
hadoop 自帶示例wordcount 詳細執行步驟
因為機器學習,接觸到了資料探勘;因為資料探勘,接觸到了大資料;因為大資料,接觸到了Hadoop。之前有過hadoop的簡單瞭解,但都是基於別人提供的hadoop來學習和使用,雖然也很好用 ,終究不如自己的使用起來方便 。經過這兩天參考大量網上的經驗,終於成功的搭建了自己的hadoop完全分散式環境。現在我把所有的安裝思路、安裝過程中的截圖以及對待錯誤的經驗總結出來,相信安裝這個思路去做,hadoop安裝就不再是一件困難的事。
我自己是搭建的完全分散式的hadoop,就涉及到了建立若干個虛擬機器並使它們能夠互通。所以我整個hadoop安裝能夠分為三個獨立的部分:1、linux 虛擬機器詳細搭建過程;2、hadoop完全分散式叢集安裝;3、hadoop 自帶示例wordcount 的具體執行步驟。本文介紹第三部分。(我們在做本節內容的基礎是Hadoop已經啟動)
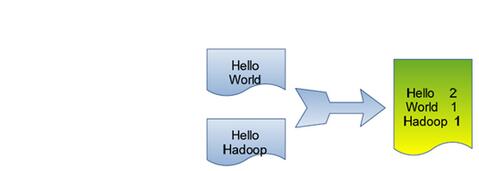
單詞計數是最簡單也是最能體現MapReduce思想的程式之一,可以稱為MapReduce版”Hello World”,該程式的完整程式碼可以在Hadoop安裝包的”src/examples”目錄下找到。單詞計數主要完成功能是:統計一系列文字檔案中每個單詞出現的次數,如下圖所示。
1.建立本地示例檔案
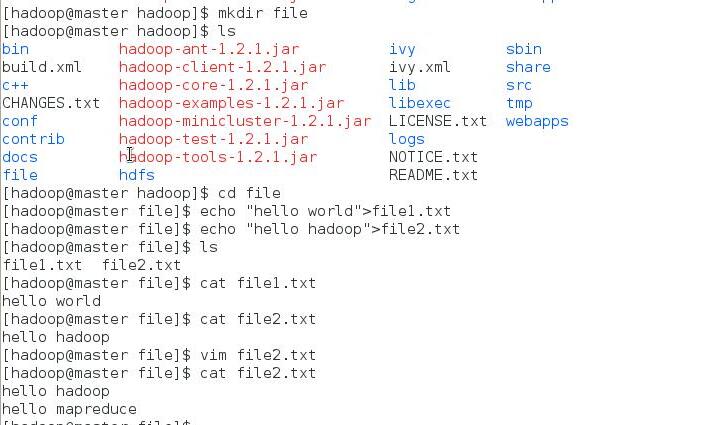
在”/usr/hadoop”目錄下建立資料夾”file”。
接著建立兩個文字檔案file1.txt和file2.txt,使file1.txt內容為”Hello World”,而file2.txt的內容為”Hello Hadoop”和“hello mapreduce”(兩行)。
2.在HDFS上建立輸入資料夾
bin/hadoop fs -mkdir hdfsinput意思是在HDFS遠端建立一個輸入目錄,我們以後的檔案需要上載到這個目錄裡面才能執行。
3.上傳本地file中檔案到叢集的hdfsinput目錄下
bin/hadoop fs -put /usr/haodop/file/file*.txt hdfsinput4.執行Hadoop 自帶示例wordcount
bin/hadoop jar /usr/hadoop/hadoop-examples-1.2.1.jar wordcount hdfsinput hdfsoutput以上三步的操作截圖如下

- 這裡的示例程式是1.2.1版本的,輸入命令時先查一下具體版本。地址就是/usr/hadoop/
- 再次執行時一定要先將前一次執行的輸出資料夾刪除
執行完之後的輸出結果:
檢視結果
bin/hadoop fs -ls hdfsoutput
從上圖中知道生成了三個檔案,我們的結果在”part-r-00000”中。
bin/hadoop fs -cat hdfsoutput/part-r-00000