料呢? HTTP簡介。
HTTP協議(HyperText Transfer Protocol,超文字傳輸協議)目的是為了提供一種釋出和接收HTML(HyperText Markup Language)頁面的方法。
HTTP協議所在的協議層(瞭解)
HTTP是基於TCP協議之上的。在TCP/IP協議參考模型的各層對應的協議如下圖,其中HTTP是應用層的協議。 預設HTTP的埠號為80,HTTPS的埠號為443。
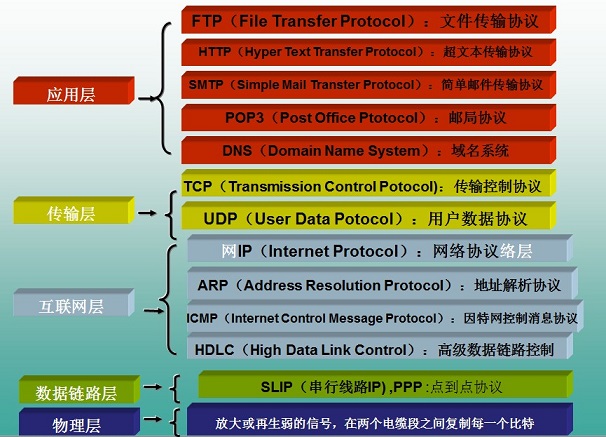
HTTP工作過程
一次HTTP操作稱為一個事務,其工作整個過程如下:
1 ) 、地址解析,
如用客戶端瀏覽器請求這個頁面:http://localhost.com:8080/index.htm從中分解出協議名、主機名、埠、物件路徑等部分,對於我們的這個地址,解析得到的結果如下: 協議名:http 主機名:localhost.com 埠:8080 物件路徑:/index.htm在這一步,需要域名系統DNS解析域名localhost.com,得主機的IP地址。
2)、封裝HTTP請求資料包
把以上部分結合本機自己的資訊,封裝成一個HTTP請求資料包
3)封裝成TCP包,建立TCP連線(TCP的三次握手)
在HTTP工作開始之前,客戶機(Web瀏覽器)首先要通過網路與伺服器建立連線,該連線是通過TCP來完成的,該協議與IP協議共同構建Internet,即著名的TCP/IP協議族,因此Internet又被稱作是TCP/IP網路。HTTP是比TCP更高層次的應用層協議,根據規則,只有低層協議建立之後才能,才能進行更層協議的連線,因此,首先要建立TCP連線,一般TCP連線的埠號是80。這裡是8080埠
4)客戶機發送請求命令
建立連線後,客戶機發送一個請求給伺服器,請求方式的格式為:統一資源識別符號(URL)、協議版本號,後邊是MIME資訊包括請求修飾符、客戶機資訊和可內容。
5)伺服器響應
伺服器接到請求後給予相應的響應資訊,其格式為一個狀態行,包括資訊的協議版本號、一個成功或錯誤的程式碼,後邊是MIME資訊包括伺服器資訊、實體資訊和可能的內容。
實體訊息是伺服器向瀏覽器傳送頭資訊後,它會發送一個空白行來表示頭資訊的傳送到此為結束,接著,它就以Content-Type應答頭資訊所描述的格式傳送使用者所請求的實際資料
6)伺服器關閉TCP連線
一般情況下,一旦Web伺服器向瀏覽器傳送了請求資料,它就要關閉TCP連線,然後如果瀏覽器或者伺服器在其頭資訊加入了這行程式碼Connection:keep-alive
TCP連線在傳送後將仍然保持開啟狀態,於是,瀏覽器可以繼續通過相同的連線傳送請求。保持連線節省了為每個請求建立新連線所需的時間,還節約了網路頻寬。
HTTP協議棧資料流

HTTPS
HTTPS(全稱:Hypertext Transfer Protocol over Secure Socket Layer),是以安全為目標的HTTP通道,簡單講是HTTP的安全版。即HTTP下加入SSL層,HTTPS的安全基礎是SSL。其所用的埠號是443。
SSL:安全套接層,是netscape公司設計的主要用於web的安全傳輸協議。這種協議在WEB上獲得了廣泛的應用。通過證書認證來確保客戶端和網站伺服器之間的通訊資料是加密安全的。
有兩種基本的加解密演算法型別:
1)對稱加密(symmetrcic encryption):金鑰只有一個,加密解密為同一個密碼,且加解密速度快,典型的對稱加密演算法有DES、AES,RC5,3DES等;對稱加密主要問題是共享祕鑰,除你的計算機(客戶端)知道另外一臺計算機(伺服器)的私鑰祕鑰,否則無法對通訊流進行加密解密。解決這個問題的方案非對稱祕鑰。
2)非對稱加密:使用兩個祕鑰:公共祕鑰和私有祕鑰。私有祕鑰由一方密碼儲存(一般是伺服器儲存),另一方任何人都可以獲得公共祕鑰。這種金鑰成對出現(且根據公鑰無法推知私鑰,根據私鑰也無法推知公鑰),加密解密使用不同金鑰(公鑰加密需要私鑰解密,私鑰加密需要公鑰解密),相對對稱加密速度較慢,典型的非對稱加密演算法有RSA、DSA等。
https通訊的優點:
客戶端產生的金鑰只有客戶端和伺服器端能得到;
加密的資料只有客戶端和伺服器端才能得到明文;+
客戶端到服務端的通訊是安全的。
爬蟲工作流程
網路爬蟲是捜索引擎(Baidu、Google、Yahoo)抓取系統的重要組成部分。主要目的是將網際網路上的網頁下載到本地,形成一個網際網路內容的映象備份。
網路爬蟲的基本工作流程如下:
1.首先選取一部分精心挑選的種子URL;
2.將這些URL放入待抓取URL佇列;
3.從待抓取URL佇列中取出待抓取在URL,解析DNS,並且得到主機的ip,將URL對應的網頁下載下來並存儲到已下載網頁庫中。此外,將這些URL放進已抓取URL佇列。
4.分析已抓取URL佇列中的URL,分析其中的其他URL,並且將URL放入待抓取URL佇列,從而進入下一個迴圈。

import requests #用來爬取網頁
from bs4 import BeautifulSoup #用來解析網頁
#我們的種子
seds = ["http://www.lagou.com/"]
sum = 0
#我們設定終止條件為:爬取到10000個頁面時,就不玩了
while sum < 10000 :
if sum < len(seds):
r = requests.get(seds[sum])
sum = sum + 1
#提取結構化資料;做儲存操作
do_save_action(r)
soup = BeautifulSoup(r.content)
urls = soup.find_all("href",.....) //解析網頁所有的連結
for url in urls:
seds.append(url)
else:
break# -*- coding:utf-8 -*-
import os
import requests
from bs4 import BeautifulSoup
def spider():
url = "http://bj.grfy.net/"
proxies = {"http": "http://172.17.18.80:8080", "https": "https://172.17.18.80:8080"}
r = requests.get(url, proxies=proxies)
html = r.content
soup = BeautifulSoup(html, "lxml")
divs = soup.find_all("div", class_="content")
print len(divs)
print soup
if __name__ == "__main__":
spider()
os.system("pause")HTTP代理神器Fidder
Fiddler不但能截獲各種瀏覽器發出的HTTP請求, 也可以截獲各種智慧手機發出的HTTP/HTTPS請求。 Fiddler能捕獲IOS裝置發出的請求,比如IPhone, IPad, MacBook. 等等蘋果的裝置。 同理,也可以截獲Andriod,Windows Phone的等裝置發出的HTTP/HTTPS。工作原理:Fiddler 是以代理web伺服器的形式工作的,它使用代理地址:127.0.0.1,埠:8888。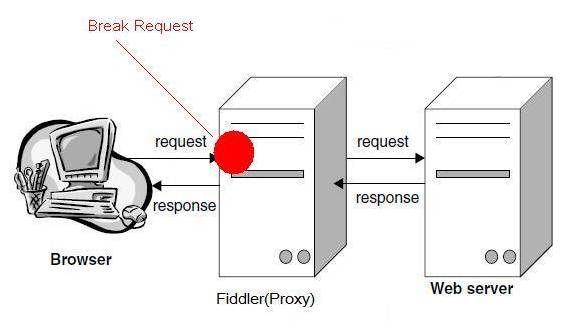
Fiddler抓取HTTPS設定:啟動Fiddler,開啟選單欄中的 Tools > Fiddler Options,開啟“Fiddler Options”對話方塊。
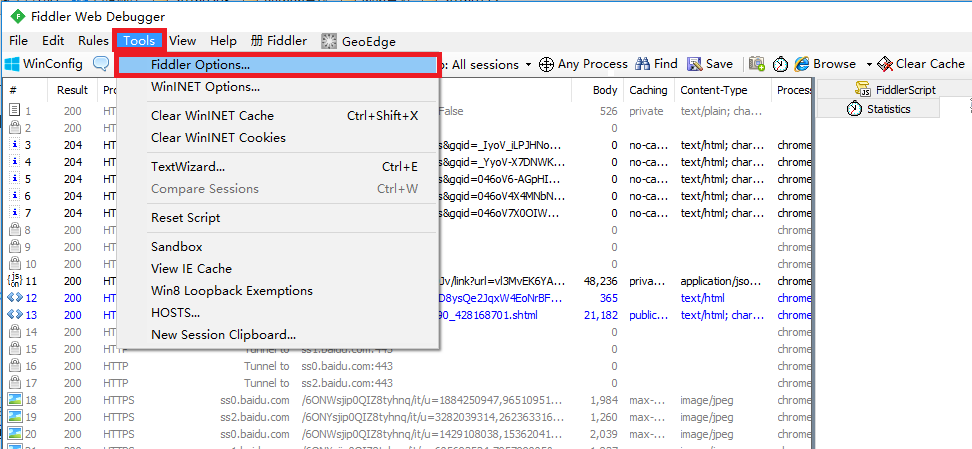
對Fiddler進行設定:開啟工具欄->Tools->Fiddler Options->HTTPS
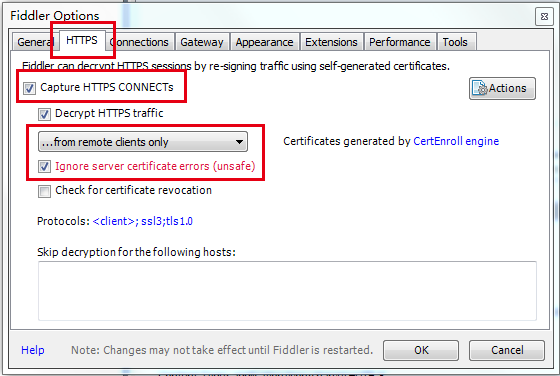
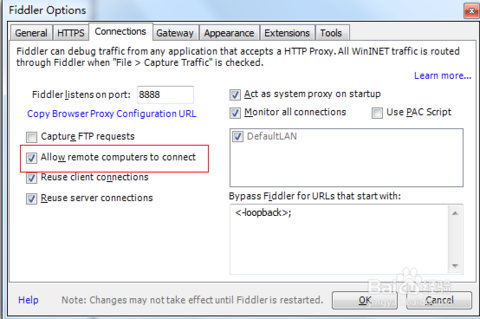
選中Capture HTTPS CONNECTs,因為我們要用Fiddler獲取手機客戶端發出的HTTPS請求,所以中間的下拉選單中選中from remote clients only。選中下方Ignore server certificate errors.
配置Fiddler允許遠端連線:Fiddler 主選單 Tools -> Fiddler Options…-> Connections頁籤,選中Allow remote computers to connect。重啟Fidler(這一步很重要,必須做)。
Fiddler 如何捕獲Firefox的會話
能支援HTTP代理的任意程式的資料包都能被Fiddler嗅探到,Fiddler的執行機制其實就是本機上監聽8888埠的HTTP代理。 Fiddler2啟動的時候預設IE的代理設為了127.0.0.1:8888,而其他瀏覽器是需要手動設定的,所以將Firefox的代理改為127.0.0.1:8888就可以監聽資料了。 Firefox 上通過如下步驟設定代理 點選: Tools -> Options, 在Options 對話方塊上點選Advanced tab - > network tab -> setting.
Fiddler如何捕獲HTTPS會話
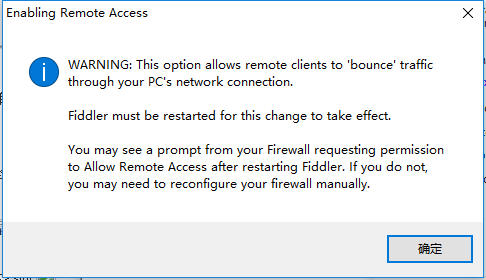
預設下,Fiddler不會捕獲HTTPS會話,需要你設定下, 開啟Fiddler Tool->Fiddler Options->HTTPS tab
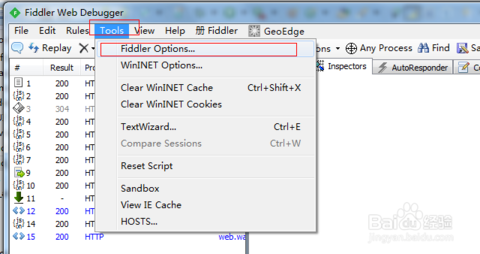
選中checkbox, 彈出如下的對話方塊,點選"YES"
點選"Yes" 後,就設定好了。
Fiddler的基本介面
特別注意: 遇到這個Click請點選Click

Fiddler強大的Script系統
Fiddler包含了一個強大的基於事件指令碼的子系統,並且能使用.net語言進行擴充套件。
官方的幫助文件: http://www.fiddler2.com/Fiddler/dev/ScriptSamples.asp
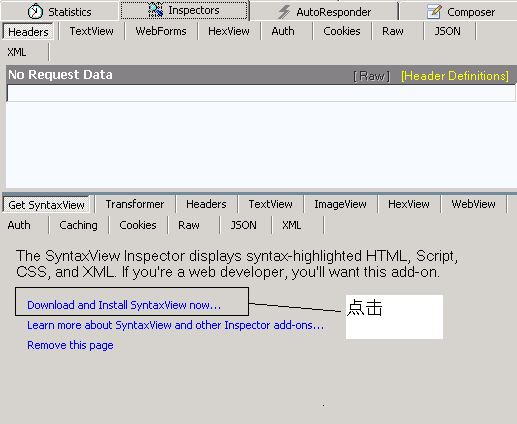
首先先安裝SyntaxView外掛,Inspectors tab->Get SyntaxView tab->Download and Install SyntaxView Now... 如下圖
安裝成功後Fiddler 就會多了一個Fiddler Script tab,如下圖:
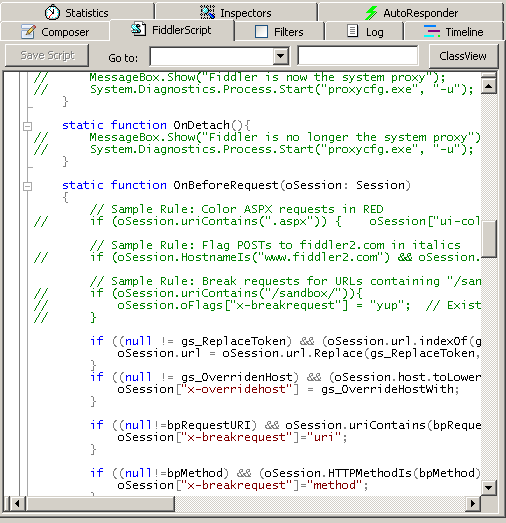
在裡面我們就可以編寫指令碼了, 看個例項讓所有cnblogs的會話都顯示紅色。 把這段指令碼放在OnBeforeRequest(oSession: Session) 方法下,並且點選"Save script"
if (oSession.HostnameIs("www.cnblogs.com")) {
oSession["ui-color"] = "red";
}這樣所有的cnblogs的會話都會顯示紅色。
HTTP協議介紹
設計HTTP(HyperText Transfer Protocol)是為了提供一種釋出和接收HTML(HyperText Markup Language)頁面的方法。
Http兩部分組成:請求、響應。
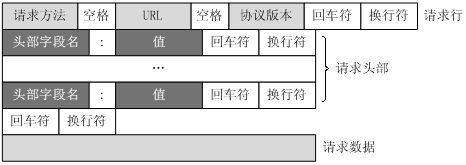
客戶端請求訊息:客戶端傳送一個HTTP請求到伺服器的請求訊息包括以下格式:請求行(request line)、請求頭部(header)、空行和請求資料四個部分組成,下圖給出了請求報文的一般格式。
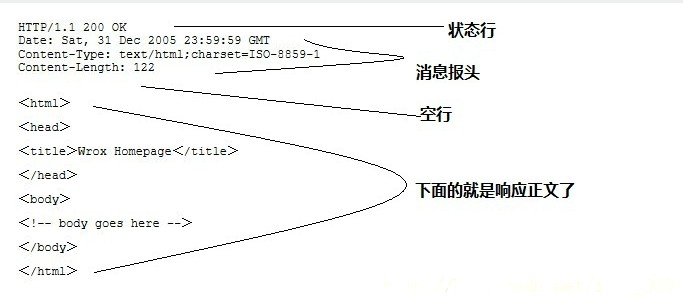
伺服器響應訊息:HTTP響應也由四個部分組成,分別是:狀態行、訊息報頭、空行和響應正文。
提出一個問題?
伺服器和客戶端的互動僅限於請求/響應過程,結束之後便斷開, 在下一次請求伺服器會認為新的客戶端;為了維護他們之間的連結,讓伺服器知道這是前一個使用者傳送的請求,必須在一個地方儲存客戶端的資訊,Cookie通過在客戶端記錄資訊確定使用者身份。 Session通過在伺服器端記錄資訊確定使用者身份。
HTTP 請求
請求方法
根據HTTP標準,HTTP請求可以使用多種請求方法。
HTTP1.0定義了三種請求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五種請求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
|
序號 |
方法 |
描述 |
|
1 |
GET |
請求指定的頁面資訊,並返回實體主體。 |
|
2 |
HEAD |
類似於get請求,只不過返回的響應中沒有具體的內容,用於獲取報頭 |
|
3 |
POST |
向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案)。資料被包含在請求體中。POST請求可能會導致新的資源的建立和/或已有資源的修改。 |
|
4 |
PUT |
從客戶端向伺服器傳送的資料取代指定的文件的內容。 |
|
5 |
DELETE |
請求伺服器刪除指定的頁面。 |
|
6 |
CONNECT |
HTTP/1.1協議中預留給能夠將連線改為管道方式的代理伺服器。 |
|
7 |
OPTIONS |
允許客戶端檢視伺服器的效能。 |
|
8 |
TRACE |
回顯伺服器收到的請求,主要用於測試或診斷。 |
GET和POST方法區別歸納如下幾點:
1. GET是從伺服器上獲取資料,POST是向伺服器傳送資料。
2. GET請求引數顯示,都顯示在瀏覽器網址上,POST請求引數在請求體當中,訊息長度沒有限制而且以隱式的方式進行傳送
3. 儘量避免使用Get方式提交表單,因為有可能會導致安全問題。 比如說在登陸表單中用Get方式,使用者輸入的使用者名稱和密碼將在位址列中暴露無遺。 但是在分頁程式中,用Get方式就比用Post好。
URL概述
統一資源定位符(URL,英語 Uniform / Universal Resource Locator的縮寫)是用於完整地描述Internet上網頁和其他資源的地址的一種標識方法。
URL格式:基本格式如下 schema://host[:port#]/path/…/[?query-string][#anchor]
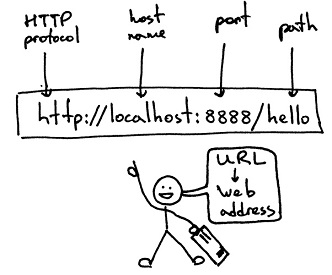
1. schema 協議(例如:http, https, ftp)
2. host 伺服器的IP地址或者域名
3. port# 伺服器的埠(如果是走協議預設埠,預設埠80)
4. path 訪問資源的路徑
5. query-string 引數,傳送給http伺服器的資料
6. anchor- 錨(跳轉到網頁的指定錨點位置)
例子:
http://www.sina.com.cn/
http://192.168.0.116:8080/index.jsp
http://item.jd.com/11052214.html#product-detail
http://www.website.com/test/test.aspx?name=sv&x=true#stuff
一個URL的請求過程:
當你在瀏覽器輸入URL http://www.website.com 的時候,瀏覽器傳送一個Request去獲取 http://www. website.com的html. 伺服器把Response傳送回給瀏覽器. 瀏覽器分析Response中的 HTML,發現其中引用了很多其他檔案,比如圖片,CSS檔案,JS檔案。 瀏覽器會自動再次傳送Request去獲取圖片,CSS檔案,或者JS檔案。 當所有的檔案都下載成功後, 網頁就被顯示出來了。
常用的請求報頭
Host:Host初始URL中的主機和埠,用於指定被請求資源的Internet主機和埠號,它通常從HTTP URL中提取出來的
Connection:表示客戶端與服務連線型別;
1. client 發起一個包含Connection:keep-alive的請求
2. server收到請求後如果server支援keepalive回覆一個包含Connection:keep-alive的響應不關閉連線,否則回覆一個包含Connection:close的響應關閉連線。
3. 如果client收到包含Connection:keep-alive的響應,向同一個連線傳送下一個請求,直到一方主動關閉連線。 Keep-alive在很多情況下能夠重用連線,減少資源消耗,縮短響應時間HTTP
Accept:表示瀏覽器支援的 MIME 型別
MIME的英文全稱是 Multipurpose Internet Mail Extensions(多用途網際網路郵件擴充套件)
eg:
Accept:image/gif,表明客戶端希望接受GIF圖象格式的資源;
Accept:text/html,表明客戶端希望接受html文字。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
意思:瀏覽器支援的 MIME 型別分別是 text/html、application/xhtml+xml、application/xml 和 */*,優先順序是它們從左到右的排列順序。
Text:用於標準化地表示的文字資訊,文字訊息可以是多種字符集和或者多種格式的;
Application:用於傳輸應用程式資料或者二進位制資料;設定某種副檔名的檔案用一種應用程式來開啟的方式型別,當該副檔名檔案被訪問的時候,瀏覽器會自動使用指定應用程式來開啟
|
Mime型別 |
副檔名 |
|
text/html |
.htm .html *.shtml |
|
text/plain |
text/html是以html的形式輸出,比如 |
|
application/xhtml+xml |
.xhtml .xml |
|
text/css |
*.css |
|
application/msexcel |
.xls .xla |
|
application/msword |
.doc .dot |
|
application/octet-stream |
*.exe |
|
application/pdf |
|
|
..... |
..... |
q是權重係數,範圍 0 =< q <= 1,q 值越大,請求越傾向於獲得其“;”之前的型別表示的內容,若沒有指定 q 值越大,請求越傾向於獲得其“,則預設為1,若被賦值為0,則用於提醒伺服器哪些是瀏覽器不接受的內容型別。
Content-Type:POST 提交,application/x-www-form-urlencoded 提交的資料按照 key1=val1&key2=val2 的方式進行編碼,key 和 val 都進行了 URL 轉碼。
User-Agent: 瀏覽器型別
Referer: 請求來自哪個頁面,使用者是從該 Referer URL頁面訪問當前請求的頁面。
Accept-Encoding:瀏覽器支援的壓縮編碼型別,比如gzip,支援gzip的瀏覽器返回經gzip編碼的HTML頁面。許多情形下這可以減少5到10倍的下載時間
eg:
Accept-Encoding:gzip;q=1.0, identity; q=0.5, *;q=0 // 按順序支援 gzip , identity
如果有多個Encoding同時匹配, 按照q值順序排列
如果請求訊息中沒有設定這個域,伺服器假定客戶端對各種內容編碼都可以接受。
Accept-Language:瀏覽器所希望的語言種類,當伺服器能夠提供一種以上的語言版本時要用到。
eg:
Accept-Language:zh-cn
如果請求訊息中沒有設定這個報頭域,伺服器假定客戶端對各種語言都可以接受。
Accept-Charset:瀏覽器可接受的字符集,用於指定客戶端接受的字符集
eg:
Accept-Charset:iso-8859-1,gb2312
ISO8859-1,通常叫做Latin-1。Latin-1包括了書寫所有西方歐洲語言不可缺少的附加字元;
gb2312是標準中文字符集;
UTF-8 是 UNICODE 的一種變長字元編碼,可以解決多種語言文字顯示問題,從而實現應用國際化和本地化。
如果在請求訊息中沒有設定這個域,預設是任何字符集都可以接受。
HTTP 響應
掌握常用的響應狀態碼
伺服器上每一個HTTP 應答物件response包含一個數字"狀態碼"。
有時狀態碼指出伺服器無法完成請求。預設的處理器會為你處理一部分這種應答。
例如:假如response是一個"重定向",需要客戶端從別的地址獲取文件,urllib2將為你處理。
其他不能處理的,urlopen會產生一個HTTPError。
典型的錯誤包含"404"(頁面無法找到),"403"(請求禁止),和"401"(帶驗證請求)。
HTTP狀態碼錶示HTTP協議所返回的響應的狀態。
比如客戶端向伺服器傳送請求,如果成功地獲得請求的資源,則返回的狀態碼為200,表示響應成功。
如果請求的資源不存在, 則通常返回404錯誤。
HTTP響應狀態碼通常分為5種類型,分別以1~5五個數字開頭,由3位整陣列成,第一個數字定義了響應的類別:
|
分類 |
分類描述 |
|
1** |
資訊,伺服器收到請求,需要請求者繼續執行操作 |
|
2** |
成功,操作被成功接收並處理 |
|
3** |
重定向,需要進一步的操作以完成請求 |
|
4** |
客戶端錯誤,請求包含語法錯誤或無法完成請求 |
|
5** |
伺服器錯誤,伺服器在處理請求的過程中發生了錯誤 |
最常用的響應狀態碼
200 (OK): 請求成功,找到了該資源,並且一切正常。處理方式:獲得響應的內容,進行處理
201 請求完成,結果是建立了新資源。新建立資源的URI可在響應的實體中得到 處理方式:爬蟲中不會遇到
202 請求被接受,但處理尚未完成 處理方式:阻塞等待
204 伺服器端已經實現了請求,但是沒有返回新的信 息。如果客戶是使用者代理,則無須為此更新自身的文件檢視。 處理方式:丟棄
300 該狀態碼不被HTTP/1.0的應用程式直接使用, 只是作為3XX型別迴應的預設解釋。存在多個可用的被請求資源。 處理方式:若程式中能夠處理,則進行進一步處理,如果程式中不能處理,則丟棄
301 (Moved Permanently): 請求的文件在其他地方,新的URL在Location頭中給出,瀏覽器應該自動地訪問新的URL。處理方式:重定向到分配的URL
302 (Found): 類似於301,但新的URL應該被視為臨時性的替代,而不是永久性的。處理方式:重定向到臨時的URL
304 (NOT MODIFIED): 該資源在上次請求之後沒有任何修改。這通常用於瀏覽器的快取機制。處理方式:丟棄
400 (Bad Request): 請求出現語法錯誤。非法請求 處理方式:丟棄
401 未授權 處理方式:丟棄
403 (FORBIDDEN): 客戶端未能獲得授權。這通常是在401之後輸入了不正確的使用者名稱或密碼。禁止訪問 處理方式:丟棄
404 (NOT FOUND): 在指定的位置不存在所申請的資源。沒有找到 。 處理方式:丟棄
5XX 迴應程式碼以“5”開頭的狀態碼錶示伺服器端發現自己出現錯誤,不能繼續執行請求 處理方式:丟棄
500 (Internal Server Error): 伺服器遇到了意料不到的情況,不能完成客戶的請求
503 (Service Unavailable): 伺服器由於維護或者負載過重未能應答。
例如,Servlet可能在資料庫連線池已滿的情況下返回503。伺服器返回503時可以提供一個Retry-After頭
常用的響應報頭(瞭解)
Location:表示客戶應當到哪裡去提取文件,用於重定向接受者到一個新的位置
Server:伺服器名字,包含了伺服器用來處理請求的軟體資訊
eg: Server響應報頭域的一個例子:
Server:Apache-Coyote/1.1
Set-Cookie:設定和頁面關聯的Cookie。
例如:前一個 cookie 被存入瀏覽器並且瀏覽器試圖請求 http://www.ibm.com/foo/index.html 時
Set-Cookie:customer=huangxp; path=/foo; domain=.ibm.com;
expires= Wednesday, 19-OCT-05 23:12:40 GMT;
Set-Cookie的每個屬性解釋如下:
Customer=huangxp 一個"名稱=值"對,把名稱customer設定為值"huangxp",這個屬性在Cookie中必須有。
path=/foo 伺服器路徑。
domain=.ibm.com 指定cookie 的域名。
expires= Wednesday, 19-OCT-05 23:12:40 GMT 指定cookie 失效的時間
使用 Urllib2庫
urllib2是python2.7自帶的模組(不需要下載),它支援多種網路協議,比如 FTP、HTTP、HTTPS等。 urllib2在python3.x中被改為urllib.request
利用urllib2提供了一個介面 urlopen函式
urllib2 官方文件 :https://docs.python.org/2/library/urllib2.html
urlopen(url, data, timeout,....)
(1)第一個引數url即為URL,第一個引數URL是必須要傳送的
(2)第二個引數data是訪問URL時要傳送的資料,data預設為空None
(3)第三個timeout是設定超時時間,timeout預設為 60s(socket._GLOBAL_DEFAULT_TIMEOUT)
GET請求方式
以傳智播客官方網站 http://www.itcast.cn
import urllib2
response = urllib2.urlopen('http://www.itcast.cn/')
data = response.read()
print data
print response.code儲存成 demo.py,進入該檔案的目錄,執行如下命令檢視執行結果: python demo.py
如果我想新增 Header資訊怎麼辦? 利用 urllib2.Request類
利用urllib2.Request方法,可以用來構造一個Http請求訊息
help(urllib2.Request)
正則:headers 轉dict
^(.*):\s(.*)$
"\1":"\2",# -*- coding: utf-8 -*-
import urllib2
get_headers={
'Host': 'www.itcast.cn',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
#此處是壓縮演算法;不便於檢視,要做解壓
#'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': 'pgv_pvi=7044633600; tencentSig=6792114176; IESESSION=alive; pgv_si=s3489918976; CNZZDATA4617777=cnzz_eid%3D768417915-1468987955-%26ntime%3D1470191347; _qdda=3-1.1; _qddab=3-dyl6uh.ireawgo0; _qddamta_800068868=3-0'
}
request = urllib2.Request("http://www.itcast.cn/",headers=get_headers)
#request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
response = urllib2.urlopen(request)
print response.code
data = response.read()
print data# -*- coding: utf-8 -*-
import urllib2
import urllib
proxy_handler = urllib2.ProxyHandler({"http" : 'http://192.168.17.1:8888'})
opener = urllib2.build_opener(proxy_handler)
urllib2.install_opener(opener)
Sum = 1
output = open('lagou.json', 'w')
for page in range(1,Sum+1):
formdata = 'first=false&pn='+str(page)+'&kd='
print '執行到第 (%2d) 頁面' %(page)
send_headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
' X-Requested-With': 'XMLHttpRequest'
}
request =urllib2.Request('http://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false',headers=send_headers)
#request.add_header('X-Requested-With','XMLHttpRequest')
#request.headers=send_headers
request.add_data(formdata)
print request.get_data()
response = urllib2.urlopen(request)
print response.code
resHtml =response.read()
#print resHtml
output.write(resHtml+'\n')
output.close()
print '-'*4 + 'end'+'-'*4
提出一個問題,如果要採集的是 拉鉤招聘網站 北京>>朝陽區>>望京 以這個網站為例,該如何理解這個url ?
http://www.lagou.com/jobs/list_?px=default&city=%E5%8C%97%E4%BA%AC&district=%E6%9C%9D%E9%98%B3%E5%8C%BA&bizArea=%E6%9C%9B%E4%BA%AC#filterBox
urlencode編碼/解碼線上工具
# -*- coding: utf-8 -*-
import urllib2
import urllib
query = {
'city':'北京',
'district':'朝陽區',
'bizArea':'望京'
}
print urllib.urlencode(query)
page =3
values = {
'first':'false',
'pn':str(page),
'kd':'後端開發',
}
formdata = urllib.urlencode(values)
print formdata小結
Content-Length: 是指報頭Header以外的內容長度,指 表單資料長度
X-Requested-With: XMLHttpRequest :表示Ajax非同步請求
Content-Type: application/x-www-form-urlencoded :表示:提交的表單資料 會按照name/value 值對 形式進行編碼
例如:name1=value1&name2=value2... 。name 和 value 都進行了 URL 編碼(utf-8、gb2312)
線上測試字串長度
作業
- 常用的請求報頭(Header、Content-Type)、響應報頭
- 常用請求方式(GET、POST)
- gzip、deflate壓縮
- 網頁編碼格式和自動識別
- fidder工具使用
- urllib2、urllib
- HTTP代理
URL和URI的區別
URL:統一資源定位符(uniform resource location);平時上網時在 IE 瀏覽器中輸入的那個地址就是 URL。比如:網易 http://www.163.com 就是一個URL 。
URI:統一資源識別符號(uniform resource identifier)。Web 上可用的每種資源 - HTML 文件、影象、視訊片段、程式, 由一個通過通用資源標誌符 (Universal Resource Identifier, 簡稱 "URI") 進行定位。
URL是Internet上用來描述資訊資源的字串,主要用在各種WWW客戶程式和伺服器程式上。採用URL可以用一種統一的格式來描述各種資訊資源,包括檔案、伺服器的地址和目錄等。
URI 是個純粹的語法結構,用於指定標識web資源的字串的各個不同部分,URL 是URI的一個特例,它包含定位web資源的足夠資訊。
URL 是 URI 的一個子集
常見的加密、解密
1) MD5/SHA (單向密雜湊演算法(Hash函式)) MessageDigest是一個數據的數字指紋.即對一個任意長度的資料進行計算,產生一個唯一指紋號. MessageDigest的特性: A) 兩個不同的資料,難以生成相同的指紋號 B) 對於指定的指紋號,難以逆向計算出原始資料 代表:MD5/SHA
2) DES、AES、TEA(對稱加密演算法) 單金鑰演算法,是資訊的傳送方採用金鑰A進行資料加密,資訊的接收方採用同一個金鑰A進行資料解密. 單金鑰演算法是一個對稱演算法. 缺點:由於採用同一個金鑰進行加密解密,在多使用者的情況下,金鑰保管的安全性是一個問題. 代表:DES
3) RSA(非對稱演算法) RSA 是一種非對稱加解密演算法。 RSA is named from the initials of the authors, Ron Rivest, Adi Shamir, and Leonard Adleman,who first published the algorithm.
RSA 與 DSA 都是非對稱加密演算法。其中RSA的安全性是基於極其困難的大整數的分解(兩個素數的乘積);DSA 的安全性 是基於整數有限域離散對數難題。基本上可以認為相同金鑰長度的 RSA 演算法與 DSA 演算法安全性相當。 公鑰用於加密,它是向所有人公開的;私鑰用於解密,只有密文的接收者持有。 適用OPENSSL 適用RSA 的命令如下: 生成一個金鑰(私鑰) [[email protected] ~]# openssl genrsa -out private.key 1024 注意: 需要注意的是這個檔案包含了公鑰和金鑰兩部分,也就是說這個檔案即可用來加密也可以用來解密,後面的1024是生成 金鑰的長度. 通過金鑰檔案private.key 提取公鑰
[[email protected] ~]# openssl rsa -in private.key -pubout -out pub.key
使用公鑰加密資訊
[[email protected] ~]# echo -n "123456" | openssl rsautl -encrypt -inkey pub.key -pubin >encode.result
使用私鑰解密資訊
[[email protected] ~]#cat encode.result | openssl rsautl -decrypt -inkey private.key
123456
4) DSA (Digital Signature Algorithm)(數字簽名演算法)(非對稱加密) DSA 一般用於數字簽名和認證。 DSA是Schnorr和ElGamal簽名演算法的變種,被美國NIST作為DSS(DigitalSignature Standard)。 DSA是基於整數有限域離散對數難題的,其安全性與RSA相比差不多。 在DSA數字簽名和認證中,傳送者使用自己的私鑰對檔案或訊息進行簽名,接受者收到訊息後使用傳送者的公鑰 來驗證簽名的真實性。DSA只是一種演算法,和RSA不同之處在於它不能用作加密和解密,也不能進行金鑰交換, 只用於簽名,它比RSA要快很多. 生成一個金鑰(私鑰)
[[email protected] ~]# openssl dsaparam -out dsaparam.pem 1024
[[email protected] ~]# openssl gendsa -out privkey.pem dsaparam.pem
生成公鑰
[[email protected] ~]# openssl dsa -in privkey.pem -out pubkey.pem -pubout
[[email protected] ~]# rm -fr dsaparam.pem
# rm -fr == rm -rf == rm -r -f沒區別。
使用私鑰簽名
[[email protected] ~]# echo -n "123456" | openssl dgst -dss1 -sign privkey.pem > sign.result
使用公鑰驗證
[[email protected] ~]# echo -n "123456" | openssl dgst -dss1 -verify pubkey.pem -signature sign.result
爬蟲入門基礎篇
|
資料格式 |
描述 |
設計目標 |
|
XML |
Extensible Markup Language (可擴充套件標記語言) |
被設計為傳輸和儲存資料,其焦點是資料的內容 |
|
HTML |
HyperText Markup Language(超文字標記語言) |
顯示資料以及如何更好顯示資料 |
|
HTML DOM |
HTML Document Object Model(文件物件模型) |
通過 JavaScript,您可以重構整個HTML文件。您可以新增、移除、改變或重排頁面上的專案。要改變頁面的某個東西,JavaScript就需要對HTML文件中所有元素進行訪問的入口。 |
XML 示例
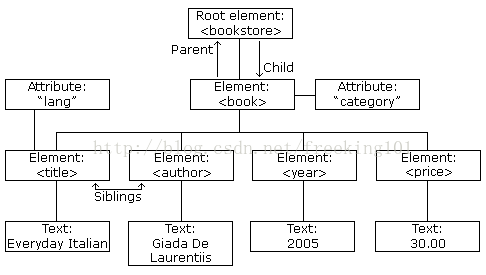
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>XML DOM 定義訪問和操作XML文件的標準方法。 DOM 將 XML 文件作為一個樹形結構,而樹葉被定義為節點。
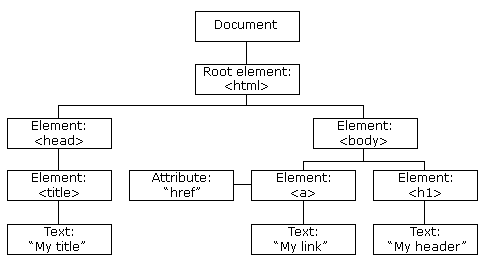
HTML DOM 示例
HTML DOM 定義了訪問和操作 HTML 文件的標準方法。 DOM 以樹結構表達 HTML 文件。
頁面解析之資料提取
一般來講對我們而言,需要抓取的是某個網站或者某個應用的內容,提取有用的價值,內容一般分為兩部分,非結構化的文字,或結構化的文字。
結構化的資料:JSON、XML
非結構化的資料:HTML文字(包含JavaScript程式碼)
HTML文字(包含JavaScript程式碼)是最常見的資料格式,理應屬於結構化的文字組織,但因為一般我們需要的關鍵資訊並非直接可以得到,需要進行對HTML的解析查詢,甚至一些字串操作才能得到,所以還是歸類於非結構化的資料處理中。
把網頁比作一個人,那麼HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。
常見解析方式如下:XPath、CSS選擇器、正則表示式。
一段文字
例如一篇文章,或者一句話,我們的初衷是提取有效資訊,所以如果是滯後處理,可以直接儲存,如果是需要實時提取有用資訊,常見的處理方式如下:
分詞 根據抓取的網站型別,使用不同詞庫,進行基本的分詞,然後變成詞頻統計,類似於向量的表示,詞為方向,詞頻為長度。
NLP 自然語言處理,進行語義分析,用結果表示,例如正負面等。
非結構化資料之XPath
XPath 語言:XPath(XML Path Language)是XML路徑語言,它是一種用來定位XML文件中某部分位置的語言。
將HTML轉換成XML文件之後,用XPath查詢HTML節點或元素
比如用“/”來作為上下層級間的分隔,第一個“/”表示文件的根節點(注意,不是指文件最外層的tag節點,而是指文件本身)。
比如對於一個HTML檔案來說,最外層的節點應該是"/html"。
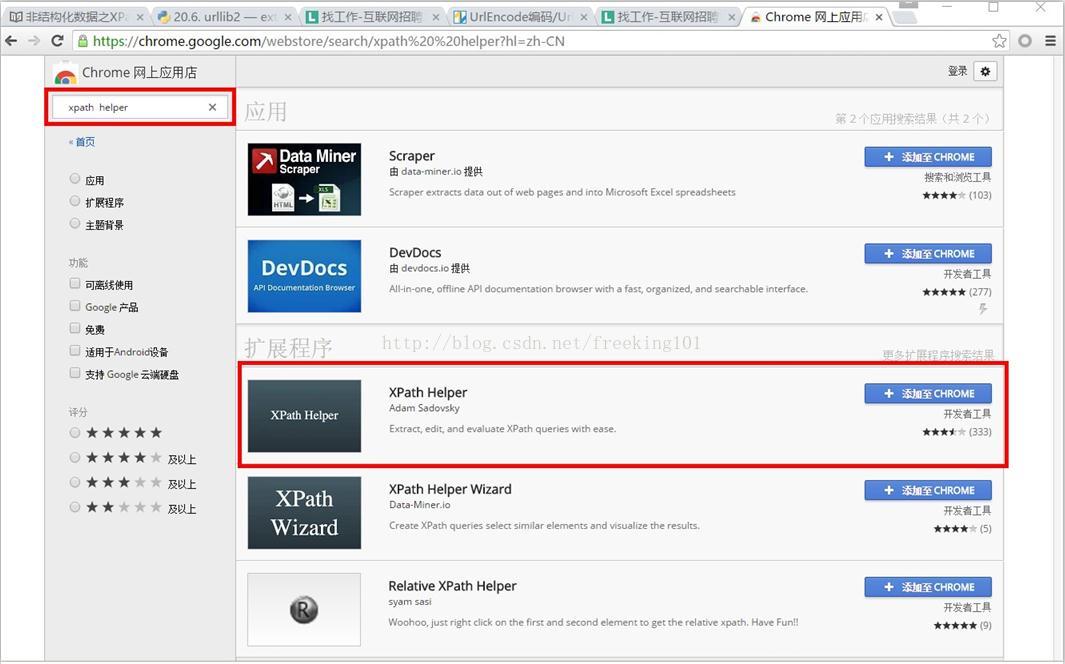
XPath開發工具:開源的XPath表示式編輯工具:XMLQuire(XML格式檔案可用)、chrome外掛 XPath Helper
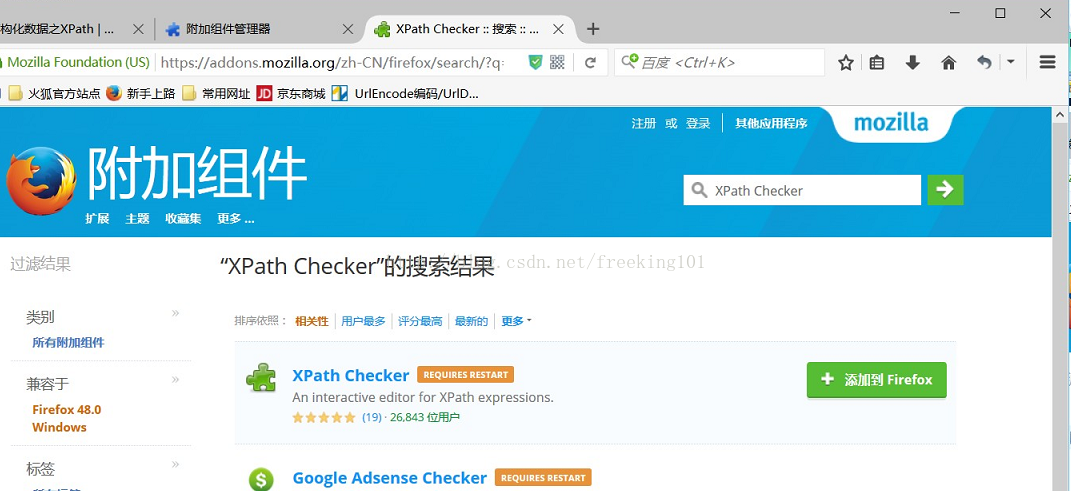
firefox外掛 XPath Checker
XPath語法
XPath 是一門在 XML 文件中查詢資訊的語言。
XPath 可用來在 XML 文件中對元素和屬性進行遍歷。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>選取節點 XPath 使用路徑表示式在 XML 文件中選取節點。節點是通過沿著路徑或者 step 來選取的。
下面列出了最有用的路徑表示式:
|
表示式 |
描述 |
|
/ |
從根節點選取。 |
|
nodename |
選取此節點的所有子節點。 |
|
// |
從當前節點 選擇 所有匹配文件中的節點 |
|
. |
選取當前節點。 |
|
.. |
選取當前節點的父節點。 |
|
@ |
選取屬性。 |
在下面的表格中,我們已列出了一些路徑表示式以及表示式的結果:
|
路徑表示式 |
結果 |
|
/bookstore |
選取根元素 bookstore。註釋:假如路徑起始於正斜槓( / ),則此路徑始終代表到某元素的絕對路徑! |
|
bookstore |
選取 bookstore 元素的所有子節點。預設從根節點選取 |
|
bookstore/book |
選取屬於 bookstore 的子元素的所有 book 元素。 |
|
//book |
選取所有 book 子元素,而不管它們在文件中的位置。 |
|
//book/./title |
選取所有 book 子元素,從當前節點查詢title節點 |
|
//price/.. |
選取所有 book 子元素,從當前節點查詢父節點 |
|
bookstore//book |
選擇屬於 bookstore 元素的後代的所有 book 元素,而不管它們位於 bookstore 之下的什麼位置。 |
|
//@lang |
選取名為 lang 的所有屬性。 |
謂語條件(Predicates)
謂語用來查詢某個特定的資訊或者包含某個指定的值的節點。
所謂"謂語條件",就是對路徑表示式的附加條件
謂語是被嵌在方括號中,都寫在方括號"[]"中,表示對節點進行進一步的篩選。
在下面的表格中,我們列出了帶有謂語的一些路徑表示式,以及表示式的結果:
|
路徑表示式 |
結果 |
|
/bookstore/book[1] |
選取屬於 bookstore 子元素的第一個 book 元素。 |
|
/bookstore/book[last()] |
選取屬於 bookstore 子元素的最後一個 book 元素。 |
|
/bookstore/book[last()-1] |
選取屬於 bookstore 子元素的倒數第二個 book 元素。 |
|
/bookstore/book[position()<3] |
選取最前面的兩個屬於 bookstore 元素的子元素的 book 元素。 |
|
//title[@lang] |
選取所有擁有名為 lang 的屬性的 title 元素。 |
|
//title[@lang=’eng’] |
選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性。 |
|
//book[price] |
選取所有 book 元素,且被選中的book元素必須帶有price子元素 |
|
/bookstore/book[price>35.00] |
選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大於 35.00。 |
|
/bookstore/book[price>35.00]/title |
選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大於 35.00 |
選取未知節點:XPath 萬用字元可用來選取未知的 XML 元素。
|
萬用字元 |
描述 |
|
* |
匹配任何元素節點。 |
|
@* |
匹配任何屬性節點。 |
在下面的表格中,我們列出了